CVPR 2025.
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi
Allen Institute for AI | University of Washington | University of Pennsylvania
25 Sep 2024
💡 Key Point
정교하게 설계된 데이터셋과 학습 패러다임만으로도, 독점(proprietary) 모델에 의존하지 않는 경쟁력 있는 VLM을 만들 수 있다!
1. Motivation
VLM의 현재 실태
- 최근 가장 뛰어난 성능을 보이는 VLM은 대부분 데이터셋, 가중치 등을 공개하지 않는 ‘Proprietary(독점) 모델’
- 이에 따라 여러 연구들은 독점 모델에 준하는 성능을 ‘Open 기반 모델’로 재현하려는 시도를 해왔음
- 초기 연구는(ex.LLaVa) 완전한 오픈 데이터, 언어 모델로 VLM을 구축했지만 SOTA proprietary VLM와 큰 성능 격차가 존재
- 이후 연구는 ‘개방성’을 줄이는 추세로 변화함, 독점 VLM이 생성한 합성 데이터에 크게 의존하는 형태로 바뀜 → 많은 open VLM들은 proprietary VLM의 증류본 형태
⇒ 독점 VLM의 지식을 사용하지 않고, 처음부터 성능이 뛰어난 ‘오픈형 VLM’을 구축하는 근본적인 방법을 놓치고 있는 상태
2. Insight
학습에 필요한 ‘high-quality 멀티모달 데이터 확보’가 핵심
1) VLM의 성능은 LLM의 성능보다 ‘데이터’에 달려있다
- 기존 open VLM 연구는 저성능의 원인으로 언어 모델의 규모나 추론 능력의 부족으로 꼽았음
- 하지만 Molmo(제안한 데이터셋)는 오픈 LLM(OLMo, Qwen)으로도, 어떤 시각-언어 데이터를 학습했는지에 따라 성능이 크게 달라진다는 것을 발견함
⇒ VLM의 성능은 LLM 자체가 아니라 시각 정보를 어떻게 구조화시켜 언어 모델에 전달했는지에 달림
2) 훈련 데이터는 ‘사람의 시각적 인식’으로 만들어진 데이터여야 한다
- 기존 VLM의 데이터셋은 대부분 proprietary VLM이 생성한 증류 기반 데이터에 의존함(캡션, QA 등)
- 이것은 성능 향상에는 도움이 되지만, 시각 이해의 근원이 결국 폐쇄형 모델의 한계를 상속받게 됨
- Molmo는 사람이 이미지를 보고 자연스럽게 설명,질문,지시하는 과정을 데이터로 수집함으로써 모델에게 ‘인지 능력’을 확장시킴
3) 오픈형 VLM은 결국 어떻게 모델을 설계했냐에 따라 달려있다
- 단순히 가중치를 공개하는 것만으로는 proprietary VLM의 성능에 준하지 못함
- Molmo는 공개 가능한 데이터 + 공개된 weight LLM + 명확한 학습 레시피를 통해 독점 VLM의 증류 없이도 고성능 VLM 설계가 가능함을 보여줌
⇒ Open VLM 연구의 초점을 ‘어떤 모델을 쓰는가’에서 ‘어떤 데이터로 어떻게 학습시키는가’로 변화시킴
3. Architecture: Molmo
구조: Image → Pre-processor → ViT Encoder → Connector → LLM
(텍스트는 기존 LLM 토크나이저 그대로 사용)
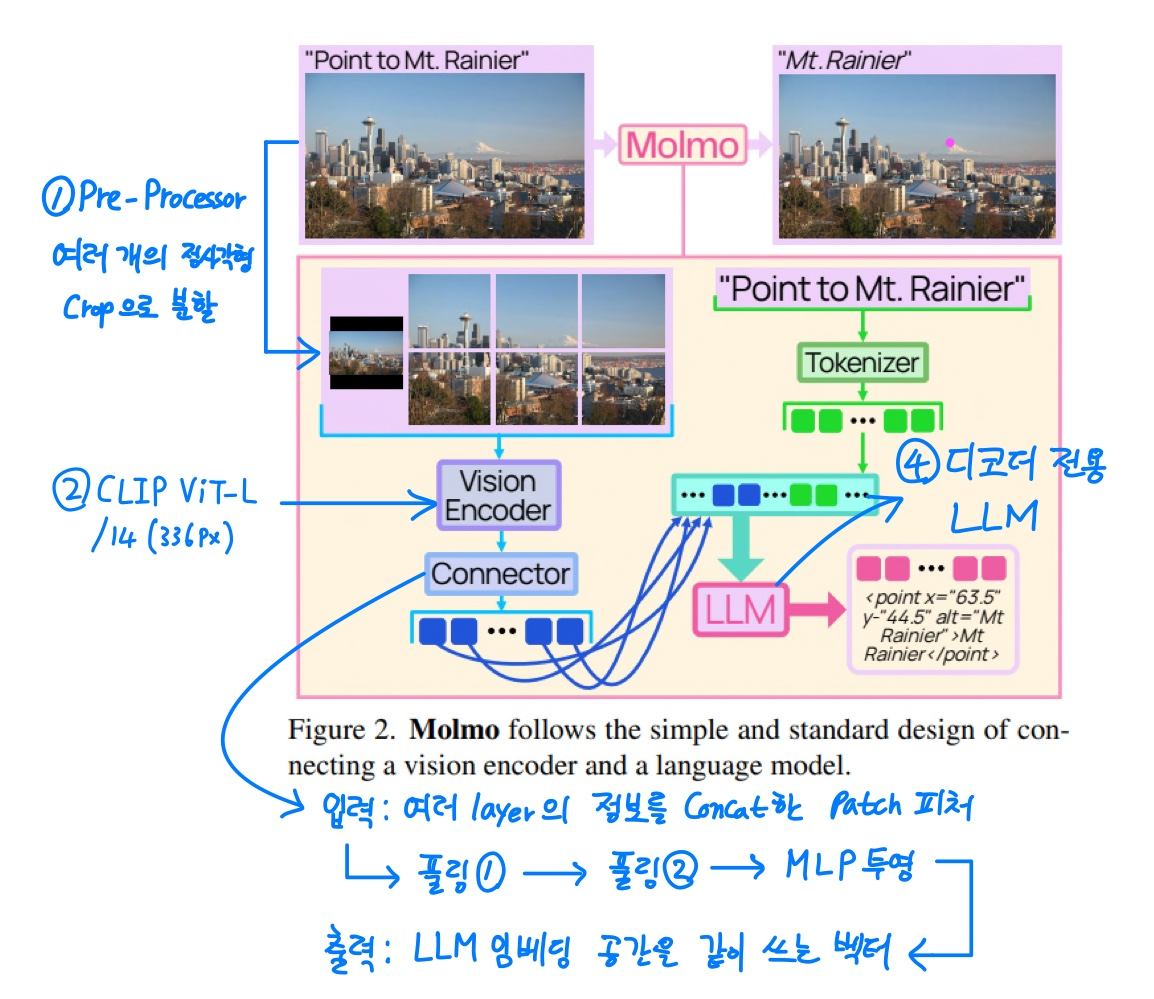
1) Pre-processor
- Multi-scale + Multi-crop: 전체 이미지(저해상도) + 잘게 나눈 여러 개의 정사각형 crop(고해상도)을 동시에 참고해, 전체 맥락 & 디테일한 요소를 동시에 봄
- Overlapping Crop 사용: Crop끼리 ‘살짝 겹치게’ 자름 → 경계 패치에서 문맥이 끊기는 현상을 방지 = 모든 패치는 최소 한 번은 충분한 문맥을 가지게 됨

2) ViT Encoder
- CLIP ViT-L/14(336px) 인코더를 사용
- ViT는 LLM과 관련 없이, 순수한 이미지 feature 추출기로 사용
3) Connector
- Input: 다양한 깊이의 layer 정보를 concat한 patch feature
- 풀링 1: patch window pooling (정보 압축)
- 풀링 2: attention pooling (어떤 정보가 중요한지 학습)
- MLP projection: 비전 feature를 LLM 임베딩 공간으로 변환
- Output: LLM의 텍스트 토큰과 같은 차원인 비전 토큰들
4) LLM
- 비전 토큰 + 텍스트 토큰을 같은 시퀀스로 받음
- LLM 구조는 기존의 일반적인 Decoder-only LLM을 사용
※ 특징 1) Vision 토큰 배열 방법
-
(left-to-right & top-to-bottom) + (Low-res full image → High-res crops) + (시작/끝, 줄바꿈 토큰)
⇒ 이미지의 공간 순서 따라 + 글로벌하게 보다가 디테일을 확인 + 2D 구조를 1D 시퀀스로 변환
※ 특징 2) 텍스트 전용 Dropout
- 종종 dense caption, QA 학습 시 LLM이 language prior에 의존하는 경우 발생
- Pre training 중에만 텍스트 토큰에 dropout → 훈련 중 이미지 정보를 더 잘 참고하도록 유도
※ 특징 3) 다중 주석 이미지
- 하나의 이미지 토큰에 여러 개의 QA 쌍을 가지게 설계 + 각 QA는 다른 QA들을 못 보게 설계
- 처리 이미지 수가 감소 + 학습 시간이 절반 이상 단축됨
4. Dataset: PixMo
총 7개 dataset = Human-annotated(3) + Synthetic(4)
1) Human-annotated(3개)
- Cap - 사람이 직접 말로 이미지를 설명한 캡션 → 구두적 설명으로 인해 시각 이해 능력의 뿌리를 다짐
- AskModelAnything - 사람이 던질 수 있는 모든 질문에 대응 → 실사용용 QA 분포에 가까운 데이터 확보
- Points - 사람이 직접 대상을 점(point)으로 가리킨 데이터를 수집 → 질문에 대한 답변을 point 형태로 빠르고 정확하게 제공할 수 있음
2) Synthetic(4개)
- CapQA - PixMoCap 캡션을 활용해 질문-답변 쌍을 생성함 → 캡션을 지식 소스로 쓰는 훈련을 수행
- Docs - 모델의 문서/차트/도표 이해력을 높이기 위해 → LLM이 이미지 생성 코드를 작성 후 렌더링
- Clocks - 모델의 시간 읽기 능력을 높이기 위해 → 시계 바디, 시계 페이스 데이터로 아날로그 시계를 읽는 법을 훈련함
- Count - 이미지에서 객체의 정확한 개수와 위치를 판단하기 위해서 → non-VLM object detector로 객체를 탐지하고, 해당 클래스에 포함된 인스턴스의 중심 좌표를 전부 추산한 뒤, 총량을 계산
5. Experiment Analysis
※ 핵심: Molmo는 ‘Score가 잘 나오게 만든 모델’이 아닌, 벤치마크와 실제 사용자 선호가 동시에 강함을 입증하려는 모델
1) Academic 벤치마크 (정량, 재현 가능)
- 매우 작은 모델(1B)부터 중간급 모델(7B)까지 독점 모델(GPT-4V, Claude)과 거의 동등한 성능을 달성
- 자연 이미지 QA, VQA, OCR에서 준수한 성능을 보여 ‘실제 사용자에게 강한 VLM’이라는 것을 증명함
- 특히 ‘Counting’ 지표가 압도적으로 높음 = Pointing 기반 학습과 point→count 방식의 효과가 명확함
2) Human 평가 (실사용 관점)
- Academic 벤치마크 결과와 human preference가 전반적으로 일관됨
- 이미지 설명, 자연 이미지 이해, counting/시각적 grounding에서 높은 사용자 선호도 기록
- 일부 모델(Qwen2-VL)은 벤치마크 성능에 비해 human 평가에서 낮은 선호를 보임
⇒ 항상 “벤치마크 최적화 = 사용자 만족”으로 이어지지 않는다는 점을 명확히 보여줌
3) Ablation: Model
- Vision 인코더는 CLIP / SigLip / MetaCLIP 간 성능 차이가 거의 없음
→ 비싼 proprietary 인코더 없이, 완전한 open형 인코더로도 충분히 경쟁이 가능 - 이미지 해상도 / Crop 수 증가 시 성능 향상 → 공간 정보, 시각적 디테일 요소는 여전히 중요한 역할
- 텍스트 dropout 진행 시 caption 성능의 개선 → 실제 모델의 시각 이해를 강화하는데 도움이 됨
4) Ablation: Data
-
PixMo-Cap 데이터 규모 증가에 따라 caption 성능과 벤치마크 성능이 일관되게 향상됨
-
Noisy한 대규모 데이터는 동일 규모에서도 효과가 제한적
⇒ 결국 데이터는 양보다 품질과 구성 방식이 더 중요하다
6. Significance of Paper
1) Open가중치&데이터로도 독점 모델에 준하는 VLM 구축이 가능함을 보여줌
- 본 VLM은 완전한 Open LLM + 비전 인코더 기반임에도 GPT, Claude 같은 독점 VLM과 경쟁 가능한 성능을 보임
- 특히 counting, 이미지 설명, 자연 이미지 이해 등 실사용적인 능력에서 독점 모델과의 격차를 크게 줄임
⇒ Open형 VLM 개발 분야에 ‘재현성’과 ‘확장성’을 갖춘 효율적인 방향을 제시함
2) VLM의 성능은 결국 고품질 데이터의 설계가 큰 비중을 차지한다
- PixMo-Cap, PixMo-AskModelAnything 같이 사람의 작업이 적극적으로 들어간 고품질 데이터셋은 noisy한 대규모 데이터보다 훨씬 효과적임을 보여줌
- 데이터 규모 보다 다양성, 질문 유형, 실제 사용자 질문과의 매칭이 VLM 성능에 더 큰 영향을 미침
- 향후 VLM 연구에서 데이터셋의 설계가 모델 구조만큼 중요한 부분이라는 것이 명시함
3) VLM 평가와 학습 패러다임에 대한 새로운 관점을 제시
- Molmo는 단순히 학술적 벤치마크 달성만이 아닌, 사람 선호와 실제 사용 시나리오까지 고려해 현실성을 중요시하였음
- VLM의 추론은 ‘LLM의 텍스트 추론’이라는 관점에서 벗어나, 시각적인 중간 추론 과정 자체를 학습시키는 방법으로 접근했음
- 결과적으로 Molmo VLM은 ‘무엇을 학습시키는가’ + ‘어떻게 평가할 것인가’에 대한 기준을 다시 생각해본 결과
7. Future Directions
1) PixMo의 확장: ‘확신도 판단’ 데이터셋
VLM이 아직 약한 능력: 불확실성 인식
- 여전히 VLM은 시각적 근거가 불충분하거나 애매한 상황에서도 답변을 생성하려는 경향이 있음
- 보이지 않음 ↔ 추론 불가 ↔ 확실함을 명확히 구분하지 못하는 상태
- VLM의 데이터셋에는 항상 정답이 존재하는 문제 위주였기 때문에, 모델은 답변을 생성하는 쪽으로만 최적화되어있음
아이디어: 대답 가능성을 판단하는 데이터셋
- 핵심: 사람이 이미지와 질문을 보고, ‘대답이 가능한지’를 먼저 판단하도록 하는 데이터셋
- 사람(어노테이터)에게 3가지로만 Label을 구성하도록 하게 하는 것 - 확실히 식별 가능 - 애매하거나 불확실 - 이미지로 알 수 없음
- 근거의 역할로, 이유(reason)도 같이 정답에 포함시키면 더욱 효과적일 것이라고 생각되어짐
- label: 애매하거나 불확실 / reason: 양손을 다 사용하고 있어 왼손잡이인지 모름
- label: 이미지로 알 수 없음 / reason: 얼굴이 가려져 있어 표정을 알 수 없음
- 이로 인해 모델이 이 질문은 ‘답변해야 하는지’ / ‘확신을 낮추고 답변해야 하는지’ / ‘답변을 거부하거나 유보해야 하는지’를 학습할 수 있을 것이라고 기대된다
Pros & Cons
- Pros: 모델 구조 변경 없이 데이터셋 중심 기여로 적용이 가능하다, 할루시네이션 현상을 구조적으로 완화할 수 있을 것 같다
- Cons: 필연적으로 어노테이션 비용이 증가할 것이다, 사람마다 ‘애매함’의 기준이 다르기 때문에 명확한 가이드라인이 필요할 것으로 보인다
