ICML 2021
Alec Radford, Jong Wook Kim, Chris Hallacy et al,.
OpenAI
26 Feb 2021
💡 Key Point
라벨링된 데이터 없이, 텍스트(자연어)만으로도 general-purpose한 비전 모델을 만들 수 있을까?
1. Traditional Vision Model vs CLIP
| 항목 | Traditional Vision Model | CLIP |
|---|---|---|
| 학습 방법 | - 사람이 만든 label: 고정된 클래스 - 새로운 클래스를 추가하려면 반드시 새 라벨링 데이터가 필요함 | - 웹에서 수집된 텍스트 전체로부터 학습 - 텍스트는 객체, 속성, 행동, 상황 등을 포함 - 모델의 학습 범위는 의미론적으로 넓고 유연함 |
| Task | - 각 이미지를 특정 클래스 중 하나로 예측 - 이미지 → 고정 label 매핑을 학습 - 한 번 학습하면 새로운 task로 확장 어려움 | - 이미지와 텍스트가 서로 맞는지 판단 - Contrastive Learning: positive pair는 가깝게, negative pair는 멀게 배치 - 비전 feature와 텍스트 feature를 동일 벡터 공간에 정렬 |
| Classifier | - 이미지 feature + 선형 분류기(linear layer) - 분류기는 학습 데이터에 맞춰 최적화된 고정 구조 - 새 클래스를 추가하려면 분류기 재학습 필요 | - Image Encoder + Text Encoder 구조 - 텍스트 문장을 벡터로 변환 (문장 자체가 weight 역할) - 모델 재학습 없이 텍스트만 바꿔 새로운 클래스 정의 가능 (zero-shot) |
| 일반화 | - 특정 데이터셋(ImageNet 등)에 최적화 - 분포가 바뀌면 성능 급락 - 데이터셋 고유 통계에 overfitting 경향 | - 기존 모델보다 넓은 도메인에서 강력함 - 자연 분포 변화(ImageNet-A 등)에 더 robust |
| 확장성 | - 라벨링 비용이 데이터·클래스 수에 비례 증가 - 인력·시간 비용 큼 → 대규모 확장 어려움 | - 웹의 방대한 이미지-텍스트 데이터 활용 가능 - 모델·데이터·개념 범위를 라벨링 없이 확장 가능 |
| 능력 | - 단일 태스크 중심 (이미지 분류 특화) - OCR, Action Recognition 등은 별도 모델 필요 | - OCR, 행동 인식, 지리적 추론 등 다양한 task 수행 가능 - 자연어 기반 zero-shot, multimodal 활용 가능 |
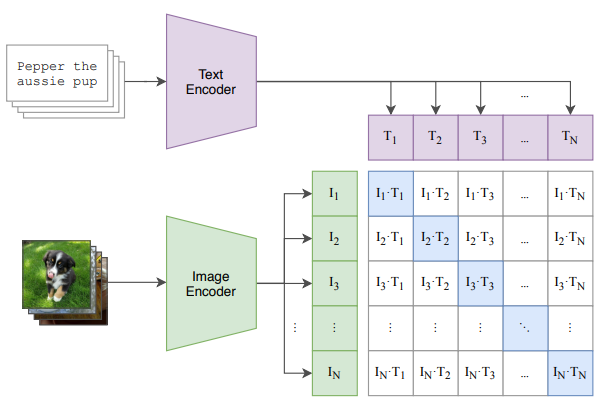
2. CLIP’s Mechanism (3-Step)
Image Encoder + Text Encoder를 통한 공통 임베딩 공간 생성
- ResNet / ViT 이미지 인코더로 feature 벡터() 생성
- Transformer 텍스트 인코더로 feature 벡터() 생성
- 두 feature를 멀티모달 임베딩 공간으로 보내는 linear transformation 진행
- 각 벡터를 길이 1이 되도록 L2-normalization 진행(코사인 유사도를 계산하기 좋게하기 위해)
Contrastive Loss: 이미지-텍스트 쌍 거리 학습
- 이미지 & 텍스트의 코사인 유사도로 구성된 NxN 행렬 생성
- 이미지 ↔ 텍스트의 양방향(두 번) cross entropy loss를 계산해 평균을 냄
- 정답 쌍(대각선)의 score는 높이고, 나머지 쌍(오답)의 score는 줄이도록 학습
Zero-shot에서 텍스트 자체가 클래스를 대신
- 학습이 끝난 후 zero-shot 예측을 수행하면 “A photo of a dog” 같은 이미지에 대한 텍스트가 생성
- 텍스트를 인코딩하면 그 자체가 classifier weight처럼 작동
3. Experiment Analysis
Visual N-Grams vs CLIP
- Visual N-Grams는 최초의 zero shot 이미지 분류 실험
- CLIP은 ImageNet에서 zero-shot 정확도를 대략 11% → 76%로 개선
- 수백만 ImageNet 라벨 없이도 supervised ResNet-50 수준을 달성
Zero-Shot Performance
- 16개의 Dataset에서 ResNet50보다 우수한 성능을 보여줌
- 특히 라벨 수가 매우 적은 STL10 같은 경우에도, training example 없이 SOTA 달성
- Zero-shot CLIP ≈ ResNet-50 4-shot classifier(자연어로 개념을 직접 정의 가능하기 때문)
- General한 분류에서는 성능이 좋지만, 전문화/복잡/추상적 task(의학, 위성 등)에서는 낮은 성능 보임
- 즉, 복잡한 과업에서의 zero-shot CLIP의 능력은 부족함(개선할 여지가 있다)
Robustness & Emergent Behavior
- ImageNet-A, R 등에서 기존 모델보다 robustness가 훨씬 강함 why?→ 특정 데이터셋에 의존하지 않는 multi-modal pre-training + zero-shot 평가 방식 때문에
- 기존 비전 모델에 비해 단일 모델로 광범위한 task를 학습함(OCR, 얼굴 감정 인식, 지리 위치 추론)
4. Significance of Paper
NLP의 pre-training 패러다임을 vision에 적용
- NLP의 웹 규모 자연어 기반 사전학습 방식을 vision에 성공적으로 적용한 논문
- 기존 ImageNet 중심의 라벨 기반 학습의 한계를 넘어섬(고정된 클래스, 라벨 비용)
- Vision에서도 범용성,확장성,도메인 일반화가 가능한 방향을 열어줌
텍스트 중심 학습이라는 패러다임을 제시
- 기존 방식: 이미지 → 특정 클래스, 단순 분류 구조
- CLIP 방식: 이미지 ↔ 텍스트의 대칭적 관계 학습
- 자연어가 단순 라벨이 아니라, 객체,속성,행동,상황을 모두 포함하는 의미 단위로 작용
- 텍스트 인코더의 출력이 classifier 그 자체가 되어 라벨 없이도 텍스트만으로 새로운 개념 정의 가능
Zero-shot learning의 시발점
- ImageNet을 단 한 번도 supervised로 학습하지 않았지만 높은(76%) zero-shot 성능 기록
- 새로운 클래스를 넘어서 완전히 새로운 데이터셋, task의 일반화를 실현했음
- Label 수집 없이 텍스트 프롬프트만으로 새로운 문제도 해결이 가능하다는 걸 보여준 논문
5. Questions
텍스트 템플릿 변화가 제로샷 성능에 미치는 영향?
- 논문을 읽다보면, 제로샷 분류기를 구성할 때 클래스 이름을 단순히 사용하는 것이 아니라 “A photo of a {object}” 같은 문장 템플릿(prompt template)에 삽입해 사용한다는 점이 명시되어 있다.
또한, 2.5 Using CLIP에서는 이러한 템플릿을 여러 개 앙상블하면 성능이 더 좋아진다고도 설명한다:*“2.5. Using CLIP: ..as well as ensembling multiple of these templates in order to boost performance..”* - 여기서 나는 프롬프트 템플릿이 제로샷 성능에 얼마나 영향을 미치는지 궁금했다. ‘이미지 인코더가 실제로 강력한 표현을 학습한건지’ vs’ 좋은 프롬프트가 성능을 끌어올리는데 많은 기여를 했는지’의 의문이 들었다.
- 따라서 CLIP 이미지 인코더는 그대로 고정하고, 여러 형태의 프롬프트(간단한 클래스명 / 일반적 템플릿 / 더 상세한 설명)만 바꿔가며 제로샷 성능이 어떻게 달라지는지 확인해본다면 의미가 있을 것이라 생각했다.
- 프롬프트를 바꿨을 때 성능 변화 폭이 크다? → 모델이 이미지 이해 자체보다는 텍스트 힌트에 크게 의존하고 있을 수 있음
- 프롬프트를 바꿔도 성능 변화 폭이 작다? → CLIP 이미지 인코더가 robust하고 일반화된 표현을 학습했다고 볼 수 있음
- 예시: “{object}” / “A photo of a {object}” / “A animal with four legs, commonly raise as a pet:{object}”
6. Future Directions
Zero-shot 성능이 드러내는 한계점
1. 일부 벤치마크에서 드러나는 취약한 사례들
- CLIP은 의료,위성 같은 전문 도메인, 거리 인식,객체 세기처럼 복잡한 추론 task, 그리고 세밀한 차이를 구별해야 하는 fine-grained 데이터셋에서 zero-shot 성능이 낮은 케이스가 존재한다
2. 원인이 무엇일까?
- CLIP의 대조 학습은 배치 내 모든 negative를 동일하게 적용하는 구조
- 그러나 fine-grained class들 사이에서는 negative의 정도가 타 클래스와 다를 것
- 까치 vs 까마귀는 매우 비슷한 negative
- 까치 vs 비행기는 쉽게 구분할 수 있는 negative
- 이 차이를 모델이 고려하지 못하면, 세밀한 차이를 기준으로 클래스 경계를 학습해야 하는 task에서 어려움이 발생할 수 있음
3. 개선할 수 있는 point
- 세밀한 클래스끼리 더 집중해서 학습할 수 있도록, negative간 ‘정도’를 구분하는 방향으로 대조 학습을 조정해보자
- ‘비슷한 꽃 종류’, ‘비슷한 새 종류’처럼 모델이 헷갈리기 쉬운 negative를 조금 더 강조하는 방식
- 모델이 단순한 object level 구분을 넘어 꽃의 품종 차이, 새의 종 차이처럼 fine-grained의 의미를 더 안정적으로 포착할 수 있음
- 또한 loss 함수를 크게 바꾸지 않더라도 어떤 negative가 더 중요한가? 를 반영함으로써 zero-shot의 세밀한 표현력을 높일 수 있음
4. Pros & Cons
- Pros: 모델 구조 변경 없이 학습 전략을 조정해 CLIP이 취약한 task의 성능 향상, 비슷한 클래스 사이의 semantic 경계를 더 선명하게 학습함
- Cons: Negative간 유사도를 판단하기 위한 기준(임베딩 거리 등)이 필요, 학습 안정성에 대해 고려해볼 필요가 있음
7. Feedback
1️⃣ Zero-shot 프롬프트에 대한 부분
CLIP의 zero-shot classification에서 프롬프트 템플릿이 성능에 미치는 영향에 대한 질문은
CLIP 발표 당시에도 많이 논의되었던 주제라고 말씀해주셨다.
실제로 CLIP 논문의 Appendix를 보면 데이터셋별로 어떤 프롬프트가 가장 좋은 성능을 보였는지 정리되어 있다고 한다. 또한, 이후 연구들에서도 비교적 관용적으로 사용되는 프롬프트 템플릿들이 존재한다고 한다.
즉, “프롬프트 변화에 따른 성능 차이” 자체는 새로운 질문이라기보다는 이미 상당 부분 탐구된 영역이라는 점을 알게 되었다.
2️⃣ Hard Negative 기반 개선 아이디어에 대한 부분
Fine-grained task에서의 취약점을 보완하기 위해 hard negative를 더 강조하는 방향으로 contrastive learning을 조정해보자는 아이디어 역시 이미 여러 연구에서 시도된 바 있다고 말씀해주셨다.
실제로 hard negative mining, contrastive loss 변형 등과 관련된 논문들은 비교적 쉽게 찾아볼 수 있을 것 같다.
이 피드백을 통해, 내가 제안한 방향이 완전히 새로운 접근이라기보다는 기존 연구 흐름 안에 위치해 있다는 점을 다시 생각해보게 되었다.
