[논문 리뷰] How to Make your LLMs use External Data More Wisely : Level2 Implicit Fact
RAG and Beyond
4 Implicit Fact Queries (L2)
4.1 Overview
-
암시적 사실에 대한 질의는 추론이나 논리적인 사고 능력이 필요하며, 답변을 도출하기 위해 필요한 정보가 여러 곳에 존재
-
여러 문서에서 정보를 수집하고 처리해야 하기 때문에 query를 여러 검색 작업으로 나누어, 각 결과를 종합하여 답변을 도출해야 함
-
통계, 분석, 수치 집계와 같은 질문에 답하기 위한 상식적인 추론 능력도 필요
따라서, Level-2의 query 는 아래와 같이 정의 됨
-
인 명시적 사실 query 집합이 있고, 각 query는 데이터셋 에서 직접 검색될 수 있어야 함
-
여기서 는 각 를 답하기 위해 필요한 data segment이고, 이 segment의 합집합이 에 대한 답을 도출하는 데 필요한 정보를 제공
-
Response generator(LLM inference) θ는 를 집계하고, 상식적 추론을 적용하여 최종 답변 를 도출해야 함
-
결국 Level2 query에 답변하기 위해서는 Level2 query를 단순한 Level1 수준으로 분할하고, 이들의 답을 종합하여 올바른 응답을 생성해야 함.
Level2 query 예시는 아래와 같음
- 샘플 크기가 1000 이상인 실험은 몇 개입니까? (실험 기록 컬렉션을 제공받았을 때)
- 가장 자주 언급된 증상 상위 3개는 무엇입니까? (의료 기록 컬렉션을 제공받았을 때)
- 회사 X와 회사 Y의 AI 전략의 차이는 무엇입니까? (회사 X와 Y에 대한 최신 뉴스 및 기사 시리즈를 제공받았을 때)
4.2 Challenges and Solutions
-
검색 횟수 조절 : 질문마다 질문에 답변하기 위해 context를 검색해야 하는 횟수가 다를 수밖에 없기 때문에 검색 횟수를 유동적으로 조절하는 것이 필요
-
추론과 검색의 유기적인 협력 : 추론은 무엇을 검색할지 판단하고, 검색된 정보를 통해 추론의 방향성이 정해지므로 이들 간의 적절한 조율이 필수적
Level2 수준의 문제를 해결하기 위한 대표적인 방법으로는 iterative RAG, RAG on graph/tree, and RAG with SQL가 있음
4.3 Iterative RAG
올바른 답변을 생성할 때까지 반복적으로 정보를 수집하거나 수정하는 방법
planning-based
- 올바른 답변을 이끌어내기 위해 추론과 검색을 반복하여 수행 (ReAct)
- Retrieval을 한번 하는 것이 아니라, CoT 과정마다 지금까지 generate된 결과와 retrieve한 내용을 바탕으로 retrieve를 진행 (IRCoT, RAT)
- 1과 2를 번갈아가며 수행하여 할루시네이션 최소화 및 근거 기반 답변 생성 (GenGround)
- 답변 추론 : LLM이 복잡한 질문을 더 단순한 단일 단계 질문(single-hop question)으로 분해하여 각 하위 질문에 대해 LLM의 내재된 지식 활용해 답변 생성
- 지식 근거화 : 생성된 질문-답변 쌍을 기반으로 Retriever. LLM은 이 검색된 문서를 활용하여 초기 답변의 정확성 검증 및 수정
Information Gap Filling Based
self-rag
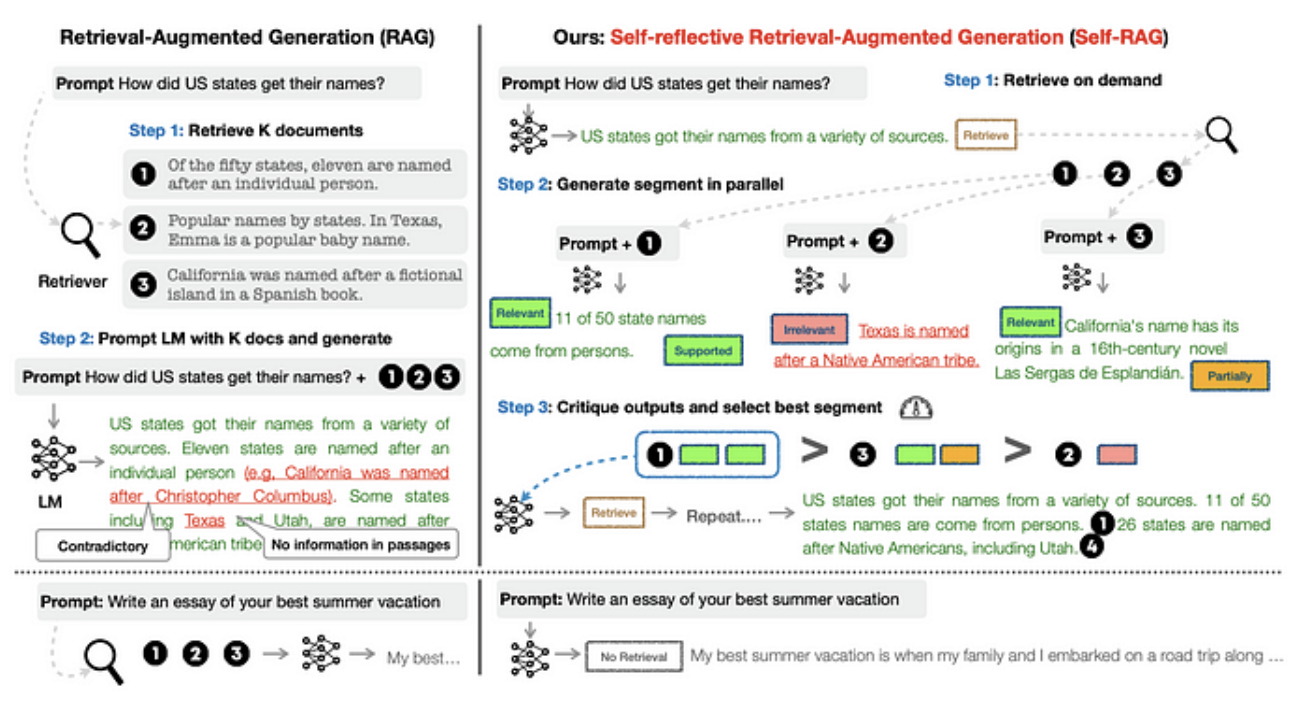
- 필요에 따른 검색 : 외부 지식 검색이 필요한 질문에는 [Retrieve] 토큰을 같이 생성
- 병렬 생성 : 검색된 문서가 질문에 답하는 데 유용한 정보인지 (relevant, irrelevant), 생성된 응답이 검색 결과에 근거하는지 (fully supported, partially supported, no support), 생성된 응답이 질문을 해결하는지 (1-5 스케일 척도) 평가
- 평가 및 선택 : 제일 최상의 콘텐츠를 응답으로 생성
(iterative RAG 방법론 중에서는 self-rag가 제일 체계적인 방법론으로 판단 됨)
4.4 Graph/ Tree Question Answering
암시적 사실 query에 답변하기 위해서는 여러 정보를 종합해야 하는데 그래프와 트리는 텍스트 간의 관계를 자연스럽게 표현하기 때문에 이러한 문제 해결에 적합
Traditional Knowledge Graph
Think-on-Graph
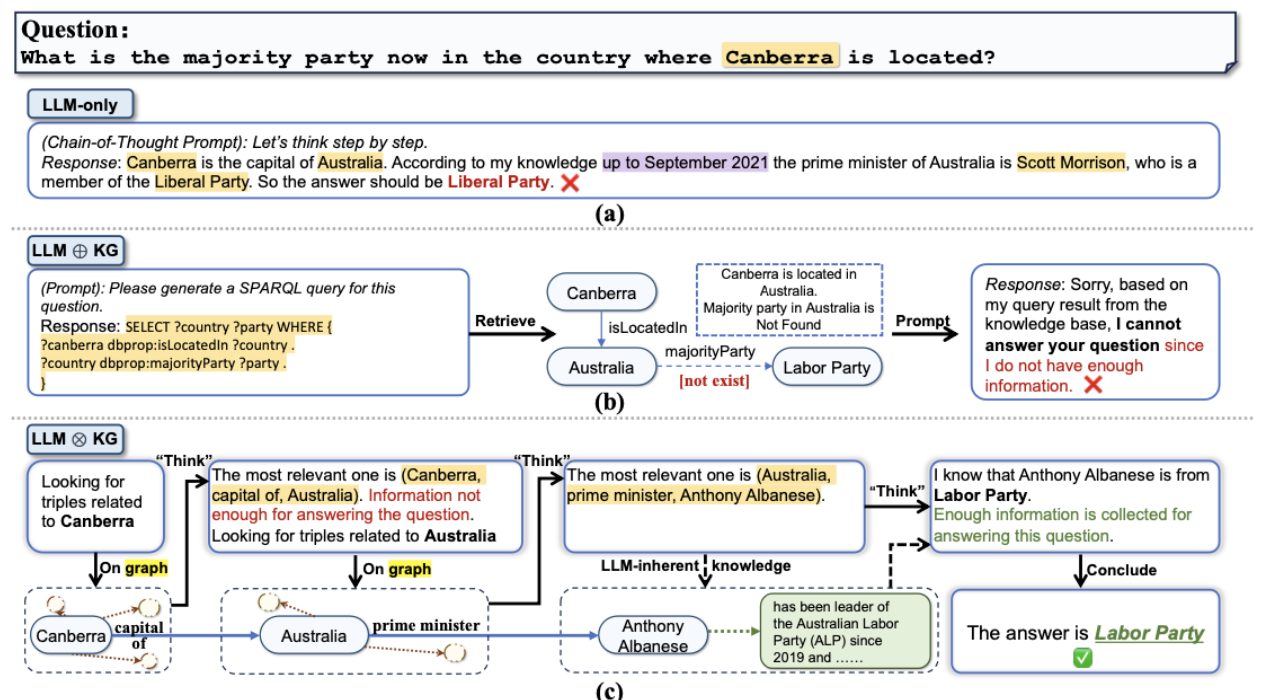
Think-on-Graph(ToG)는 크게 Search, Prune, Reasoning 세 가지 과정을 거쳐서 입력으로 들어온 프롬프트에 대한 정답을 생성
1) 입력으로 들어온 프롬프트에서 Search를 시작할 엔티티들을 추출
2) Search: Beam Search를 통해 관련성이 깊은 여러 엔티티들을 추출
3) Prune: 해당 엔티티들을 LLM에 입력시켜 가정 적합한 엔티티를 선택
4) Reasoning: 선택된 엔티티를 기반으로 입력 프롬프트의 정답을 생성할 수 있는지 LLM을 통해 평가하고 만약 불가능하다고 LLM이 판단하면 앞의 search와 prune, reasoning을 반복하여 Multi-path reasoning을 실행
이 경우, 각 iteration마다 총 N개의 경로를 뽑는다고 하고, 총 D번의 iteration을 반복해서 위의 알고리즘을 실행한다면 하나의 프롬프트에 정답을 출력하는데 2ND + D +1번 호출
Data Chunk Graph/ Tree
data chunk를 그래프와 트리 노드로 사용하고, 엣지를 통해 데이터 간 관계를 포착
- semantic, lexical 각각의 유사도가 비슷한 passage끼리 edge를 가지도록 KG구성 및 전용 알고리즘을 통해 retrieve (Knowledge-Graph-Prompting)
- chunking -> chuking sentence의 엔터티 추출 -> chunking sentence 요약 문장 생성 -> 요약 문장 기반 그래프 생성 -> 클러스터링으로 graph community별 요약 문장 생성 -> 질의 수준에 맞춘 검색 (GraphRAG)
4.5 Natural Language to SQL Queries
- 구조화된 데이터를 다룰 때는 test-to-SQL을 사용하는 것이 효과적
4.6 Discussion on Fact Queries
Whether to Use Fine-tuning
- 파인튜닝은 새로운 지식을 학습하기 위한 수단으로 적합하지 않음
- 전반적인 응답 생성 능력의 저하 발생, 할루시네이션 유발, fact sentence에 대한 기계적인 암기로 인해 문장을 살짝 변형하는 것만으로도 잘못된 답변 출력을 함
Whether to Separate Different Levels of Fact Queries
- 응답 전에 query가 어떤 수준에 있는지 판단하는 것이 중요
- 명시적 사실 query를 암시적 사실 query로 판단하면 자원 낭비, 그 반대의 경우에는 잘못된 답변 출력할 가능성이 커지기 때문
- 따라서 self-rag와 같이 검색된 정보가 답변의 정확성을 담보하는지 스스로 평가 가능하도록 모델을 훈련시킬 필요 있음
소감
LLM의 가장 큰 문제인 통제 가능성과 신뢰성을 해결하기 위해서 연구자들이 얼마나 고곤분투 했는지 엿볼 수 있었다.
하지만, LLM의 근본적인 문제를 해결하기 위해 몸부림친 결과에 비해 희생이 너무 크다... (무지막지한 자원 사용, 레이턴시, 데이터 구축)
머릿속에서 "이 모든 단점을 극복하고 LLM을 프로덕션에 적용할 수 있을까?"라는 생각이 스멀스멀 피어오른다.
언젠가 네이버 DEVIEW에서 엔지니어 분이 발표 말미에 했던 말이 계속 머릿속에 맴돈다.
"코딩의 신이 최고의 코드를 짜준다고 가정했을 때의 성능이 100이라고 한다면
70을 만드는 노력과 70에서 80으로 만드는 노력은 크게 다르지 않다.
90은 사실상 광기의 영역이다."
AI는 다른 어떤 분야보다 70-90의 결과가 사용자한테 주는 크리티컬함이 큰 분야라고 생각한다.
그렇기에 특히, 대기업은 석사 이상의 AI 전공자만 채용하는 것이라고 생각한다.
그리고 LLM은 이 수준까지 도달하기위해 투자해야할 자원의 크기가 너무 크다..
그래서 작은 기업은 힘들다...
