Paper Review: Instruction-based Image Editing with Planning, Reasoning, and Generation
paper review
ICCV 2025.
Liya Ji, Chenyang Qi, Qifeng Chen
Hong Kong University of Science and Technology (HKUST)
October 2025
💡 Key Point
계획(Plan) → 추론(Reason) → 생성(Generate) 기반의 새로운 AI 이미지 편집 방법을 제안한 논문.
1. Motivation
Instruction-based Image Editing이란?
사용자가 입력한 텍스트 지시문을 기반으로 이미지를 수정하는 task이다. 지시문을 정확히 이해하고 필요한 영역만 자연스럽게 편집해야 하기 때문에 scene understanding과 image generation 능력을 동시에 요구한다.
기존에는 어떻게 접근했을까?
초기 연구들은 주로 (LLM ↔ segmentation 모델 ↔ diffusion 편집 모델) 등을 ‘단계적으로’ 연결하는 구조를 사용했다.
- ex) ChatGPT나 GroundingDINO를 이용해 편집 영역(mask)를 만든 뒤, diffuion 편집 모델에 전달하는 식으로..
이후에는 T2I diffusion 모델을 instruction editing task에 맞게 end-to-end 방식으로 fine-tuning하는 연구들이 등장했으며, 최근에는 MLLM을 활용해 멀티모달 reasoning 능력을 편집 과정에 적용하려는 시도도 이루어지고 있다.
기존 접근법의 한계
하지만 기존 방법들은 몇 가지 중요한 한계를 가진다.
- 과정 분리의 부재
understanding, region localization, generation 과정을 충분히 분리하지 않은 채 한 번에 처리하기 때문에 diffusion model의 부담이 매우 커진다(생성 과정이 불안정해진다). - ‘객체’ 단위의 segmentation
기존 방법들은 주로 객체 단위 segmentation에 의존하기 때문에, 실제로 수정되어야 하는 엄밀한 국소 지역을 정확하게 찾지 못하는 문제가 있다. - 추상적&복합적인 instruction 처리의 어려움
dramatic, beautiful과 같은 추상적인 표현이나 복합적인 지시문은 단순히 텍스트 인코더만으로 충분히 이해하기 어렵다. 즉 지시문 이해 ↔ 이미지 생성 사이의 연결(bridge)이 부족했다.
⇒ 결국 단순히 generation 능력만이 아닌 지시문을 단계적으로 reasoning하고 어떤 영역을 수정해야 하는지 명확히 추론하는 멀티모달 기반의 프레임워크가 필요하다!
2. Insight
1) 하나의 복잡한 지시문 → 여러 개의 하위 프롬프트로
사용자의 이미지 편집 지시문은 추상적인 표현이나 여러 수정 사항이 한 문장에 함께 포함되는 경우가 많다. 기존 방법들은 이를 한 번에 처리하려 했기 때문에 instruction을 충분히 이해하지 못하거나 generation 과정의 부담이 커지는 문제가 있었다.
저자들은 여기서 LLM의 사고의 사슬, Chain-of-Thought(CoT) 방식에 주목했다.
즉, 복잡한 instruction을 여러 개의 구체적인 하위 프롬프트(sub-task)로 나누어 단계적으로 planning하면, 편집 모델이 지시를 훨씬 안정적이고 정확하게 수행할 수 있을 것이라는 통찰을 얻는다.
2) 편집 영역 파악은 ‘객체 단위 분할’로는 부족하다
기존 연구들은 주로 객체 단위 segmentation을 이용해 편집 영역을 찾았지만, 실제 editing target은 객체의 윤곽과 일치하지 않는 경우가 많다.
예를 들어 “사람이 테니스 공을 뛰어넘게 바꿔줘”라는 instruction에서는 실제로 수정되어야 하는 영역이 사람 자체가 아니라 다리 아래의 빈 공간일 수 있다.
즉, instruction-based image editing에서는 단순 객체 분할을 넘어 전체 문맥과 사용자의 의도를 이해해 실제로 수정이 필요한 editing region을 reasoning할 수 있는 능력이 중요하다는 점을 깨닫는다.
3. Method
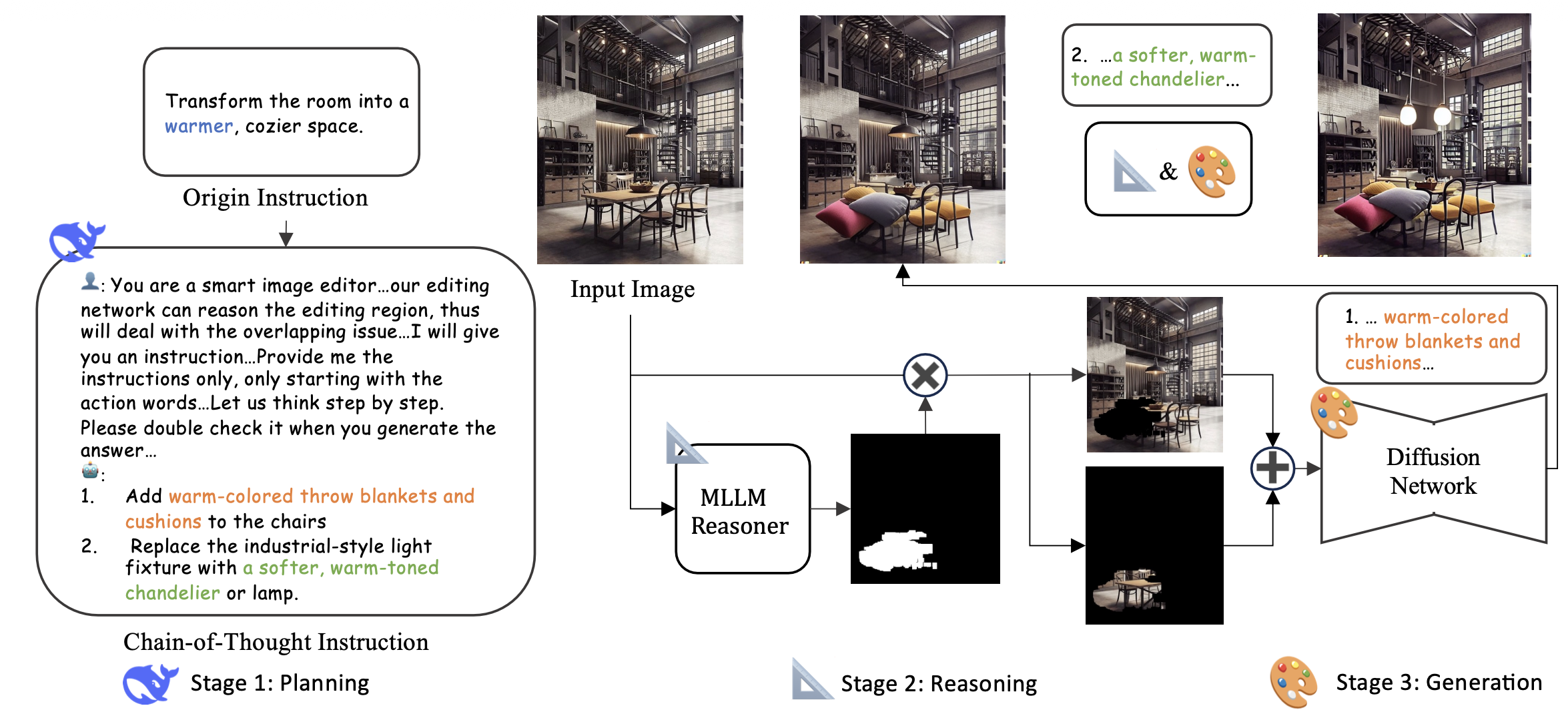
Chain-of-Thought Editing Framework
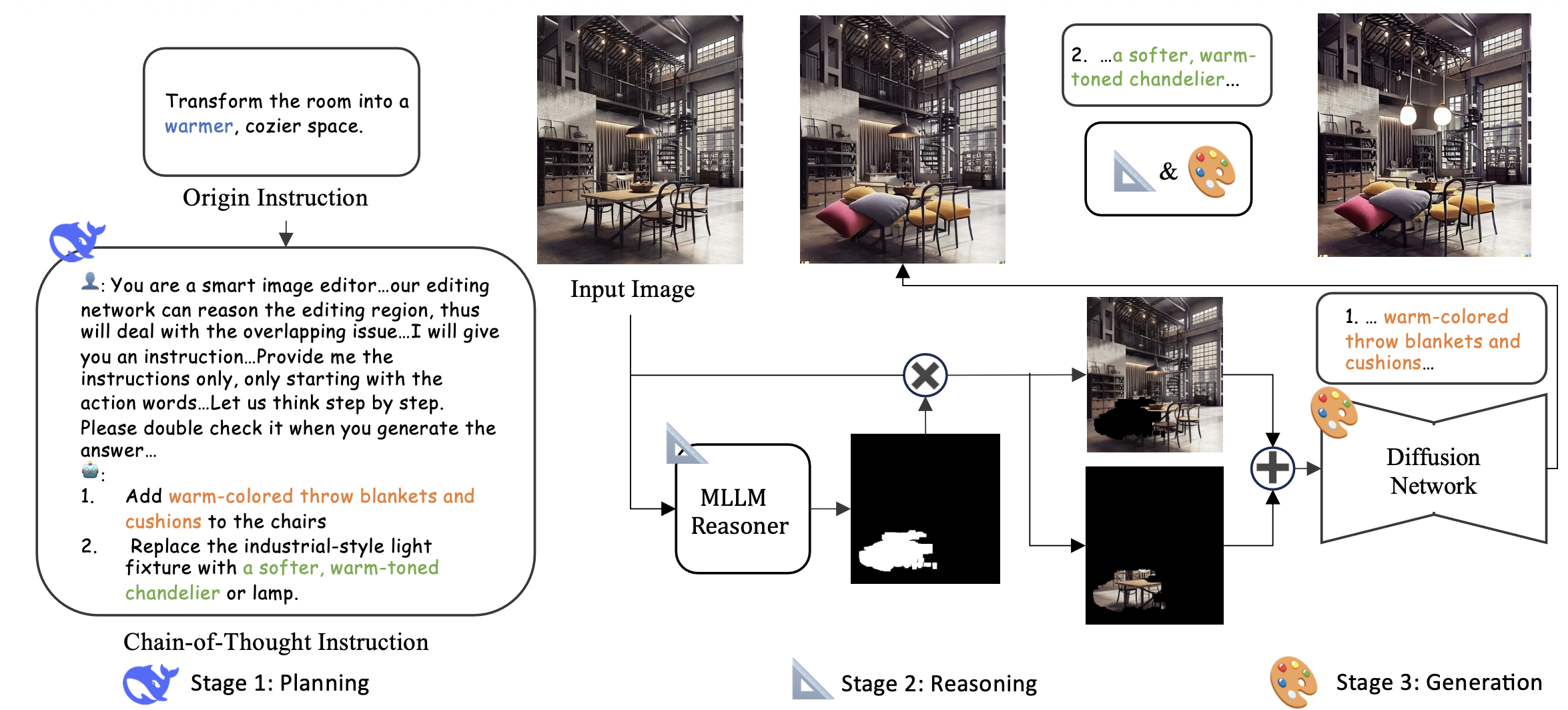
1단계: Planning - 생각의 사슬(Chain-of-Thought) 프롬프팅
가장 먼저, 사용자의 원본 지시문을 입력 이미지를 참조해 여러 개의 하위 프롬프트로 세분화하여 생성한다. 이 과정에서 DeepSeek Reasoning Model을 사용하고 하위 프롬프트들은 텍스트 + 편집 마스크에 대한 정보를 포함한다.
수식 (1)은 복잡한 편집 요청을 받았을 때, 이를 여러 개의 구체적인 작은 작업(하위 프롬프트)으로 쪼개서 '작업 지시서 세트()'를 만드는 과정이다.
- : 하위 프롬프트를 생성하는 CoT 플래너
- : 편집 영역을 추론하는 MLLM 추론기(reasoner)
- (작은 명령): 플래너()라는 AI가 사용자의 복잡한 지시를 분석해 단계별 지시사항으로 쪼갠 것.
- (편집 영역): 추론기()라는 AI가 원본 이미지()를 보고, 1단계 명령을 수행하려면 이미지의 어느 부분을 건드려야 할지 영역(마스크)을 찾아낸다.
즉, 명령어()와 그 명령을 적용할 위치()를 짝지어서, 총 개의 작업 지시서 세트()를 만들겠다는 의미로 이해하면 된다.
위 과정을 거쳐 다중 모달 프롬프트가 생성되면 조건부 생성 모듈이 이를 바탕으로 편집을 진행한다.
수식 (2)는 위에서 만든 지시서를 가지고 생성 모델이 단계별로 이미지를 덧그려 나가는 과정이다.
- : 실제로 이미지를 생성하는 생성 모델
- : 현재까지 그려진 이미지 (은 원본 이미지)
- : 현재 이미지에 한 단계 수정을 가해서 나온 '다음 이미지'
즉, "현재 이미지()에, 아까 정해둔 위치()와 지시사항()을 전달하여, 모델()이 새로운 버전의 수정된 이미지()를 만들어낸다는 의미.
2단계: Reasoning - ‘객체’가 아닌 ‘편집 공간’의 이해
이제 이미지의 어느 부분을 수정해야 하는지를(편집 영역) 어떻게 파악할지 생각해봐야 한다.
그동안 기존 연구들은 이 편집 영역을 찾는 방법으로 ‘객체 단위 분할법(Object-level segmentation)’을 사용해왔는데, 이 접근은 사실 적합하지 않다는 사실을 깨닫는다.
이전에 ‘2. Insight’ 파트에서 언급했다싶이, 만약 사용자의 요구가 객체와 객체 사이의 공간 또는 배경의 특정 부분을 수정해달라는 명령을 내렸을 때, 실제로 편집되어야 할 부분은 ‘객체’ 뿐만 아니라 지시문에 나와있는 ‘그 공간 자체’이기 때문이다.
따라서 저자는 더 자연스럽고 다양한 수정 결과를 얻기 위해 ‘대력적인’ 편집 영역만 잡아내는 전략을 가져간다. MLLM 기반의 이미지 분할 기술을 편집 영역 생성 용도로 맞춤 개조한 방식을 제안한다.
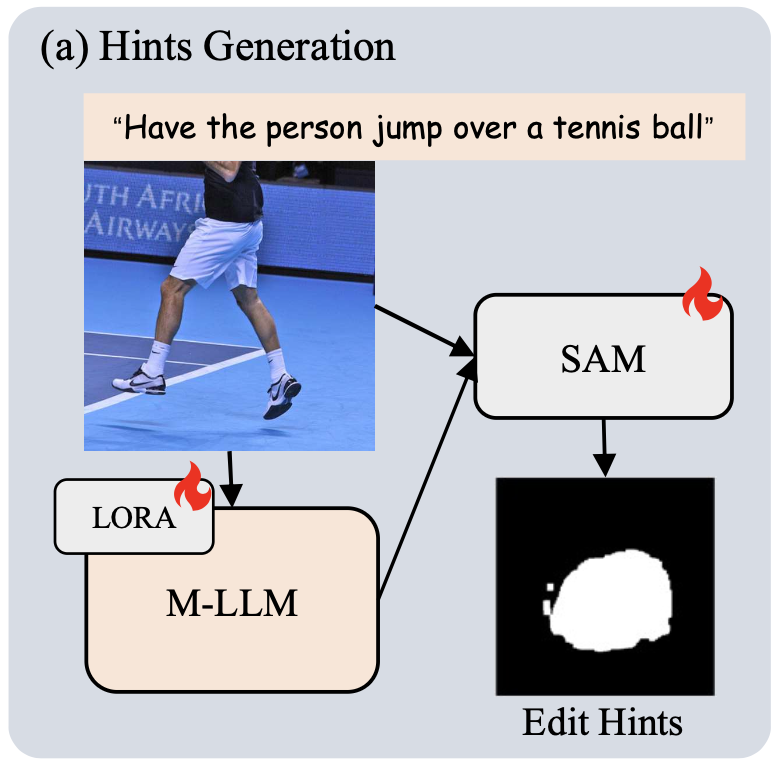
과정: LoRA 적용 → SAM과 결합 → Training
기존의 MLLM의 파라미터는 그대로 고정하고, 분할에 필요한 ‘추론 token’을 생성하는 역할만 하도록 가벼운 추가 모듈인 LoRA만 훈련시킨다.
이후 이미지의 시각적 특징을 잘 잡아내는 pre-trained SAM 모델을 가져온다. 여기서 SAM은 앞서 LLM이 생성한 힌트(출력 token)를 바탕으로 최종적인 추론 마스크(편집할 영역)를 그려낸다.
훈련 방법은 LISA 프레임워크에서 영감을 받아 전체 모델을 training하지 않고 LoRA와 SAM Decoder만 학습시킨다.
이러한 학습 과정을 모두 마치면, 이 네트워크는 새로운 입력 이미지와 명령어가 주어졌을 때 스스로 판단하여 정확히 어디를 편집해야 할지 그 영역을 성공적으로 추론해 낼 수 있게 된다.
3단계: Generation - 힌트 기반의 정밀한 생성 과정
이제 이전 단계들에서 만든 '작업 지시서'를 바탕으로 실제로 이미지를 수정하는 단계이다. 뛰어난 생성 능력을 가진 Stable Diffusion U-Net을 뼈대로 쓰며, 텍스트 이해 모듈은 고정(frozen)하여 명령을 안정적으로 받아들이게 했다.
가장 핵심적인 제어 방식은 마스크 영역을 기준으로 원본을 두 부분으로 쪼개서 모델에게 '공간적 가이드라인'으로 제공하는 것이다.
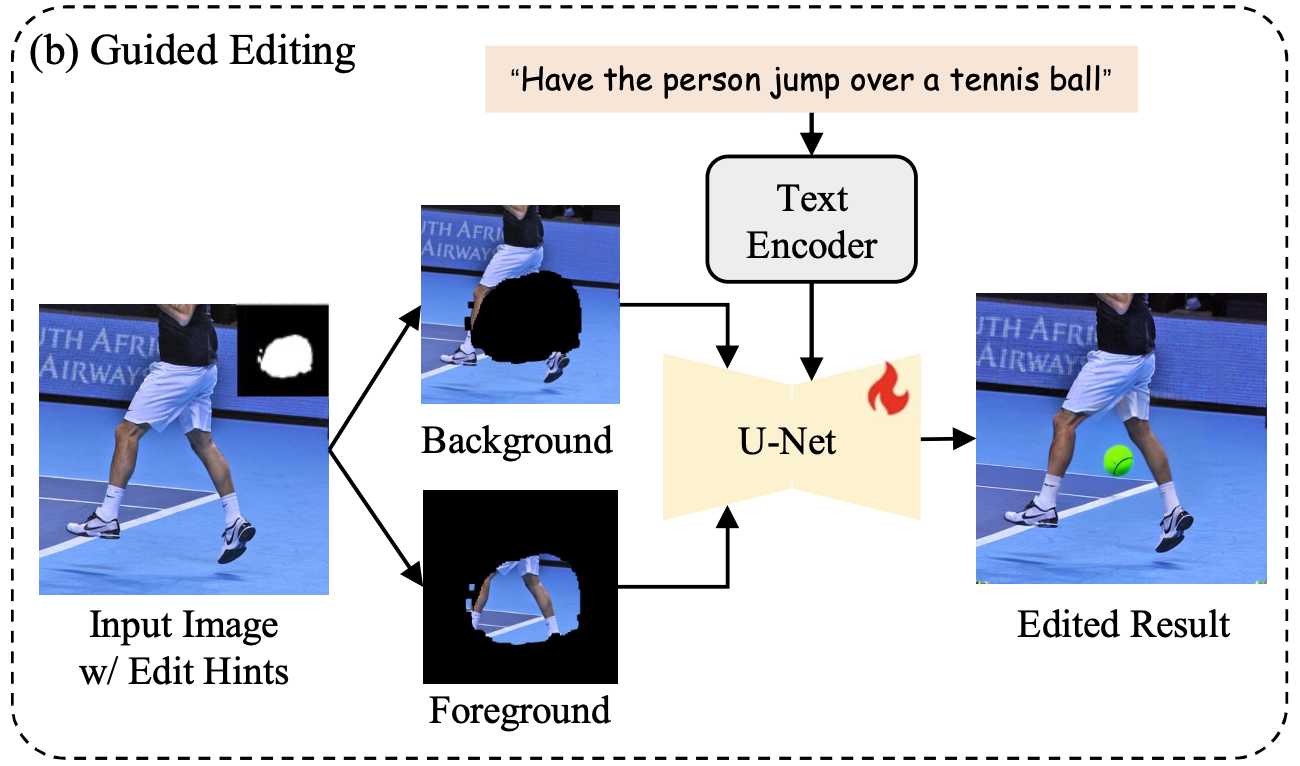
- (전경 이미지): 마스크를 씌운 부분. 실제로 수정할 타겟 영역
- (배경 이미지): 마스크 밖의 부분. 수정 없이 유지할 원본 영역
이 두 이미지는 텍스트 지시문과 함께 디퓨전 모델의 추가 조건으로 들어간다.쉽게 말해, 생성형 모델에게 ‘여기()는 지시대로 고치고, 나머지()는 절대 건드리지 말 것’ 라고 명확히 통제하는 것이다.
입력 조건이 늘어났지만, 복잡한 수정 없이 첫 번째 컨볼루션 레이어'의 가중치만 살짝 확장(이 부분은 아직 온전히 이해하지 못함)하는 것만으로 완벽한 처리가 가능하다.
※ 참고: Classifier-free Guidance의 다중 제어 적용
모델에게 가이드라인을 너무 타이트하게 주면 지시는 잘 따르지만 모델 본연의 창의성과 다양성이 떨어질 수 있다. 이를 막기 위해 본 모델은 훈련 중 일부 조건을 고의로 가리는(drop) CFG(Classifier-free Guidance)를 활용했다.
이 모델은 제어 조건이 "3가지(전경 , 배경 , 텍스트 )"나 되기 때문에, 저자들은 각 조건의 영향력을 독립적으로 통제할 수 있도록 기존의 CFG를 수식 (6)으로 확장했다. (수식 6은 분량이 길어 논문에서 직접 참고 바람.)
이를 위해 훈련 과정에서 무작위로 조건을 가리며(drop) 밸런스를 맞춘다:
- 5% 확률: 텍스트 명령어만 가림
- 5% 확률: 배경 이미지와 텍스트 명령어 모두 가림
- 5% 확률: 3가지 조건 전부 가림
즉, 복잡한 지시를 주면서도 종종 지시서를 무시하고 그리게 하여 모델 고유의 풍부한 그림 실력을 잃지 않도록 조율하는 기술을 적용했다는 정도로 이해하면 될 것이다.
4. Experiment Analysis
1) 편집 성능 SOTA 달성 (MagicBrush SOTA)
- MagicBrush 데이터셋 평가 결과, InstructPix2Pix 등 기존 모델들을 앞서는 모든 정량 평가 지표(이미지 유사도, 텍스트 반영도)에서 SOTA를 달성했다.
- 특히 MLLM이 추론한 정확한 마스크 때문에 원본은 최대한 보존하면서 지시된 타겟 영역만 완벽하게 수정하는 뛰어난 국소(Local) 편집 능력을 보여줬다.
2) Abstract 개념을 성공적으로 시각화
- "분위기를 극적으로 바꿔줘"와 같은 추상적인 명령을 평가하는 HQEdit-Abstract 테스트에서 타 모델들을 넘어서고 사용자 평가(Abstract Score) 1위를 달성했다.
- CoT 플래닝을 통해 모호한 지시를 구체적인 단계별 행동(ex. 잔잔한 물을 거친 파도로 변경, 먹구름 추가 등)으로 번역하여 사용자의 의도를 가장 풍부하게 구현해냈다.
3) 핵심 기술의 효과 및 타 생성 모델로의 확장성
- 세 가지 조건(전경, 배경, 텍스트)에 대한 독립적인 CFG 스케일 조절 실험을 통해, 지시 수행력과 모델 고유의 생성 다양성 사이의 최적의 밸런스를 검증했다.
- 본 논문의 계획 → 추론 → 생성 프레임워크를 최신 고성능 모델인 Flux에 적용했을 때도 우수한 편집 결과를 보여, 향후 다른 모델에도 쉽게 결합할 수 있는 높은 범용성을 보여준다.
5. Significance of Paper
이 논문은 단순히 모델의 파라미터를 키우는 것보다 '인간의 사고 과정'처럼 편집 단계를 나누어 설계하는 것이 더 중요할 수 있음을 보여준다.
기존 연구들은 보통 diffusion 모델 하나가 명령어 이해부터 편집까지 모두 처리하는 end-to-end 방식이 많았다. 하지만 이 논문은 전체 과정을 '계획(Planning) - 추론(Reasoning) - 생성(Generation)'의 3단계로 분리하는 아이디어를 적용했다.
이렇게 하면 복잡한 지시를 잘게 쪼개어
1) 모델의 부담을 줄일 수 있고,
2) 결과물에 문제가 생겼을 때 어느 단계(플래너의 계획 실수인지, 마스크 추론의 오류인지)에서 잘못되었는지 쉽게 파악할 수 있다.
즉, 시스템의 제어력과 해석 가능성이 크게 높아지는 것이다.
또한, 이 논문은 생성형 AI를 실제 서비스에서 어떻게 활용해야 할지 구체적인 방향을 제시했다는 점에서도 의미가 있다.
실제 사용자들은 '분위기를 극적으로 바꿔줘'처럼 모호하고 복잡한 지시를 자주 내리는데, 기존 모델들은 이를 잘 이해하지 못해 엉뚱하게 원본 이미지를 훼손하는 경우가 많았다. 반면, 이 논문은 MLLM을 활용해 추상적 지시를 구체적인 행동으로 번역하고, 수정해야 할 '정확한 공간'을 스스로 찾아내어 필요한 부분만 자연스럽게 편집한다.
게다가 특정 모델에 종속되지 않아 Flux 같은 최신 고성능 모델에도 곧바로 결합해 사용할 수 있다. 이는 단순한 연구 수준을 넘어, 향후 인터랙티브 디자인 툴이나 차세대 사진 편집 서비스의 핵심 파이프라인으로 널리 응용될 수 있는 강력한 확장성을 보여준다.
