ICLR 2021.
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov et al.,
Google Research, Brain Team
10 Oct 2020
💡 Key Point
이미지 인식에서 CNN을 완전히 제거하고, 순수한 Transformer만으로도 좋은 성능을 낼 수 있을까?
1. Motivation
배경
- Transformer는 NLP 분야에서 표준 아키텍처로 자리 잡았지만, Vision 분야에서는 여전히 CNN 기반 구조가 주로 사용되고 있었다.
- 이후 self-attention을 CNN과 결합하거나, CNN의 특정 모듈을 attention으로 대체하는 연구들이 나오기도 하였는데..
- CNN + Attention을 결합한 하이브리드 구조 적용해보기
- CNN 백본은 유지 + Attention 모듈을 추가해보기
⇒ But, 이러한 시도도 여전히 CNN의 구조에 완전히 벗어나지는 못했다.
기존 Vision 모델에서 트랜스포머 사용의 한계
- 당시 이미지에 self-attention을 직접 적용하는 것은 ‘계산 비용 측면’에서 꽤 고민거리였다.
- 각 픽셀이 모든 다른 픽셀과 상호작용을 해야함으로, 픽셀 수 N에 대해 라는 계산 비용이 발생할 수 밖에 없었다.
- 이 문제를 해결하기 위해, '어텐션을 근사하는' 여러 연구들이 수행되기도 했다.
- Local attention: 각 픽셀이 주변 지역 내에서만 어텐션을 수행
- Sparse attention: 일부 위치만 선택적으로 연결해 전역 어텐션을 수행
- Axial / Block attention: 행 또는 열 방향으로 어텐션을 수행 / 블록 단위로 어텐션 수행
⇒ 이러한 특수한 어텐션 패턴도 결국 1) 구현이 복잡했고 2) GPU 같은 하드웨어에서 효율적으로 실행하기 어렵다는 한계에서 벗어나지 못했다.
2. Insight
1) ‘픽셀’ 단위로 바라보는 관점에서 ‘패치’단위로 바라보자
- 기존의 self-attention을 이미지에 직접 적용하려면 ‘픽셀 단위 토큰’을 사용해야 한다.
- 이럴 경우 픽셀 수가 매우 많기 때문에 계산량이 상당히 높아진다.
- ex) 224x224 이미지를 처리할 경우, 50000개 이상의 토큰이 생성된다..
- ViT는 이를 해결하기 위해 이미지를 ‘작은 패치’ 단위로 분할하는 방법을 사용한다.
- 이미지를 고정 크기 패치로 나누고
- 각 패치를 하나의 토큰처럼 취급한 뒤
- 이후 패치를 임베딩 벡터로 변환한다
⇒ 픽셀 단위에서 패치 단위로 바꿔 토큰 수를 크게 줄이고 이걸 트랜스포머 인코더의 입력 시퀀스로 사용해보자.
2) CNN vs ViT: Inductive Bias와 Tradeoff
CNN과 ViT는 Inductive Bias 관점에서 서로 다른 장단점을 가지며 성능 trade-off가 존재한다. 이러한 특성은 “ViT가 항상 CNN보다 우수한가?”라는 질문에 대한 중요한 관점을 제공한다.
CNN의 Inductive Bias란?
- Locality: 신경망이 입력 이미지의 작은 영역에 집중하며(가까운 픽셀들끼리 밀접하게 관련시켜) 특징을 추출하는 성질
- Translation equivalance: 입력 이미지의 객체가 어디에 있든, 신경망의 특징 추출 과정에서 동일한 방식으로 인식되고 처리되는 성질
Tradeoff: CNN vs ViT
- CNN: Locality와 Translation equivalance와 같은 ‘Inductive bias’덕분에, 비교적 적은 데이터에서도 이미지의 특징을 잘 학습하고 일반화하는 능력이 있다.
- ViT: 반면 ViT는 CNN에 비해 Inductive bias가 거의 없어 데이터가 부족하면 성능이 낮을 수 있지만, 트랜스포머는 지역적 관계뿐 아니라 비해 장거리적 관계를 더 잘 파악할 수 있으므로, 충분히 큰 데이터셋에서는 CNN과 동등하거나 더 높은 성능을 보여준다.
3. Method
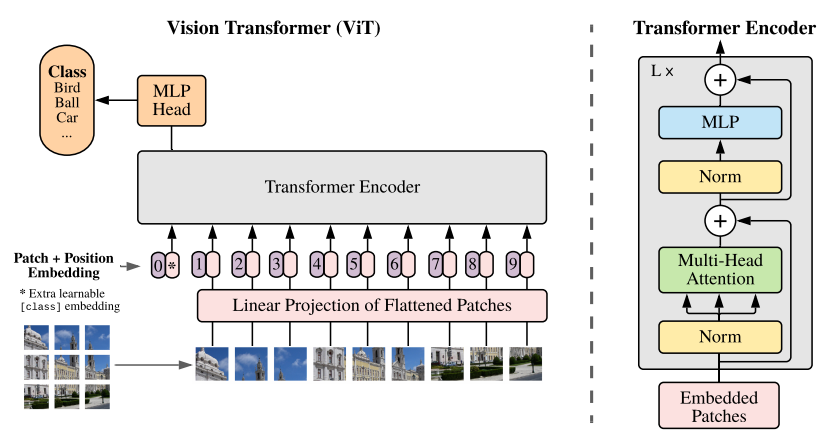
1) 패치 임베딩: 이미지를 토큰으로 변환
- 이미지를 패치 단위로 분할해 이를 트랜스포머 입력 토큰으로 사용한다
- → N개의 로 분할한다.
- 총 패치 개수
- 각각의 패치들은 flatten하여 하나의 벡터로 변환한다.
- 마지막으로 linear projection을 적용하여 차원의 임베딩 벡터로 변환한다.
- ex) 이미지 224 x 224 → 패치 16 x 16 + 토큰 196개
2) 위치 임베딩 + CLS 토큰 결합
- 트랜스포머는 토큰의 순서 정보를 알 수 없기 때문에 posion embedding을 추가했었다.
- ViT에서는 이와 비슷하게 학습 가능한 1D positional embedding을 사용하고,
- 이미지 전체의 정보를 요약하기 위해 [CLS] 토큰을 시퀀스의 앞에 추가한다. (이 [CLS] 토큰은 BERT에서 사용된 [CLS]와 동일한 역할)
- 최종 입력 시퀀스:
= [CLS] 토큰 + 패치 임베딩 시퀀스 + position 임베딩
3) Transformer 인코더
ViT에서는 기존 트랜스포머 인코더 구조를 거의 그대로 사용한다.
Multi-Head Self-Attention (MSA)
- 각 패치 토큰이 다른 모든 패치와 상호작용하며 이미지 전체의 관계를 학습한다.
- 이를 통해 1) 장거리 의존성과 2) 전역적인 이미지 구조를 효과적으로 모델링 할 수 있다.
MLP Block
- 각 토큰은 attention 이후 MLP(feed forward network)를 통과한다.
- MLP: Linear → GELU → Linear
- 각 블록에는 Layer Norm + Residual Connection이 적용된다.
⇒ 이후 이 트랜스포머 인코더 block은 여러 층으로 반복되는 형태로 구성된다.
4) MLP Head
- 트랜스포머 인코더의 출력 중에서 [CLS]토큰의 벡터를 사용해 최종 분류를 수행한다.
- 즉, CLS 토큰이 이미지 전체의 표현을 요약한 벡터 역할을 한다.
- 이 벡터는 마지막으로 MLP Head를 통과해 이미지의 클래스를 예측한다.
- (MLP 헤드는 일반적으로 linear layer + softmax로 구성)
4. Experiment Analysis
1) ViT의 성능 및 효율성
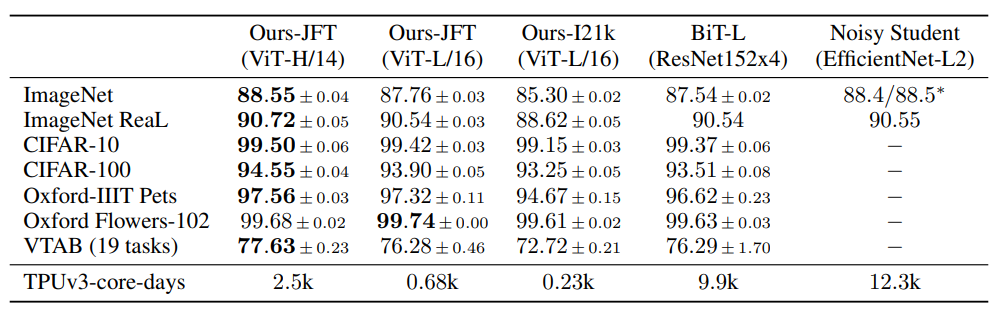
- ViT는 대규모 데이터(JFT-300M)로 pre-training 시 기존 CNN 기반 SOTA 모델을 능가한다.
- 계산 효율성
- 기존 SOTA 모델보다 적은 pre-training compute로 더 높은 성능을 달성함
- 동일 성능 달성 시 ResNet 대비 약 2~4배 적은 계산량
⇒ 대규모 데이터 환경에서는 Transformer 기반 모델이 CNN보다 더 효율적이고 강력한 표현 학습이 가능하다.
2) Pre-training 데이터 규모의 영향
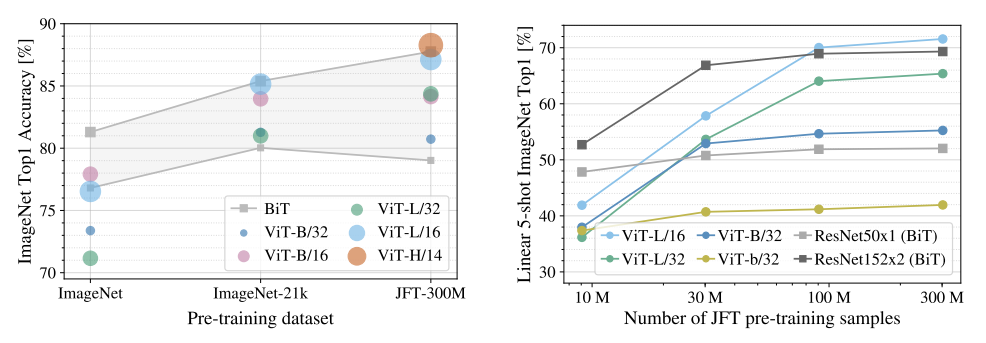
- 실험 데이터셋 ImageNet < ImageNet-21k < JFT-300M에 따라 성능을 비교하였다.
- 작은 데이터셋(ImageNet): ViT-Large가 ViT-Base보다 성능이 낮음 (overfitting 발생)
- 중간 규모(ImageNet-21k): 두 모델 성능 유사
- 대규모 데이터(JFT-300M): 큰 모델이 확실한 성능 이점
- 작은 데이터에서는 CNN(ResNet)이 ViT보다 우수하고, 데이터가 커질수록 ViT가 CNN을 추월한다.
⇒ CNN의 inductive bias는 작은 데이터에서 유리하지만, 데이터가 충분히 크면 ViT가 더 좋은 성능을 보인다.
3) Model Scaling 성능 분석
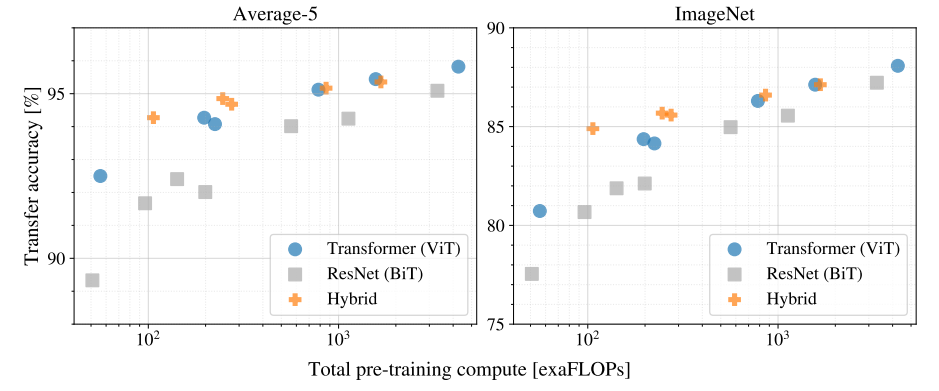
- JFT-300M 환경에서 모델 크기 vs 계산량 vs 성능을 비교하였다.
- 결과적으로 ViT가 가장 좋은 performance ↔ compute의 trade-off를 가진다.
- Hybrid 모델은 작은 모델에서는 약간 더 좋지만 큰 모델에서는 ViT와 성능 차이 거의 없다.
⇒ 모델 규모가 커질수록 순수한 Transformer 구조가 더 유리하다는 것을 보여준다.
5. Significance of Paper
1) CNN 기반의 Vision 모델을 트랜스포머로 확장
- 기존 CV 분야의 CNN 기반 구조에서 순수 트랜스포머 구조만으로 이미지 인식이 가능함을 보여줌
- 이미지를 패치 시퀀스로 변환해 NLP의 트랜스포머 방식을 그대로 적용하는 효과적인 구조를 제안함
- 복잡한 어텐션 변형 & CNN 결합 없이도 기존 SOTA CNN 모델보다 월등한 성능 달성
2) 대규모 학습 데이터에서의 강력한 성능
- CNN은 inductive bias 때문에 작은 데이터에서 유리하지만 ViT는 inductive bias가 적어도 대규모 데이터에서 더 높은 성능을 보임
- Vision 모델에서도 "데이터 규모 + 모델 스케일링"이 성능의 핵심 요소임을 보여줌
3) 이후 Vision Transformer 연구의 초석
- ViT 논문 이후 다양한 트랜스포머 기반 Vision 모델 연구가 진행되었음
- DeiT, Swin Transformer, PVT 등…
- 현재 CV 분야에서 classification, detection, segmentation 등 다양한 task에서 ViT 기반 모델이 핵심 아키텍처로 자리잡았다.
6. 헷갈리는 개념 정리
1. MLP Block (Linear → GELU → Linear)
- Transformer Encoder에서 Self-Attention 다음에 위치하는 Feed-Forward Network
- 구조:
Linear → GELU → Linear - 일반적인 차원 흐름:
D → 4D → Dex)768 → 3072 → 768 - 동작 과정
- 첫 Linear : feature 차원 확장 (표현력 증가)
- GELU : 비선형 변환
- 두 번째 Linear : 차원 축소
- 역할: Self-Attention이 토큰 간 관계를 학습한다면, MLP는 각 토큰의 feature 표현을 변환·강화하는 역할
2. LayerNorm vs BatchNorm
LayerNorm?
- 한 샘플 내부의 feature 벡터 기준으로 정규화: 각 벡터의 평균과 분산을 계산하여 정규화
- batch size 영향 없음
- sequence 모델에 적합
- Transformer에서 사용
BatchNorm?
- batch에 있는 여러 샘플 기준으로 정규화: 같은 feature 위치의 batch 평균 / 분산 사용
- CNN에서 효과적
- batch size 영향 있음
- 작은 batch에서 성능 저하 가능

grit