Transformer 구조와 GPU 사용량
Attention
등장 배경 : input_seq가 길어지면 길어질 수록 output_seq의 정확도가 떨어지는 것을 보정하기위해 등장한 기법.
기본 아이디어 : decoder에서 output token을 예측하는 time step마다, encoder의 전체 입력 토큰을 다시 한번 참고. time step의 시점마다 예측해야할 토큰과 연관이 있는 입력 토큰을 좀 더 집중해서 본다.
Attention은 크게 Query, Key, Value로 바라볼 수 있다.
decoder는 한 시점을 예측할 때마다 input의 모든 입력 토큰을 참고한다.
예를 들어 Who are you?라는 입력값을 받아 답변을 생성한다고 하자. 그러면 I, am, a, student라는 각각의 단어를 생성하는 매 시점마다 input의 who, are, you, ? 각 단어의 attention score를 반영하여 예측을 할 때 도움이 되는 정보에 대해 가중치를 부여한다.
d model = 512 트랜스포머의 인코더와 디코더에서의 정해진 입력과 출력의 크기
num_layers = 6 인코더 디코더가 각각 몇개 층으로 구성되었는지
num_heads = 8 어텐션을 사용할 때 여러 개로 분할해서 어텐션을 수행할 병렬 개수
d ff = 2048 피드 포워드 신경망의 은닉층 크기
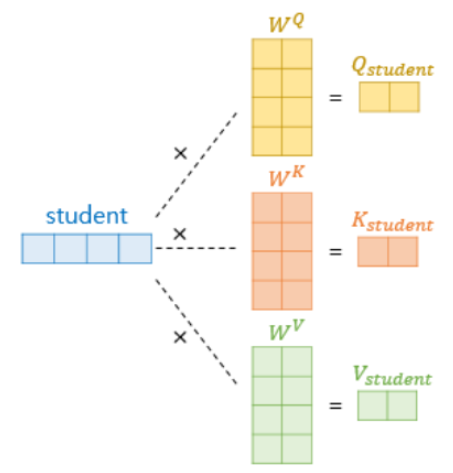
'student'토큰의 차원은 (1,512)차원.
이 토큰의 512차원 벡터에 대해 (d model, (d model / num_heads))차원(512,64)인 query, key, value의 가중치 행렬와 각각 곱해서 student의 q, k, v 행렬을 얻는다.
각 단어마다 각각의 q, k, v (1, 64)크기의 벡터를 얻는 것이다.
이를 이해하기 쉬운 문장으로 설명한다면,
"I am a boy" 라는 문장이 존재할 때 "I"에 대해서 {"I" : 쿼리}가 {"am","a","boy" : 키}와 어느정도의 {연관성 : 값}을 가지는가? 라는 Attention을 계산할수 있다.
출처: https://csshark.tistory.com/134 [컴퓨터하는 상어:티스토리]
이렇게 각 단어에 대해서 자기 자신의 단어 정보, 같이 입력받은 주변 단어 정보, 자기와 주변 단어와의 관련성 정보를 가진 q, k, v 행렬을 얻었다면 어텐션을 구할 수 있다. 이때 attension score는 Scaled dot-product attention을 사용하는데, query와 key를 내적한 값에서 (key값의 차원에서 루트 씌움)를 나눠준다.
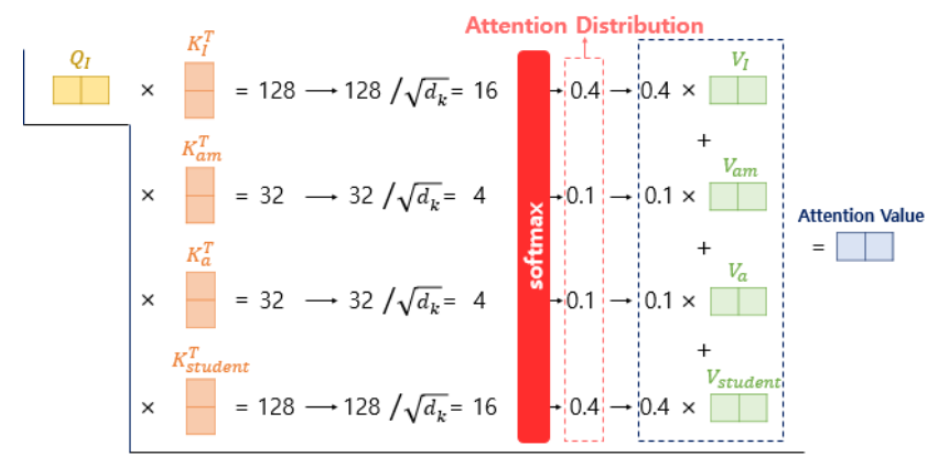
이렇게 각 단어의 q값과 모든 입력 단어를 비교해서 자기 단어와 입력 단어와의 관련성을 나타내는 어텐션 스코어를 구한 다음 소프트 맥스 함수로 표현된 Attention distribution 스칼라 값과 value 벡터와 곱한다. 그럼 value 벡터에 관련성에 따른 가중치가 반영되는 것이다.
Transformer는 위와 같은 연산을 행렬 연산을 통해 빠른 계산 시간을 보장하는데, 각 단어 벡터마다 일일이 가중치 행렬을 곱하지 않고 문장 행렬에 가중치 행렬을 곱해서 q, k, v행렬을 구한다.
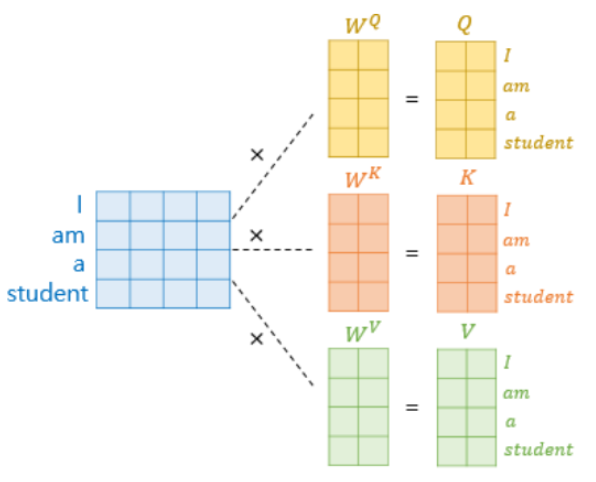
I, am, a, student라는 문장 정보가 담긴 (4, 512)행렬과 각 문장 단어의 q, k, v의 가중치 행렬 (512, 64)와의 곱으로 문장 각 단어의 q, k, v 정보가 담긴 (4, 64)행렬을 얻을 수 있다.
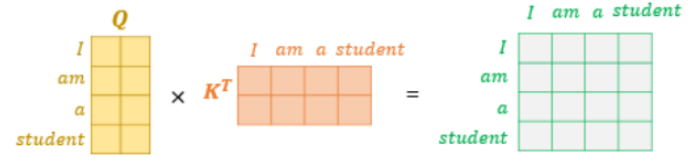
그리고 q와 k를 q^Tk 내적한 다음 로 나누어 최종적으로 스케일링이 적용된 (4,4)차원의 어텐션 스코어 값 정보가 담긴 행렬을 구할 수 있다.
이 어텐션 행렬에 소프트맥스 함수를 적용하여 각 단어에 대한 주변 단어의 어텐션 스코어의 확률 분포값을 얻게되고, 최종적으로 (4, 64)의 어텐션 행렬을 얻는다.
즉 attention값 행렬의 크기는 (seq_len, )가 된다.
여기서, 의 차원은 Transformer 구조에서는 /num_heads이므로 64가 된다.
토큰의 수에 제곱에 비례해서 사용 메모리가 늘어나는 이유 역시 한 토큰 마다 모든 입력 토큰의 어텐션을 구해야하기 때문이다.
ex) 토큰이 10개면 각 토큰에 대해 10개의 어텐션 구해야 하니 10^2이 된다.
Multi-head Attention
위에서 수행한 어텐션은 512차원의 단어 벡터를 64차원으로 압축해서 어텐션을 수행했다. 어텐션을 하나만 쓰지 않고, 8개의 어텐션을 병렬로 여러 개 수행하기 위함이다. 병렬 어텐션의 효과는 토큰 간의 연관성을 각기 다른 관점으로 바라보기 때문에 보다 합리적으로 토큰 간 연관성을 뽑아낼 수 있다는 것이다.
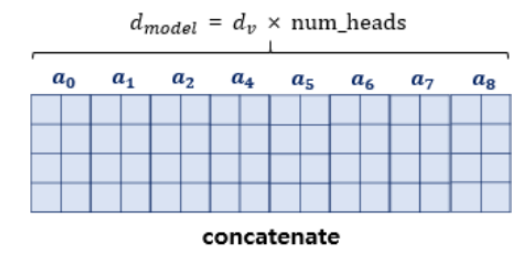
8개의 어텐션을 구해서 모두 cancatenate하면 어텐션 헤드 행렬의 크기는 (seq_len, d model)이 된다. 그리고 이 결과물과 같은 크기의 가중치 행렬을 곱해서 multi-head attention의 최종 결과물이 나온다.
처음 트랜스포머의 입력 차원이었던 (4, 512)와 크기가 같다.
FFNN
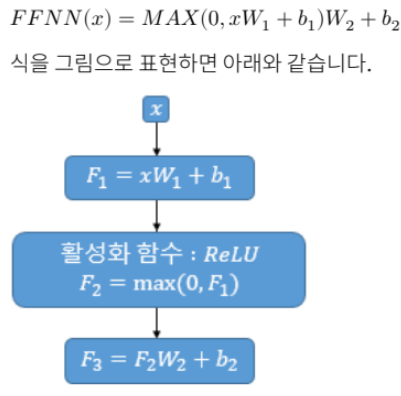
그 다음 구해진 멀티 헤드 어텐션 값을 다시 인공신경망 dense층으로 넣어주는데, 이유는 어텐션이 결국 입력 토큰의 가중 합계이며 이 출력에 직접 적용되는 비선형 변환은 없다. FFNN을 통해 이를 실행하면 비선형성이 도입되어 모델이 더 복잡한 패턴과 표현을 학습할 수 있다. 또한, 각 단어의 특징을 추출할 수 있다.
