Abstract
-
자연어 이해 Task는 textual entailment, question answering, semantic similarity, document classification 등으로 매우 다양함
-
하지만, 각 Task를 수행하는 모델을 만들기 위해 필요한 라벨이 있는 데이터가 부족
-
따라서 본 논문은 라벨링이 안되어 있는 방대한 텍스트를 사전 학습하고, 각 Task에 맞추어 최소한의 fine tuning 과정을 거치는 것만으로 특정 Task 하나만을 해결하기 위해 설계된 모델의 성능을 능가하는 GPT를 제시
1 Introduction
-
대부분의 딥러닝 모델은 방대한 양의 라벨링 데이터를 필요로 하기 때문에 라벨이 부족한 Task에서의 적용이 어려움
-
따라서 raw test를 통해 모델이 언어를 이해할 수 있도록 학습시켜 지도 학습에 대한 의존도를 줄일 수 있음
-
하지만 raw text에서 다양한 Task에 적용할 수 있는 text를 어떻게 학습시킬 것인가?, 이렇게 학습된 표현을 어떻게 각 task에 적용 가능하도록 튜닝할 것인가에 대한 구체적인 방안이 없음
-
본 논문에서는 Transformer의 Decoder 구조를 사용하여 첫 번째로 raw text를 통한 언어 모델을 학습하고, 해당 Task 수행을 위한 지도 학습을 추가로 시행하여 목표를 사용하여 이 매개변수를 목표 작업에 맞게 조정함
-
특히, Transformer 구조는 Attention 메커니즘을 통해 텍스트의 복잡한 패턴과 관계를 잘 파악하고, fine tuning 단계에서는 각 Task의 여러 input 구조를 하나의 시퀀스로 일괄적으로 학습하여 어디에서나 범용적으로 사용할 수 있음
3 Framework
- 1-Stage : 방대한 양의 text corpus를 고용량 언어 모델에 학습, 2-Stage : Task별 라벨 데이터를 사용하여 fine tuning 수행
3.1 Unsupervised pre-training
학습 방법
- : token, : corpus, : objective function, : context window, SGD적용
- Unsupervised token corpus 가 주어졌을 때, 이전 토큰까지의 corpus 에 대해 현재 토큰 가 corpus에서 나올 확률을 최대화
모델 구조
- Multi layer Transformer Decoder를 언어 모델로 사용
- U: context vector , : token embedding matrix, : positional embedding matrix, : num layer
- 최종 출력으로 각 토큰에 대한 확률 생성
3.2 Supervised fine-tuning
- Labeled dataset C가 Input token의 sequence 와 라벨 로 구성되어 있을 때, input sequence에 대한 사전 학습 모델 출력으로 를 반환
- 로 정답 라벨 가 될 확률을 예측
- 1-Stage와 같이 라벨 y를 예측 확률을 최대화하는 목적함수 사용
- 또한, 보조 목표를 추가하여 학습 진행 (는 두 손실의 균형을 조정하는 가중치)
- ex) x = 미국, 대통령, 누구, ?, y = 오바마의 데이터에 대해서 의 토큰 마다 계산된 손실의 평균, 의 정답 토큰과의 비교로 계산된 손실을 합해서 역전파 수행
3.3 Task-specific input transformations
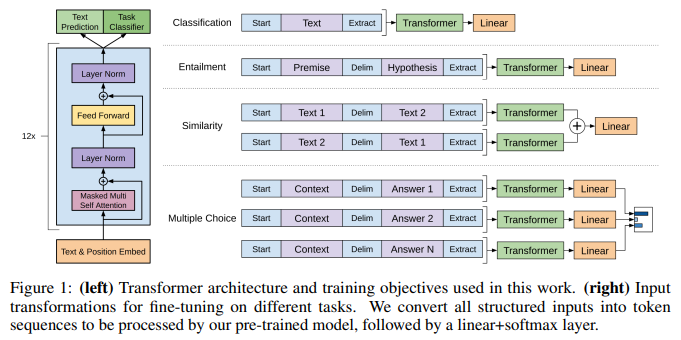
- GPT모델이 이해할 수 있도록 특수 토큰을 사용한 정렬된 시퀀스로 변환하여 모델 아키텍처를 유지한 채로 각 Task 수행
Textual Entailment
- 전제 𝑝와 가설 가 주어질 때
Similarity
- 두 문장 과 가 주어질 때
Question Answering and Commonsense Reasoning
- context , question , answers 가 주어질 때,
- 각 를 독립적으로 모델에 입력하여 점수를 계산하고, softmax로 정규화하여 최종 확률 분포를 생성
4 Experiments
4.1 Setup
-
7000권 이상의 미발표 도서로 구성된 BookCorpus Dataset과 문장이 랜덤으로 셔플되어 있는 Dataset을 사전학습 데이터로 사용
-
Transformer Decoder를 기반으로 layer 12, dimention 768, attention head 12 적용
-
사전학습에는 Adam optimizer, learning-rate 2.5e-4로 초기 설정 후 선형적인 증가, batch size 64, epoch 100, dropout 0.1, L2 정규화, 활성화 함수로 GELU사용
-
미세조정에는 사전학습의 설정을 그대로 재사용하고, 마지막 classification layer에는 learning rate 6.25e-5와 batch size 32를 적용, 대부분의 경우 epoch 3으로 마무리함
-
NLI, QA, Semantic Similarity, Classification 등의 다양한 Task에서 SOTA에 해당하는 성능 달성
5 Analysis
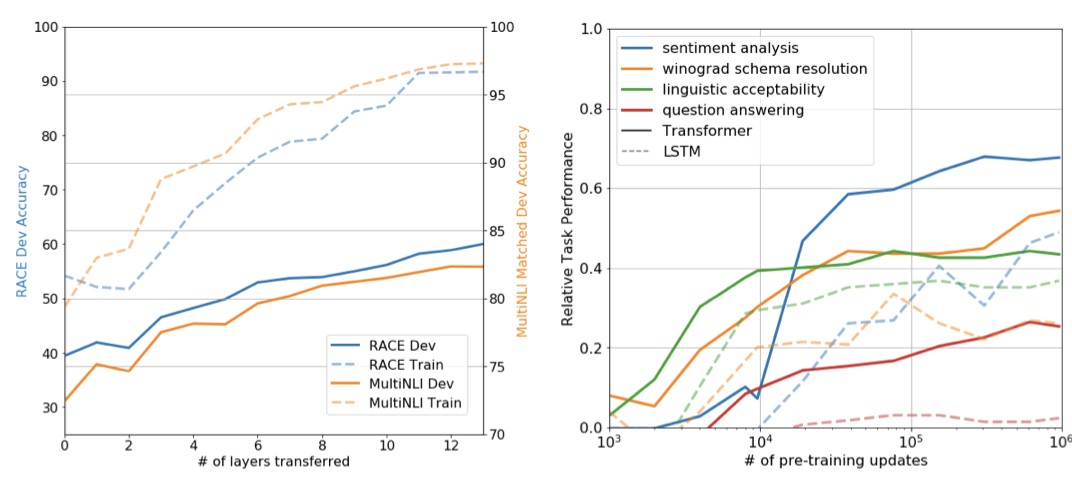
- 전이된 layer의 수가 늘어날 수록 성능이 향상되며, 학습률이 선형적으로 증가하면서 성능도 높아짐 => 비지도 사전학습은 다양한 NLP Task를 해결하기 위해 도움을 줌
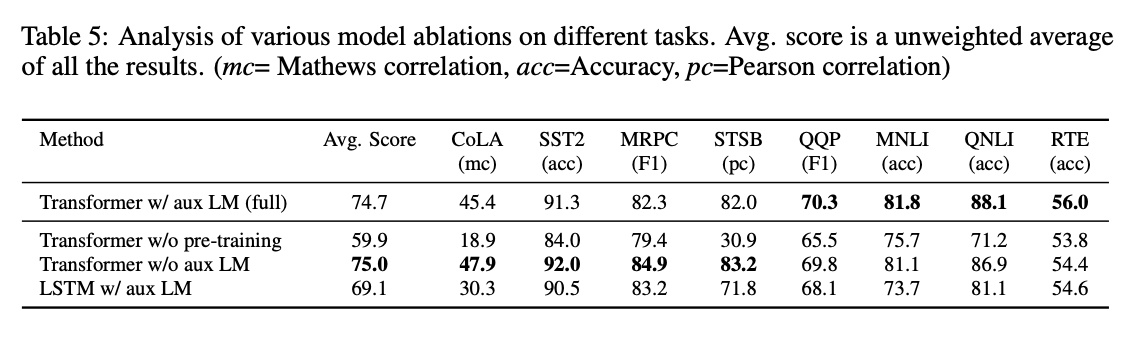
- 파인 튜닝 과정에서 MLM 없이 단독으로 NLP Task 학습 쌍 데이터셋으로 학습하는 경우, 동일 layer에서 LSTM을 사용하는 경우, 사전 학습 없이 바로 Task를 학습하는 경우보다 본 논문에서 제안한 방법의 성능이 대부분 월등했음
소감
GPT-1은 Transformer Decoder 구조를 기반으로 비지도 사전 학습과, 미세 조정 2-Stage 학습을 통해 광범위한 NLP Task에서 SOTA성능을 낸 모델이다. GPT-1보다 BERT 논문을 먼저 읽었던지라 처음에는 GPT의 본질은 생성인데 왜 BERT 논문에서 GPT의 단방향 아키텍처에 대한 지적을 하며 양방향 아키텍처의 우월성을 강조하는지 의아했었다. 하지만, 처음에 발표된 GPT-1은 BERT와 마찬가지로 형태가 정해진 NLP Task를 잘 판단하는 것에 초점을 두었기에 이제서야 이해가 된다. 물론 현재의 BERT와 GPT는 임베딩과 생성의 기능으로서 완전히 역할이 갈렸지만, 이 당시에는 두 아키텍처의 목표가 같았던 셈이다.
