Paper Review: Collaborating Foundation Models for Domain Generalized Semantic Segmentation
paper review
CVPR 2024.
Yasser Benigmim, Subhankar Roy, Slim Essid et al.,
LIX, Ecole Polytechnique, CNRS, Institut Polytechnique de Paris, University of Aberdeen
30 Mar 2025
💡 Key Point
단일 모델의 한계를 넘어 CLIP, Diffusion, SAM이 결합된 도메인 일반화(Domain Generalization) 시맨틱 세그멘테이션 프레임워크
1. Motivation
‘도메인 일반화’ Semantic Segmentation(DGSS)의 부상
오늘날 Semantic segmentation은 이미지 내의 장면을 정밀하게 이해해야 하는 자율주행, 의료 영상 등 다양한 산업에서 매우 중요한 컴퓨터 비전 task로 자리 잡았다.
기존의 분할 모델들은 ‘학습 데이터’와 ‘테스트 데이터’의 환경이 동일할 때는 뛰어난 성능을 보여주는데, 중요한 점은 실제 산업 현장에서는 모델이 한 번도 접해보지 못한 새로운 환경에 직면하는 일이 많다는 것이다.
이처럼 환경이 변화하는 ‘도메인 이동(Domain Shift)’ 상황에서는, 기존 네트워크들은 성능이 급격히 저하되는 취약함을 보인다. 결과적으로 모델이 학습된 특정 환경에만 얽매이지 않고, 미지의 환경에서도 안정적인 성능을 보장하는 것이 필수적이게 되었다.
기존 DGSS 연구의 한계
기존의 DGSS 연구들은 주로 이미지의 명암이나 색상, 날씨 등 '스타일'만을 인위적으로 변형하는 도메인 무작위화(Domain Randomization) 방법에 크게 의존해 왔다. 하지만 이러한 방식은 기존 데이터의 겉모습만 바꿀 뿐, 이미지 속 '콘텐츠' 자체를 새롭게 생성하거나 다양화하지는 못하기 때문에 최적의 성능을 끌어내는 데 뚜렷한 한계가 존재한다.
또한 최근 등장한 강력한 파운데이션 모델들을 도입하려는 시도도 있었으나 쉽지 않았다. 예를 들어 SAM의 경우, 객체의 형태(마스크)는 매우 정밀하게 따내지만 그것이 '나무'인지 '인도'인지와 같은 의미론적 정보는 전혀 알지 못해 분할 모델에 직접적으로 활용하기 까다롭다는 문제가 있었다.
⇒ 따라서 단순한 스타일 변형을 넘어, 모델이 처음 보는 환경에도 유연하게 대응할 수 있는 방법을 찾아야 하고 효과적으로 학습에 반영하는 시스템이 필요하다.
2. Insight
1) 여러 파운데이션 모델을 협력시켜 범용적인 분할 능력을 만들자
기존 DGSS 연구들은 주로 특정 증강 방식이나 스타일 랜덤화 방법에 의존해 일반화 성능을 높이려 했다. 하지만 저자들은 단일 모델이나 단일 전략만으로는 다양한 미지 환경을 충분히 대응하기 어렵다고 판단했다.
저자는 여기서 가설을 하나 세운다. 하나의 거대한 모델에 모든 능력을 기대하기보다 서로 다른 강점을 가진 여러 파운데이션 모델들을 조합하면 훨씬 더 강력한 일반화 능력을 만들 수 있다는 것이다.
즉, CLIP으로 시각 표현을 담당하고 Diffusion 모델은 새로운 환경과 콘텐츠를 생성하며 SAM은 정밀한 객체 형태를 보완하는 식으로 각 foundation model의 강점을 역할 분담 형태로 결합했다. 이를 통해 특정 도메인에 과도하게 의존하지 않고, 다양한 미지 환경에서도 안정적으로 동작하는 segmentation 시스템을 구축하고자 했다.
2) 가상으로 생성된 데이터를 활용해 self-training을 해보자
기존 DGSS의 데이터 증강은 주로 색감이나 스타일 변화에 집중되어 있었기 때문에, 실제로는 새로운 환경 자체를 충분히 경험시키지 못한다는 한계가 있었다.
저자들은 여기서 한 가지 중요한 관점을 제시한다. 단순히 기존 데이터를 변형하는 것을 넘어, 아예 ‘새로운 환경’을 가상으로 생성해 학습에 활용하면 모델이 훨씬 더 다양한 도메인을 경험할 수 있다는 것이다.
이를 위해 LLM과 확산 모델을 활용해 다양한 상황과 장면을 가진 데이터를 생성하고, 이를 self-training 과정에 적극적으로 활용했다. 즉, 현실에서 수집하기 어려운 미래의 환경들을 미리 가상으로 만들어 학습시키는 방향으로 접근한 것이다.
하지만 생성 데이터 기반 학습에서는 pseudo label에 포함된 노이즈 문제가 필연적으로 발생한다. 저자들은 이 문제를 어떻게 해결하고자 했는지 Method를 통해 살펴보자.
3. Method
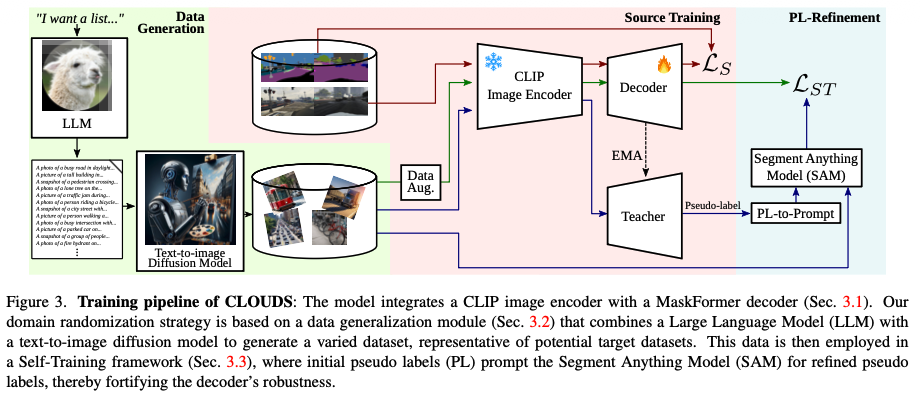
‘CLOUDS’ training pipeline
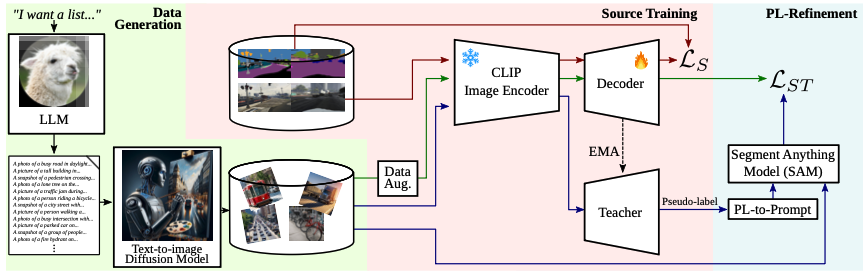
Module 1: CLIP 인코더 + student-teacher 네트워크 도입
인코더: CNN-based CLIP Image Encoder
일반적으로 쓰이는 ViT-based가 아닌 CNN-based CLIP 이미지 인코더를 채택했다. 이유는 고해상도 이미지의 분할 작업에서는 CNN 기반이 더 성능이 좋다는 기존 연구 결과를 적용한 것이다.
인코더는 freeze해서 훈련시킨다. 1) 사전 학습된 표현력을 그대로 가져가며 2) 소스 도메인(훈련 데이터)의 overfitting을 방지할 수 있고 타겟 도메인의 일반화 성능을 보장할 수 있기 때문!
디코더: Mask2Former Decoder
디코더로는 Mask2Former 디코더를 채택했다. 특징을 간략히 보면 일반적으로 진행하는 픽셀 단위의 분할을 하지 않고 먼저 이미지를 여러 영역으로 나누고 각 영역을 분류하는 방식으로 분할을 수행한다.
초기 소스 데이터를 학습할 때는 이 디코더 부분만 학습시킨다. Loss 함수는 Mask2Former의 방식을 그대로 차용했으며, 아래 수식과 같다:
- : 마스크 예측 손실, BCE loss와 Dice loss의 선형 결합
- : 클래스 분류 손실
- : 두 손실 값 사이의 균형 인자
Self-Training 채택: student-teacher 네트워크 도입
이후 후술할 생성 모델이 만들어낸 합성 이미지들을 학습에 사용하기 위해, 자기 지도 학습(Self-training) 방식을 채택했고 학생-교사 네트워크 도입으로 학습의 안정성을 챙겼다. 인코더는 frozen이므로 이 학생-교사 구조는 오직 디코더에만 적용된다.
- 학생 모델(): 파라미터를 직접 업데이트하며 학습이 진행되는 주체. 강건한 모델을 만들기 위해, 이 모델에는 데이터 증강이 적용된 이미지가 입력된다.
- 교사 모델(): 학생 모델의 파라미터를 ‘지수 이동 평균(EMA)’ 방식으로 서서히 따라가도록 업데이트되는 모델. 이 모델에는 원본 이미지가 입력되며, 학생이 정답으로 사용할 pseudo label을 생성한다.
참고로 교사 네트워크의 파라미터() 업데이트 수식은 아래와 같다:
- : 학생 모델의 파라미터
- : 교사가 학생을 얼마나 천천히 따라갈지 결정하는 momentum 제어 계수
Module 2: 다양한 상황 및 가상 타겟 데이터 생성
다양한 상황 묘사 생성: Llama-2 LLM
이미지 생성 모델에 입력할 다양한 프롬프트를 사람의 개입 없이 대량으로 얻기 위해 Llama-2 LLM을 활용한다.
결과적으로 LLM은 이라는 일관된 템플릿을 따르는 무수히 많은 프롬프트를 생성한다.
템플릿: ‘a photo of X in Z’
(여기서 X는 정답 클래스, Z는 날씨나 시간대 등 환경적 맥락을 뜻한다.)
이미지 생성: T2I Stable Diffusion
단순히 이미지의 겉보기 스타일만 바꾸는 기존의 도메인 무작위화 방식을 넘어, ‘콘텐츠’ 자체가 완전히 새롭고 다양한 이미지를 합성하기 위해 T2I Diffusion 모델을 사용한다.
모델은 사전 훈련된 Stable Diffusion을 사용하고 앞서 Llama-2가 생성한 프롬프트들을 입력으로 받아 새로운 합성 이미지들을 만들어낸다. 이는 이후에 교사 모델로 넘어가고 교사 모델이 각 이미지에 대해 분할 예측을 수행해 pseudo label(임시 정답)을 만든다. 이는 이후 정제를 통해 학생 모델 학습 과정에서 정답지로 사용된다!(중요)
참고로, 생성 타겟은 본 논문에서 사용한 ‘자율주행’ 벤치마크에 따라 주로 눈 오는 날, 밤거리 등 다양한 조건이 묘사된 ‘도시 거리 풍경’에 맞췄다.
Module 3: pseudo label 정제 → self-training
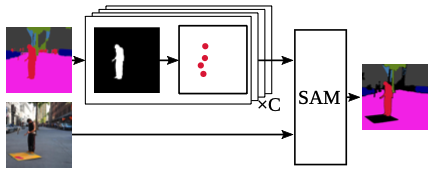
teacher 모델이 만든 pseudo label 정제
교사 모델이 합성 이미지를 보고 예측한 초기 pseudo label()에는 필연적으로 도메인 차이로 인해 노이즈가 섞여있을 수 밖에 없다. 이를 학생 모델의 학습에 그대로 사용하게 된다면? 학습 불안정 및 성능 저하가 일어날 게 뻔하다..
따라서 저자는 pseudo label의 노이즈를 정제하기 위해 SAM을 적용했다. SAM을 효과적으로 활용하기 위해 여기서 ‘포인트 기반 프롬프팅(Point-based prompting)’ 이라는 과정을 거친다:
-
클래스별 마스크 분해 및 객체 분리
먼저 pseudo label을 각 클래스별 binary mask로 나눈다. 여기서 같은 클래스(ex. 사람, 자동차) 객체들이 서로 뭉쳐있을 수 있으므로, Hoshen-Kopelman 알고리즘을 적용해 독립된 개별 객체 단위로 깔끔하게 분리하고, 너무 작은 크기의 영역은 노이즈로 간주해 필터링한다.
- Hoshen-Kopelman 알고리즘?: 격자나 이미지 내에서 서로 연결되어 있는 픽셀들의 덩어리를 찾아 각각 고유한 번호(라벨)을 부여하는 ‘연결 요소 라벨링’ 알고리즘 중 하나이다.(자세한 내용은 검색)
-
SAM을 통한 윤곽선 정제
분리된 각각의 mask 내부에서 무작위로 점(points)들을 추출하여 SAM에게 프롬프트로 전달한다. SAM은 이 점들을 바탕으로 실제 객체의 윤곽에 딱 맞는 한층 더 정확하고 고품질의 mask를 반환한다.
-
충돌 해결 및 병합
SAM이 예측한 모든 mask를 하나로 합쳐 최종 pseudo label을 완성한다. 만약 SAM이 예측한 서로 다른 클래스의 마스크가 겹치는 픽셀이 발생한다면, 학생 모델이 잘못된 정답으로 학습하는 것을 막기 위해 해당 영역을 ‘라벨 없음(unlabeled)’으로 처리한다.
최종적으로 student 모델 학습 진행
결과적으로 학생 모델은 SAM으로 정제된 pseudo label을 정답으로 삼아 자기 지도 학습(self-training)을 진행한다.
이때 학생 모델이 수행하는 자기 지도 학습 loss()는, 초기 소스 데이터셋(정답지가 있는 원본 데이터)을 학습할 때 사용했던 지도 학습 손실()과 완전히 동일하게 적용된다:
4. Experiment Analysis
1) 기존 DGSS & Foundation Model과의 성능 비교
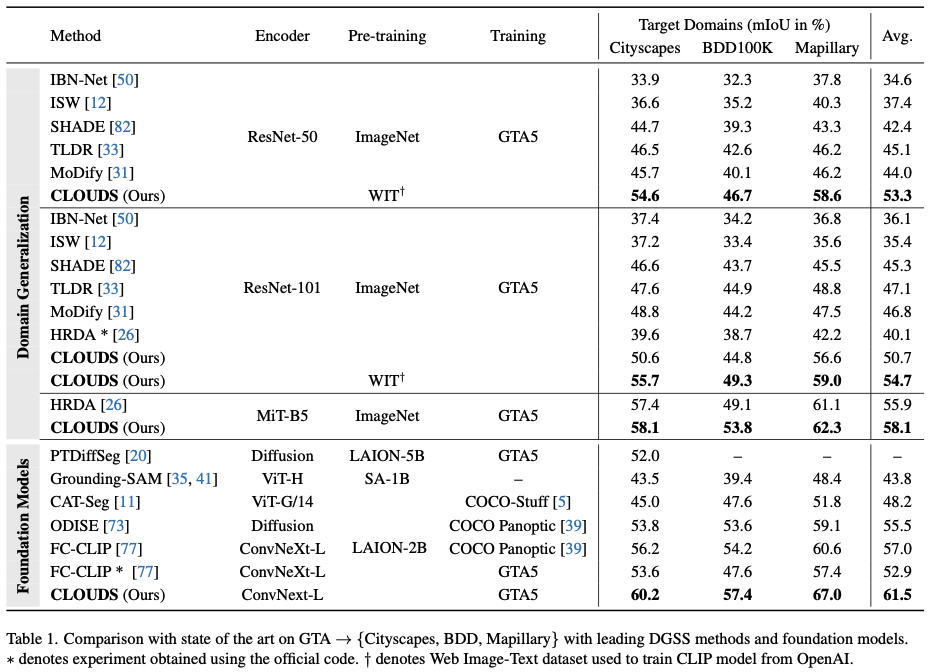
- 전통적인 DGSS 방법들(HRDA 등)을 포함해 최근 주목받는 파운데이션 모델 기반의 open-vocabulary(FC-CLIP, ODISE 등) 방법론들의 성능을 모두 큰 폭으로 능가함.
- ConvNeXt-Large 백본 적용 시, 평균 mIoU 61.5%를 기록. 기존 SOTA 모델이었던 HRDA 대비 +5.5% 라는 상당히 큰 격차의 성능 향상을 보여줌.
- 기존 open-vocabulary 모델들은 텍스트에 크게 의존해 텍스트로 묘사하기 애매한 클래스 분할은 실패했지만, CLOUDS는 소스 데이터에서 직접 시각적 단서를 학습해 복잡한 객체들까지 상당히 잘 분할함.
2) 악천후 환경에서의 zero-shot 도메인 적응 성능
- 일반적인 맑은 날씨 환경에서 학습한 뒤, 악천후 조건의 실제 주행 데이터(눈, 비, 야간)에서 성능 평가 진행. 텍스트 프롬프트 기반의 기존 zero-shot domain adaptation 모델인 PØDA와 비교 실험 진행.
- 동일한 ResNet-50 백본을 기준으로 더 높은 mIoU를 기록하며 대부분의 극한의 환경에서도 안정적으로 작동함을 보여줌.
- 야간 환경: +4.4% 향상
- 눈 내리는 환경: +8.2% 향상
- 비 오는 환경: +7.4% 향상
3) Ablation Study
각 Foundation Model의 기여도
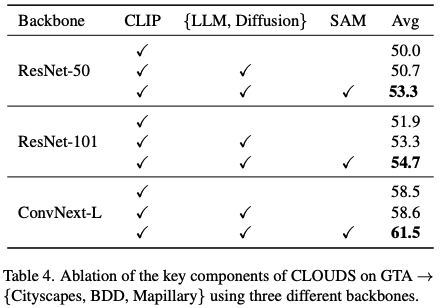
- CLIP 백본 단독으로도 강력한 특징 추출 능력을 보여 우수한 성능을 보여줌.
- LLM과 확산 모델을 추가해 가상 데이터를 생성했을 때는 ‘라벨 노이즈’로 인해 성능 향상이 미미함.
- SAM을 투입해 노이즈를 정제하자 모든 백본에서 약 3%의 큰 성능 향상을 확인함. 자기 지도 학습에서 SAM 역할의 중요성을 알 수 있는 대목.
SAM 프롬프팅 최적화
- SAM에게 힌트로 주는 점(points)을 너무 많이 추출하면 오히려 노이즈가 발생해 성능이 하락.
- 객체 분리 시(Hoshen-Kopelman 알고리즘) 너무 작은 픽셀 덩어리를 무시하는 임계값을 높이면 노이즈 필터링이 잘 되어 성능이 향상됨.
데이터 규모 & CLIP 백본 freeze의 영향력
- 합성된 가상 이미지를 많이 사용할수록 성능이 오르지만, 약 5000장을 넘어가면 성능 향상이 멈추고 최대 효율에 도달한다는 사실을 알게 됨.
- feature extractor인 CLIP 백본을 fine-tuning해서 사용하면, 예상한대로 소스 데이터에 overfitting되어 미지의 도메인에 대한 예측 성능이 오히려 크게 떨어짐. 결론은 백본은 freeze하는 것이 일반화에 훨씬 적합함.
5. Significance of Paper
이 논문은 도메인 일반화 시맨틱 세그멘테이션(DGSS)를 단순한 augmentation 문제로 바라보지 않고 여러 파운데이션 모델들의 강점을 적절히 조합해서 문제를 해결했다는 점에서 의미가 크다.
기존 DGSS 연구들은 주로 스타일 변화나 feature normalization 같은 제한적인 방법으로 도메인의 차이(gap)을 줄이는 데 집중했다. 반면 이 논문은 CLIP ↔ Diffusion ↔ LLM ↔ SAM을 각각 독립적인 도구로 사용하는 것이 아닌 서로의 약점을 보완하는 하나의 시스템처럼 연결했다.
즉, robust representation은 CLIP이 담당하고, 다양한 환경 생성은 diffusion model이 수행하며, noisy pseudo label 보정은 SAM이 담당하는 식으로 역할을 분리했다.
특히 이 논문은 '미지 환경에 강한 모델을 만들기 위해서는 새로운 환경 자체를 많이 경험시켜야 한다'는 관점을 강조하는 것 같다. 단순히 기존 데이터를 변형하는 수준을 넘어, 아직 존재하지 않는 다양한 상황을 생성 모델로 가상 생성해 학습에 활용한 아이디어는 앞으로 내 연구에도 참조할만 한 것 같다.
또한 이 논문은 foundation model 시대 이후의 segmentation 연구 방향에 대한 좋은 예시를 보여준다. 앞으로의 연구는 단순히 하나의 거대한 모델 성능만 높이는 것이 아니라, 여러 foundation model의 능력을 어떻게 효과적으로 조합하고 연결할 것인가가 점점 더 중요해질것으로 보인다. 그런 점에서 CLOUDS는 향후 robust perception이나 domain generalization 연구 흐름에서도 의미 있는 방향성을 제시한 연구라고 생각한다.
