불균형 데이터란?
우리가 머신러닝 모델을 사용하는 이유는 결국 문제를 해결하기 위해서다.
병에 걸린 환자를 찾는 문제, 불량 제품을 찾는 문제, 신용 카드 사용 내역에서 이상 거래를 찾는 문제 등등...
이런 문제들의 공통점은 바로 데이터의 분포가 불균형하다는 것이다.
병의 양성 음성, 제품의 양품 불량품, 사용 내역의 정상 이상의 비율은 아마 후하게 쳐도 일반적으로 99:1의 분포를 가질 것이다.
데이터의 불균형으로 생기는 문제
이렇게 데이터의 분포가 불균형하면, 어떤 문제가 발생하냐??
머신러닝 모델의 정확도는 분명히 99%인데, 소수 클래스의 recall은 0이 된다.(recall이란? 실제로 1인 데이터를 1로 분류한 비율)
표면적으로는 정확도가 높아 자칫 모델의 성능이 높다고 판단할 수 있지만, 실제 소수 클래스를 모델은 하나도 예측하지 못하는 쓸모없는 모델인 것이다.
또한, 일반적으로 분류 모델을 최적화할 때 사용하는 loss는 cross-entropy함수를 사용한다.
이 함수는 실제 1인 클래스를 모델이 예측할 확률과 실제 0인 클래스를 모델이 예측할 확률을 더한 값이 최대가 되도록 한다. (실제 함수는 최소화 문제로 바꿔서 사용하므로 마지막에 음수를 곱한다.)
이는 모델의 성능을 높이기 위해 확률이 높은 다수 클래스에 훨씬 최적화된 학습을 하게 되어 과적합 문제가 발생하게 되고, 결국 다수 클래스에 편향된 결과가 나오게 된다.(성능 저하)
해결 방법
해결 방법으로는 크게 2가지 방법이 있는 데, 손실 함수를 다수 클래스에 편향되지 않도록 조정하는 방법과 데이터의 불균형 분포를 조정하는 방법이 있다.
여기서는 다수 클래스를 제거하는 언더샘플링과 소수 클래스를 늘리는 오버샘플링에 대해서 설명하겠다.
Undersampling
다수 클래스의 데이터를 제거하는 방법이다.
Random undersampling
랜덤 언더샘플링은 말 그대로 다수 클래스의 데이터를 무작위로 제거하는 방법이다.
장점 - 방법이 간단하며 효율적이다.
단점 - 무작위로 제거된 데이터가 모델의 분류 성능에 중요한 영향을 미치는 데이터일 수 있다. 또한, 무작위로 선택된 데이터에 따라 Decision Boundary가 조정될 수 있다.
Tomek links
소수 클래스 근처의 다수 클래스를 제거하여 Decision Boundary를 명확히 하는 방법이다.
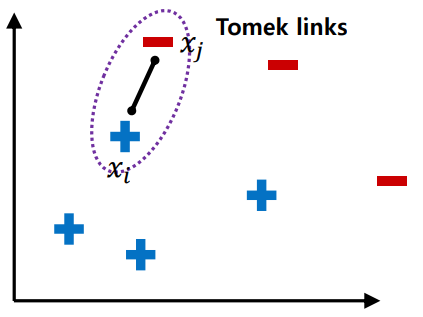
- 다수 클래스와 소수 클래스간 link를 형성한다.
- link사이에는 소수 클래스가 없어야하며, link사이의 다수 클래스를 모두 제거한다.
정의 : 𝑑(𝑥𝑖, 𝑥𝑘 ) < 𝑑(𝑥𝑖, 𝑥𝑗) 또는 𝑑(𝑥𝑗, 𝑥𝑘 ) < 𝑑(𝑥𝑖, 𝑥𝑗)가 되는 관측치 𝑥𝑘가 없는 경우. (𝑑(𝑥𝑖, 𝑥𝑗) 는 𝑥𝑖, 𝑥𝑗 사이의 거리)
장점 - 분류 경계선 형성을 방해하는 샘플을 제거할 수 있다.
단점 - 모든 데이터의 거리를 계산해야하기 때문에 계산비용이ㅣ 높다.
Condensed Nearest Neighbor Rule
tomek links가 decision boundary 근처의 데이터를 제거하는 방법이었다면, CNN Rule은 반대로 decision boundary와 멀리 떨어진 다수 클래스 데이터를 모두 제거하는 방법이다.
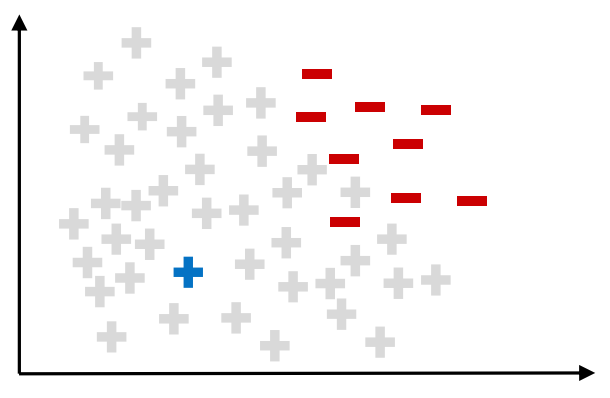
1. 다수 클래스 데이터 하나와 소수 클래스 전체를 뽑는다.
2. 뽑은 데이터를 1-NN알고리즘으로 통해 분류한다.
3. 알고리즘이 잘못 분류한 다수 클래스만 남기고 다 제거한다.
