[논문 리뷰] How to Make your LLMs use External Data More Wisely : Level1 Explicit Facts
RAG and Beyond
- 본 논문은 survey로 그 내용이 매우 방대해 4 Chapter로 나눠서 작성하겠습니다.
Abstract
-
외부 데이터로 보강된 LLM은 domain-specific, hallucination, controllable 측면에서 놀라운 능력을 보여주어 RAG, fine-tuning을 통해 외부 데이터를 LLM에 통합하는 기술이 널리 활용되고 있음
-
하지만, 외부 데이터로 보강된 LLM을 만들기 위해서는 데이터 검색, 사용자 의도 파악, 복잡한 작업에 대해서 추론 능력 활용 등 넘어야 할 산이 많음
-
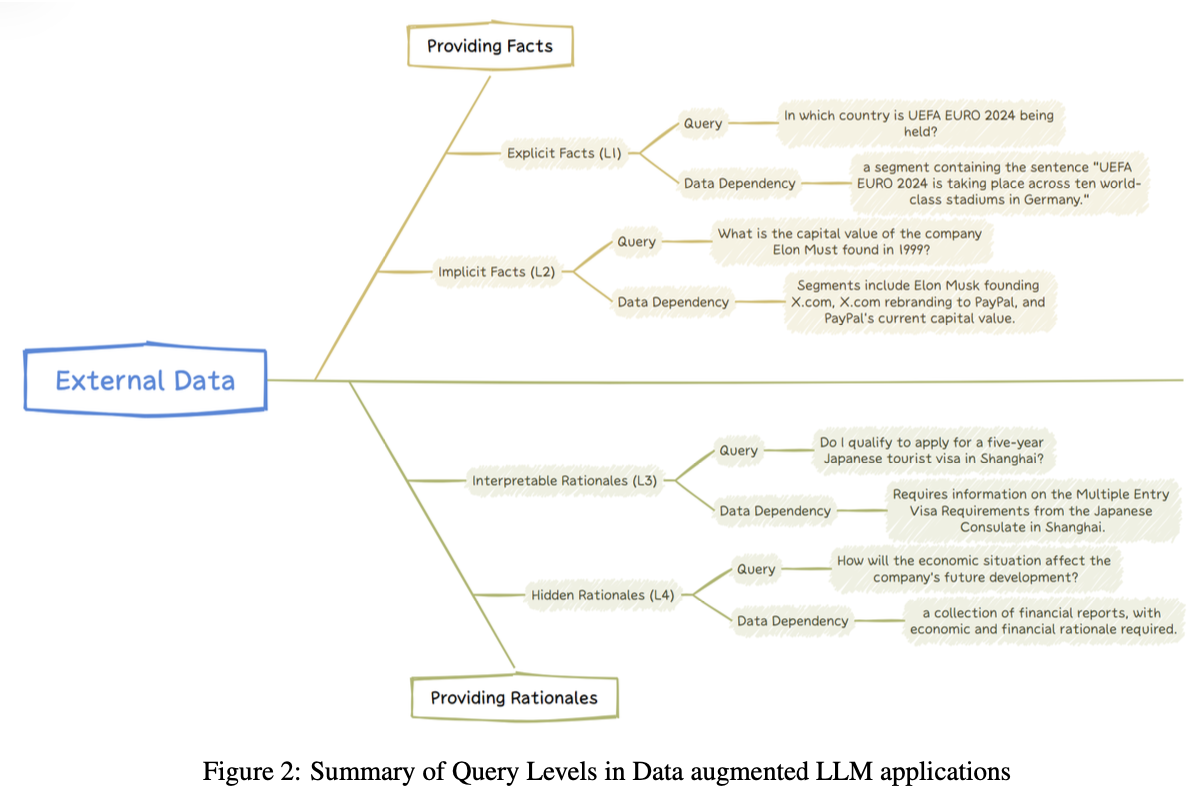
본 논문에서는 RAG가 처리하는 query의 종류를 명시적 사실 query, 암시적 사실 query, 해석 근거 query, 숨겨진 근거 query 4가지로 분류하여 각 task를 해결하기 위한 핵심적인 문제와 기술을 알려줄 것임
-
또한 외부 데이터를 LLM에 통합하는 3가지 방법 (context, finetuning, sLM)의 장단점 및 한계도 설명할 것임
1 Introduction
RAG, fine-tuning의 장점
- 전문성 및 시의성 향상 : 사용자 보유 데이터를 통해 복잡한 질문에 대해 정확한 답변을 제공하기 위한 데이터 업데이트와 가공이 가능
- 도메인 특화 : 도메인 특화 데이터를 활용하여 도메인 전문가와 근접한 능력을 보일 수 있음
- 환각 감소 : 실 데이터 기반 응답을 생성하기 때문에 환각 가능성을 크게 줄임
- 통제 가능성, 설명 가능성 향상 : 사용 데이터는 모델 예측에 reference로 활용될 수 있어 통제 가능성과 설명 가능성을 모두 향상시킴
RAG, fine-tuning의 한계
- but, 금융 LLM은 고차원 시계열 데이터를 이해하고 활용하는 능력이 필요하고, 헬스케어 분야는 의료 이미지나 시계열 기반의 의료 기록 이해가 필수적이기 때문에 이런 다양한 형태의 데이터를 LLM이 이해할 수 있도록 만드는 것은 매우 많은 자원이 필요
- 법률 및 수학 domain은 서로 다른 데이터 구조 간의 장거리 의존성을 이해시키는 측면에서 어려움 발생
- LLM은 본질적으로 해석 가능성은 낮고 불확실성이 높아 정확한 답변이 중요한 domain specific에서는 출력에 대한 신뢰성 확보가 매우 중요
2 Problem Definition
- 일반적으로 데이터 보강 LLM은 아래와 같은 공식을 따름
f : Q D → A
- 여기서 Q, A, D는 각각 사용자의 Query, 기대되는 Answer, 주어진 Data를 의미하며, f의 과제는 D를 기반으로 하여 Q를 통해 A를 도출
- 사전 학습된 지식만을 활용하는 LLM과 달리 데이터 보강 LLM은 제시된 Query에 정확하게 응답하기 위해 외부 데이터 D에 의존하는 특징을 가짐
2.1 Stratification of Queries
- 데이터 보강 LLM은 query의 요구사항과 복잡도에 따라 계층화할 수 있는데, 단순한 사실 검색부터 암시된 지식의 미묘한 해석까지 각 계층 수준에 맞춰서 LLM이 처리할 작업의 수준 또한 올라감. 아래에서는 계층을 4단계로 구분하고, 각 단계에서 요구되는 도전 과제와 필요 능력을 설명
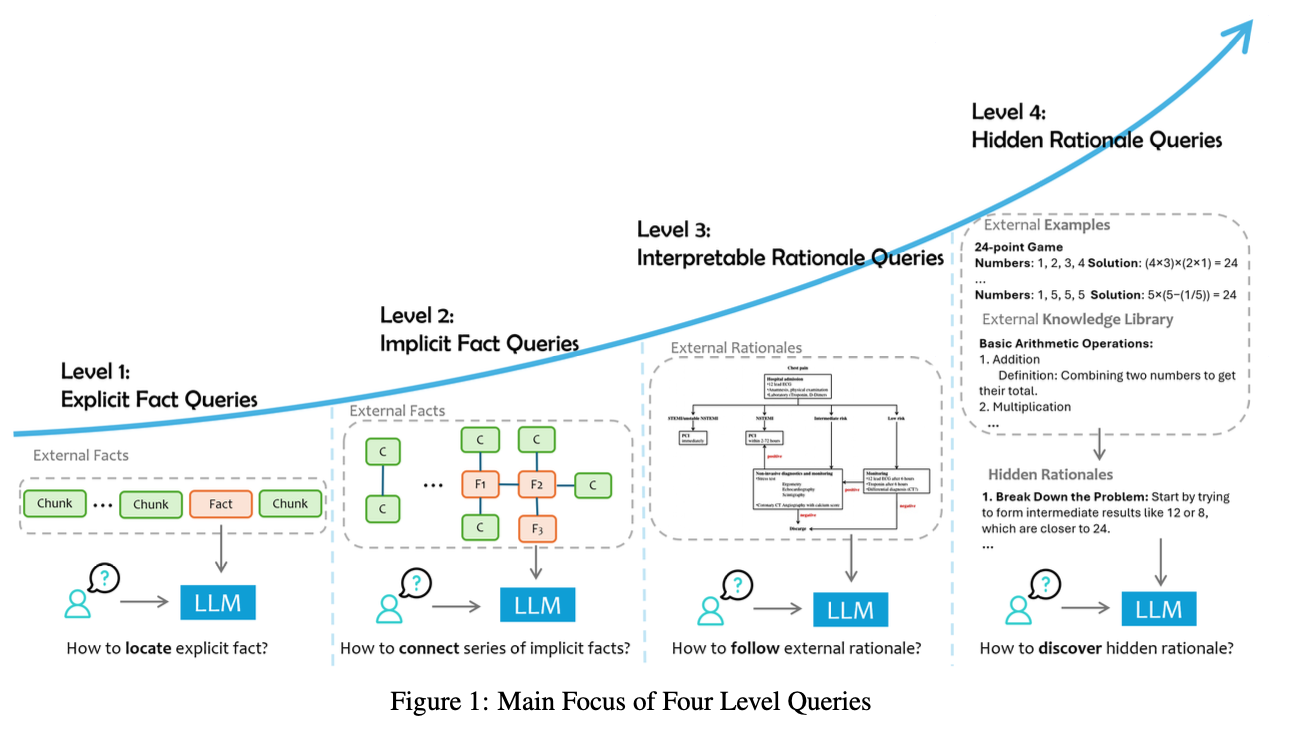
Level-1 Explicit Facts
- 주어진 데이터에 명시되어있는 사실을 직접적으로 질의하는 것으로 별도의 추론 없이 답변 가능하며, 가장 단순한 형태의 질의
- 여기서의 주요 과제는 질의와 관련된 정보를 찾아내는 것
- 예시:
Query: UEFA EURO 2024가 어느 나라에서 열리나요?
Data Dependency: “UEFA EURO 2024가 독일의 여러 세계적 수준 경기장에서 열리고 있다”는 문장 포함되어야 함
Level-2 Implicit Facts
- 데이터에 직접적으로 명시되어 있지 않은 암시적 사실을 질의하는 것으로 이런 질문에 답변하기 위해서는 기본적인 추론 과정이 필요할 수 있음
- 필요한 정보는 여러 곳에 있을 수 있고, 단순한 추론을 통해 통합해야 할 수도 있음
- 예시1 :
Query: 캔버라가 위치한 국가의 현재 다수당은 어디인가?
Data Dependency: 위 질문은 캔버라가 호주에 있다는 사실과, 현재 호주 다수당은 어디인가에 대한 정보를 각각 찾고 결합해야 답을 도출할 수 있음 - 예시2 :
Query: 일론 머스크가 1999년에 설립한 회사의 현재 기업 가치?
Data Dependency: 일론 머스크가 X.com을 설립하고, X.com이 PayPal로 리브랜딩되었으며, PayPal의 현재 기업 가치 정보를 추론해야 함
Level-3 Interpretable Rationales
- 단순 사실 파악을 넘어서 데이터의 도메인을 이해하고 적용할 수 있는 능력이 필요
- 예시1 : 제약 분야에서 LLM이 FDA 가이드라인 문서를 해석하여 특정 의약품 신청이 규제 요청을 충족하는지 평가하기
- 예시2 : 고객 지원 시나리오에서 사전에 정의된 workflow를 이해하고 정해진 workflow에 따라 사용자 문의 처리하기
- 외부에서 제시하는 근거를 그대로 수행하게 하여 정확한 응답을 출력하게 유도함으로써 기업의 서비스 기준 및 표준을 준수하도록 함
Level-4 Hidden Rationales
- 근거가 명시적으로 문서화되어 있지 않고, 외부 데이터에서 관찰되는 패턴을 추론하여 정답을 도출하는 능력이 필요
- 여기서 Hidden Rationales는 추론 과저으, 논리 관계, 외부 근거 식별 등의 복잡하고 작관적이지 못한 작업까지 포함됨
- 예시1 : 클라우드 운영팀이 과거에 처리한 수많은 사건이 있고, 각 사건은 고유한 상황과 해결 방안을 가지고 있을 때 LLM이 이러한 방대한 지식에서 추론을 통해 성공적인 전략과 의사결정 과정을 파악하기
- 예시2 : 소프트웨어 개발에서 이전 버그의 디버깅 이력을 바탕으로 중요한 암시적 통찰을 제공하기
- LLM은 숨겨진 근거들을 도출하여 정확한 답변을 생성하는데 그치지 않고, 외부 지식에서 축적된 드러나지 않은 전문성과 문제 해결 접근 방식(암묵지)을 반영한 답변을 생성할 수 있음
- Level1, 2는 사실 정보를 검색하는데 중점을 두고, Level3, 4는 LLM이 데이터 이면에 숨겨진 근거를 학습하고 적용하는 능력에 초점을 맞춤
3 Explicit Fact Queries(L1)
3.1.1 Data Dependency
- 명시적 사실을 묻는 질문의 결정적인 특징은 특정 외부 데이터에 대해 직접적으로 연관성을 가진다는 것.
3.1.2 Definition
- Data Dependency를 위와 같이 수식으로 설명하고 있는데 결국 핵심은 이 2가지를 말하고 싶은 것이다.
질문에 답변하기 위한 segment가 dataset에 포함되어야 한다.
query와 관련된 segment만 필요하다.
3.2 Challenges and Solutions
-
따라서 L1 수준의 query를 잘 응답하기 위해서는 질문과 관련된 segment를 잘 검색하는게 중요
-
그래서 보통 RAG를 사용하게 되는데, 이 RAG 활용 시스템을 구축하는 데 크게 3가지 어려움이 있음
1. 데이터 전처리가 어려움 : marchine-readable하지 못한 데이터, 멀티모달 데이터를 전처리 및 chunk하는 과정에서 데이터 고유의 문맥과 의미가 소실될 수 있음
2. 데이터 검색이 어려움 : 방대한 대규모 데이터셋에서 관련 데이터를 검색할 시 계산 비용, 검색 정확도 등의 문제가 발생하기 쉬움
3. 평가가 어려움 : 강건한 RAG 시스템을 개발하기 위해 데이터 검색 및 답변 품질을 평가하기 위한 지표 개발이 필수적
3.3.1 Data Processing Enhancement
Multi-modal Documents Parsing
- 첫 번째 접근 방법은 표, 이미지, 동영상을 텍스트 설명으로 변환하는 방법
- 두 번째 접근 방법은 멀티모달 데이터를 임베딩 벡터로 변환하고, 이 벡터를 LLM이 이해할 수 있도록 tuning하는 방법
(두 번째 접근 방식이 딱봐도 품이 많이 들고 골머리를 앓게 생겼다)
Chunking Optimization
- langchain, llamaindex에서 제공하는 여러 chunk방법론 사용
- query의 질문 수준에 맞는 segment를 찾을 수 있도록 tree형태로 data저장 후 검색
- 아예 vision 모델로 원본 문서 구조를 기준으로 chunking
3.3.2 Data Retrieval Enhancement
Indexing
Sparse Retrieval
- 키워드 기반 검색에 용이한 방법론으로 TF-IDF, BM25 알고리즘 사용
- 동의어를 구분하지 못한다는 단점을 극복하기 위해 KNN과 같은 유사성 기반 키워드 매칭 기법 사용
- 사전에 BERT로 segment의 모든 토큰 확률을 계산한 다음 모든 후보 segment에서 쿼리에 등장한 토큰만 앞에서 계산된 확률로 변환해서 전부 더해준 뒤 최종적인 상위 k개 문서 반환
Dense Retrieval
- BERT기반 text-encoder를 주로 사용
- 최근엔 LLM-based dense retrieval를 통해 검색 작업 성능을 크게 끌어올림(LLM2Vec)
Other
- Dense + Sparse를 결합한 hybrid query를 사용하거나 Colbert사용
- 검색할 data가 garbage인 경우 RAG가 한계가 있으니 LLM이 만들어낸 결과를 다음 답변에서 활용해서 개선해나가는 방법 등 여러 참신한 방법 사용
Query Document Alignment
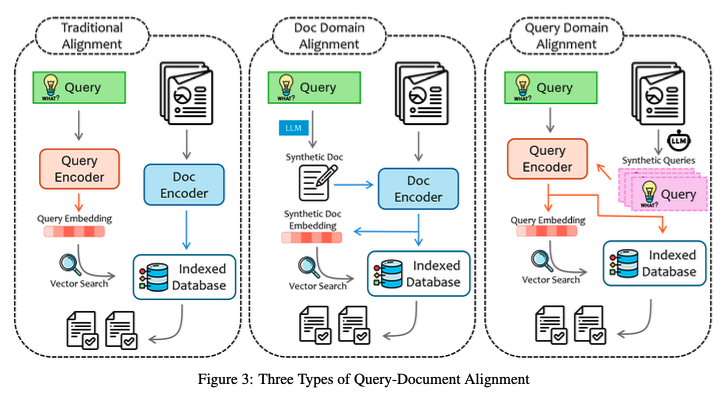
- sentence-bert 사용이 가장 일반적인 방법
- 사용자의 질문을 그대로 임베딩 하지 않고 질문과 관련된 가상의 문서를 만들라고 한 뒤 이 문서와 유사한 segment를 검색 (HyDE 기법)
- 경량 모델로 query에 대해 휴리스틱한 답변을 출력하여 검색이 꼭 필요한지 결정하고, 필요하면 query + 휴리스틱 답변 정보로 query writing한 최종 텍스트로 segment 검색 (SlimPLM)
Re-ranking and Correction
- 검색 문서가 long context인 경우, 문장 압축 진행(LLMLingua)
- 검색 문서가 별로인 경우 다른 전략을 수행하여 self-corrective 진행(CRAG)
Recursive Retrieval or Iterative Retrieval
- 모호한 query가 들어온 경우 query를 다각도로 해석하여 트리 구조로 확장해서 각 트리에 대해 외부 지식 검색 후 답변 통합 (ToC)
3.3.3 Response Generation Enhancement
- 검색된 정보가 응답 생성에 필요한 정보인지, 추가적인 외부 지식은 더 필요 없는지 판단해야하며, 검색된 지식과 모델 사전 지식의 충돌 등 여러 문제가 있음. 하지만, SFT 기반의 파인튜닝이 RAG 시스템의 성능을 향상시키는 효과적인 방법임.
- 특히, 검색된 segment가 query와 관련성이 없는 경우 잘못된 응답을 줄 확률이 매우 높아짐. 그래서 이런 노이즈 context를 잡아내는 능력도 중요
- retriever와 generator를 joint training하는 방법도 연구 중
