[Data] Data Warehouse vs Data Lake
Data Warehouse
데이터 웨어하우스는 정보에 입각한 의사 결정을 내릴 수 있도록 분석 가능한 정보의 중앙 repository
트랜잭션 시스템, RDB 및 기타 소스의 데이터들이 데이터웨어하우스에 들어간다
데이터웨어하우스에 있는 데이터들을 Business Analyst나 Data Scientist 와 같은 사람들이 BI(Business Inteligence)나 SQL 등을 이용해서 데이터에 액세스 한다
하단 티어 즉 최하위에 있는 부분은 Data 부분인 위에서 말했던 트랜잭션 시스템, RDB 등을 비롯한 데이터들이고 이것들이 ETL(Extract Transform Load) 과정을 거쳐서 Data Warehouse에 적재가 된다
중간 티어 OLAP Server는 데이터에 액세스하고 분석하는데 사용되는 분석엔진들이다
여기서 OLAP란 Online Analytical Processing 을 말한다
상위 티어는 사용자가 실제로 데이터를 분석하고 마이닝을 하고 또 보고할 때 사용하게 되는 frontend가 존재하는 티어다
이렇게 이루어진 데이터 웨어하우스는 데이터를 정수, 데이터 필드 또는 문자열과 같은 레이아웃 및 유형들을 설명하는 스키마로 구성함으로써 동작하게 된다
즉 ETL, 데이터를 추출해서 변환해서 스키마에 적재해두는 것이다
그래서 이렇게 데이터를 구성하여 데이터 웨어하우스를 갖추었을 때 우리는
- 더 나은 의사결정
- 여러 소스로부터의 데이터 통합
- 데이터의 품질, 일관성 및 정확성
- 인텔리전스 기록
- 분석 처리프로세스를 트랜잭션 데이터베이스로부터 분리하여 두 시스템의 성능 향상을 도모
+) 원천 시스템 데이터 중 정보 분석의 가치가 있는 정보를 데이터 주제별로 분류하고, 분석 목적 별 데이터 마트를 생성한 뒤, OLAP tool 또는 SQL을 이용하여 최종 정보를 이용자들이 활용하게 된다.
여러 시스템의 정보를 통합하여 정보 분석을 할 수 있고, 분석 목적 별 데이터 마트를 생성하여 동일한 데이터에 대한 다중 액세스를 제거할 수 있으며, 운영 시스템의 부하를 경감시키고, 시스템을 읽기 최적화 시스템으로 적용할 수가 있다.
시계열 데이터를 관리하여 추이 분석이 가능하고, 비 IT 인력도 데이터 분석을 할 수 있다.
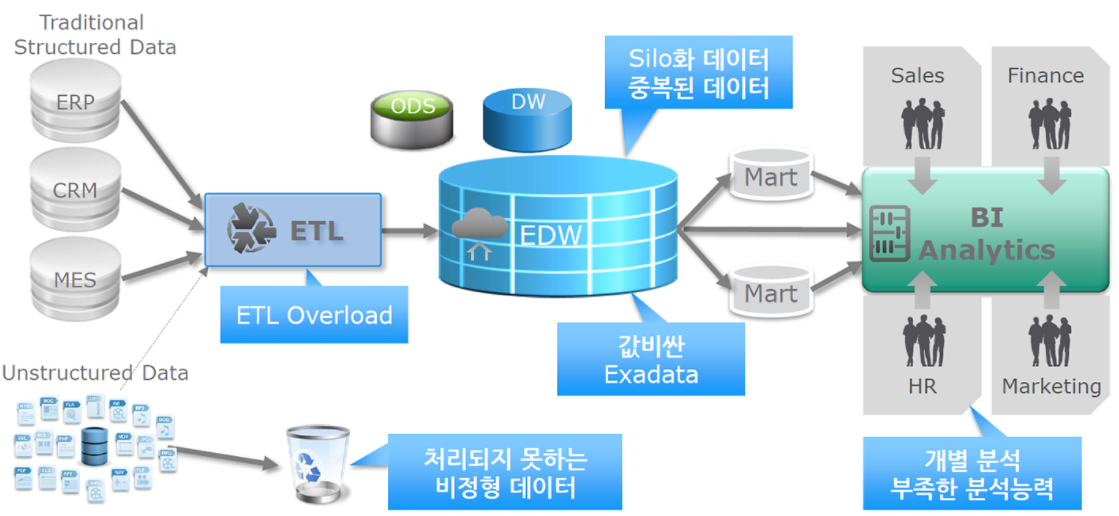
원천 시스템에서 데이터 웨어하우스에 이관하는 것은 매우 오랜 시간이 소요되고, 다양한 소스 시스템의 정보를 통합하기 때문에 인프라 증설이 주기적으로 이루어져 운영 비용이 상대적으로 많이 발생하고 있다는 한게점을 가지고 있다.
Data Lake
데이터 레이크는 최근 10년간 데이터 파이프라이닝의 중요한 구성 요소 중 하나를 설명하기 위해 등장한 용어이다. """데이터 레이크는 데이터 웨어하우스와는 달리 별도로 정형화나 정규화 등을 하지 않고 데이터를 있는 그대로 원시데이터 상태를 저장한다는 것이다"""
그러다보니 사용하는 쪽에서는 원시 데이터를 원하는 대로 가공하여 사용할 수 있다. 데이터 웨어하우스는 정형화된 데이터를 사용자가 약간의 변화를 통해서 동일하게 본다면, 데이터 레이크는 원시 데이터를 사용자가 원하는대로 가공하여 본다는 점이다.
또한 이런 데이터 레이크로 유입되는 데이터들은 자신의 출처와 시간같은 메타데이터가 존재하여야 한다.
또 데이터 레이크는 스키마가 존재하지 않으므로 이 원시 데이터를 어떻게 사용할지는 전적으로 사용자에게 달려있다.
데이터 레이크는 그 크기가 매우 커질 것이고 대부분의 저장소는 스키마가 없는 큰 규모의 구조를 지향하기 때문에 일반적으로 데이터 레이크를 구현을 할 때 Hadoop 과 HDFS(Hadoop Distributed File System)를 비롯한 에코시스템을 사용하는 것이다.
+) 데이터 웨어하우스의 정보분석 한계를 개선하기 위해 데이터 레이크라는 개념이 생겼는데,
대용량의 데이터들을 억지로 통합해 단일 형식으로 만드는 데이터 웨어하우스와는 다르게, 원래 형식으로 저장했다가 나중에 쉽게 분석할 수 있도록 하는 대규모 저장소라 할 수 있다.
데이터 레이크를 통한 데이터 분석은 무궁무진한 정보를 창출 할 수 있다.
데이터 레이크에서 빅데이터를 처리하는 방식은 DBMS의 병렬 처리와 유사하게 데이터를 독립적으로 작은 형식으로 나누고 다시 취합하는 기법을 적용하는데, 가장 보편화된 기술이 아파치 하둡과 같은 맵리듀스 방식의 분산 데이터 처리 프레임워크이다. 하둡의 구성요소 가운데 핵심 구성은 바로 저장과 처리(계산)이다. 하둡 분산 파일시스템(HDFS)를 통해 분산 서버에 저장하고, 맵리듀스를 통해 각각의 분산 서버에서 병렬로 처리한다.
데이터 레이크는 구조화된 타입의 데이터, 구조화 되지 않은 타입의 데이터와 상관없이 활용할 수가 있다. 이는 원천 상세 데이터를 가지고 패턴분석을 할 수 있어 데이터 웨어하우스에서 분석하지 못했던 영역까지 분석할 수 있다는 의미.
데이터 레이크 아키텍처는 분산 저장 구조이며 관계형 데이터베이스와 비교해서 매우 저렴한 저장매체를 이용할 수 있으므로 비용적인 측면에서는 상당한 큰 장점을 가지고 있다.

데이터 웨어하우스와 데이터 레이크의 차이점은 아래와 같다.
데이터
Data Warehouse : 트랜잭션 시스템, 운영 데이터베이스 및 사업부서 애플리케이션의 관계형 데이터
Data Lake : IoT 디바이스, 웹사이트, 모바일앱, 소셜 미디어 및 기업 애플리케이션의 비관계형 및 관계형 데이터
스키마
Data Warehouse : 데이터 웨어하우스 구현 전에 설계됨 (Schema on write)
Data Lake : 분석 시에 쓰여짐 (Schema on read)
가격/성능
Data Warehouse : 고비용의 스토리지를 사용하여 가장 빠른 결과를 얻음
Data Lake : 저비용의 스토리지를 사용하여 쿼리 결과의 속도가 빨라짐
데이터 품질
Data Warehouse : 신뢰할 수 있는 중앙 버전 역할을 하는 고도의 큐레이트된 데이터
Data Lake : 큐레이트될 수 있거나 될 수 없는 모든 데이터 (즉, 원시데이터)
분석
Data Warehouse : 배치 보고, BI 및 시각화
Data Lake : 기계 학습, 예측 분석, 데이터 디스커버리 및 프로파일링
+) 데이터 웨어하우스는 데이터가 저장되기 전에 구성되고 구조화되므로 비즈니스 분석가 및 기타 분석 전문가가 쉽게 분석할 수 있다.
저장된 데이터가 더 구조화되기 때문에 데이터 레이크의 유연성에 비해 데이터 웨어하우스가 다소 경직되고 민첩성이 떨어진다.
데이터 레이크는 저비용 오픈 소스 기술이 사용되는 경우가 많지만 데이터 웨어하우스의 경우는 빠른 쿼리에 최적화되어 있다.
보안성은 데이터 레이크에 비해 데이터 웨어하우스의 보안성은 더 높다
데이터 레이크는 내부 및 외부 소스의 데이터를 집계하고, 많은 다른 사용자에게 접근을 허용하여 보안 침해에 취약하다. 하지만 데이터 웨어하우스는 구조와 내향성이 강화되어 데이터 레이크보다 보안성이 강화된다.
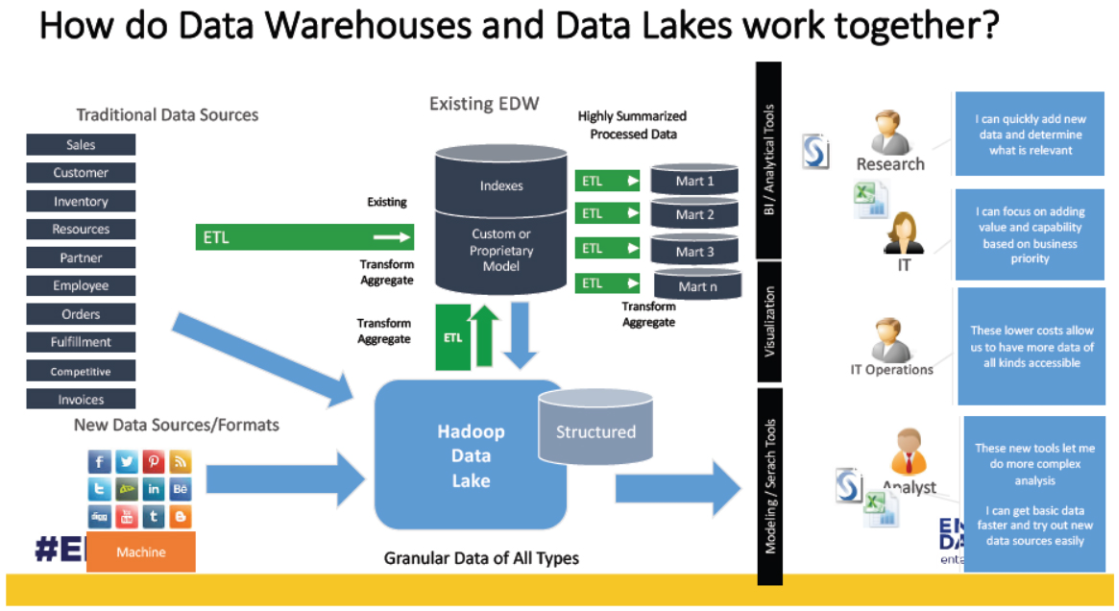
데이터 레이크 기반의 데이터 분석을 좀 더 효과적으로 하기 위해, 기존의 데이터 웨어하우스와 데이터 레이크를 연계한 하이브리드 데이터 웨어하우스 개념이 도입,
데이터 웨어하우스의 정형 분석 정보를 데이터 레이크에 SQOOP을 이용하여 이관 후 데이터 레이크에서 분석하거나, 데이터 레이크의 분석 결과를 정형 데이터로 변환한 후 SQOOP을 통해 데이터 웨어하우스로 이관하여 데이터 웨어하우스 정보와 연계해 다양한 분석을 할 수 있다.