ICLR 2025.
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang
Show Lab, National University of Singapore | ByteDance
22 Aug 2024
💡 Key Point
하나의 트랜스포머 구조에서, 멀티모달의 이해(Understanding)와 생성(Generation)을 동시에 수행할 수 있을까?
1. Motivation
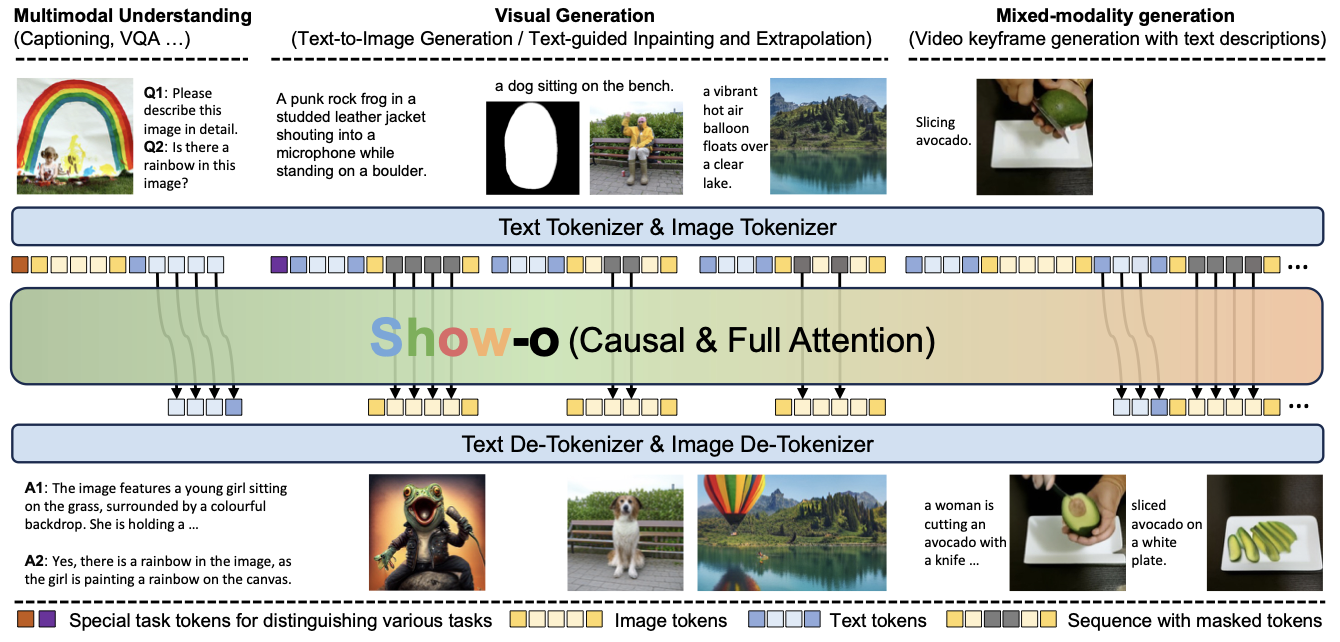
Comparison of Seperate model and Unified Model
- 최근 몇 년간, ‘멀티모달 지능’은 두 개의 핵심 task에서 상당한 발전을 이루어왔음
- 이해(understanding): 멀티모달 대규모 언어 모델(MLLM)이 등장해 VQA와 같은 비전-언어 작업에서 뛰어난 능력을 보임 (ex.LLaVA)
- 생성(generation): DDPM을 기반으로, 확산 모델이 text-to-image 분야에서 뛰어난 성능을 보임
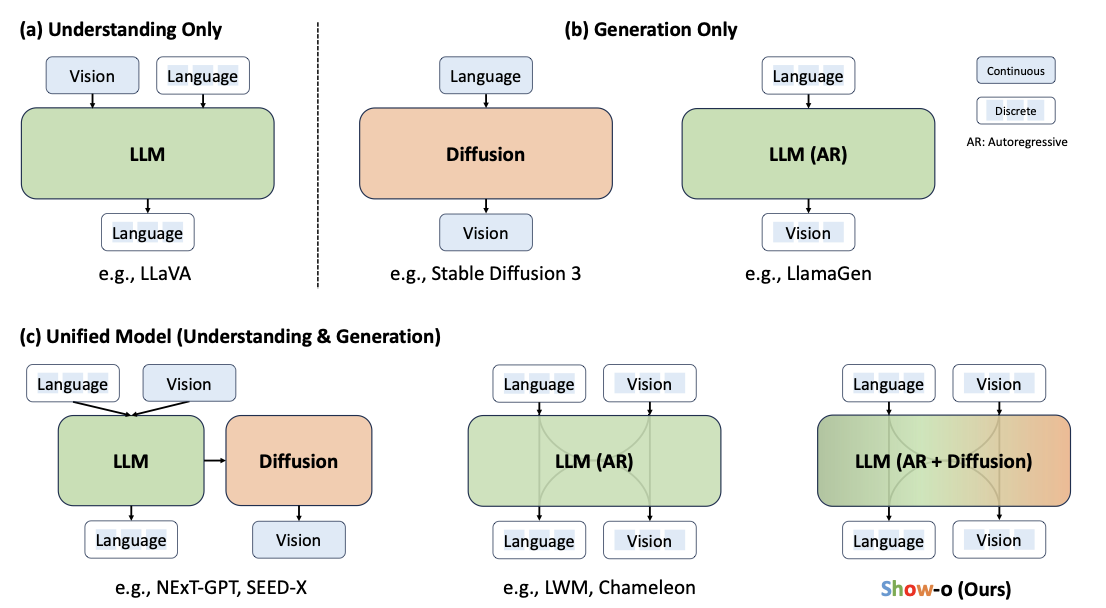
- 이후, ‘이해’와 ‘생성’의 task를 하나의 모델로 통합하려는 연구가 점차 시도되었으나, 완전히 하나의 구조로 최적화하는데는 실패하였음
- NExT-GPT, SEED-X: 이해와 생성을 독립적으로 취급해, 각 도메인이 통합되지 않고 개별 모델로 취급됨
- Team Chameleon: ‘Autoregressive 모델링’으로 텍스트와 이미지 토큰을 모두 다뤄보았지만, 이미지 토큰을 자기 회귀적으로 모델링하는 것은 확산 모델링보다 적합하지 않았음
- 또한 최근의 확산 모델은, 텍스트 조건을 처리하는 텍스트 인코더 + 노이즈 제거 네트워크라는 나누어진 구조에 크게 의존하고 있음
⇒ 즉, Discrete 텍스트 토큰과 Continuous 이미지 토큰은 표현에 상당한 차이가 있기 때문에 하나의 네트워크로 통합하는 것은 결코 쉬운 문제가 아님
2. Insight
1) 텍스트 토큰, 이미지 토큰을 모두 ‘Discrete’ 하게 모델링할 수 있다
- Show-o는 텍스트뿐 아니라, 이미지도 연속 latent가 아닌 discrete token으로 변환하여 하나의 같은 차원 공간에서 다룸
- 이를 통해 “텍스트는 LLM, 이미지는 diffusion”처럼 이질적인 표현 공간을 억지로 맞추지 않아도 됨
- 멀티모달 통합의 핵심 난제였던 표현 불일치(representation mismatch)를 구조적으로 단순화함
2) Autoregressive와 Diffusion의 역할을 자연스럽게 나눌 수 있다
- 텍스트는 causal dependency가 강하므로 autoregressive modeling이 적합
- 이미지는 전역적 상호 의존성이 중요하므로 (discrete) diffusion 방식이 더 효율적
- Show-o는 두 방식을 경쟁시키지 않고, 각 모달리티의 통계적 특성에 맞게 역할을 분담함으로써 통합 모델의 안정성을 확보
3) 하나의 트랜스포머에서, ‘이해’와 ‘생성’을 동시에 다룰 수 있다
- Omni-Attention을 통해 토큰 유형에 따라 causal / full attention을 동적으로 적용
- 이로 인해 VQA, Captioning(이해)과 Text-to-Image, Inpainting(생성)을 동일한 Transformer 구조로 처리 가능
- “이해용 모델 + 생성용 모델”이라는 기존 구조를 대체할 수 있는 통합 파운데이션 모델로 발전할 수 있음
3. Method
Overview of Show-o
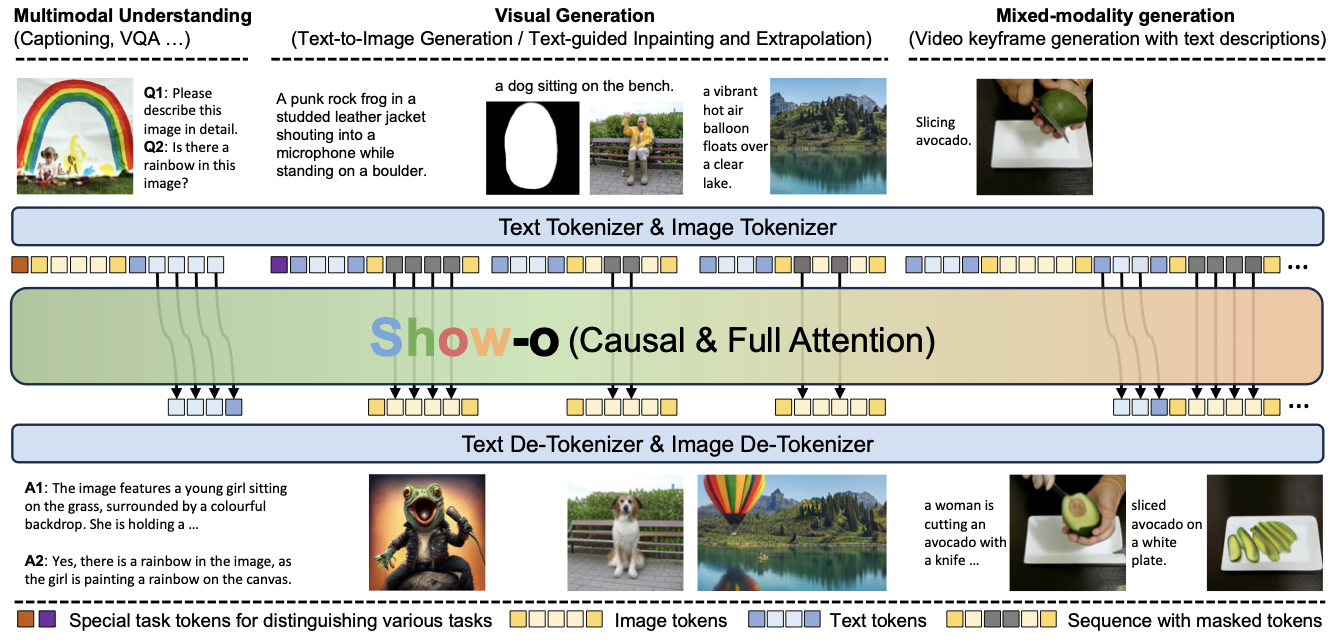
1) 이미지를 ‘Discrete’하게 토큰화
- Text Tokenization: pre-trained LLM을 그대로 사용하기 때문에 토크나이저 변경 없이 사용
- Image Tokenization: MAGVIT 기반의 양자화기로 이미지를 dicrete 하게 토큰화시킴
- MAGVIT-v2 Quantizer: 256 x 256 픽셀 → 16 x 16 discrete 토큰
- 대안 모델(CLIP, continous MAGVIT)로도 실험은 해봤지만 구조가 복잡해지고, ‘완전한 통합’과는 거리가 멀다고 판단하였음
2) 기존 LLM을 그대로 쓰되, 프롬프팅 방식과 어텐션 규칙만 바꾸기
기본 구조
- 기존 pre-trained LLM Transformer 구조를 그대로 사용하되, 두 가지 요소를 추가
- QK-Norm: 어텐션 레이어 앞에 추가해 학습 안정성+대규모 시퀀스 처리를 안정화
- 임베딩 확장: 기존의 텍스트 토큰에 새 이미지 토큰 8192개를 같은 임베딩 공간에 추가
- 별도의 텍스트 인코더 제거: 본 모델은 이미 텍스트를 이해하는 LLM임 → 텍스트 조건이 따로 인코딩될 필요 없이 이미 attention 안에 존재
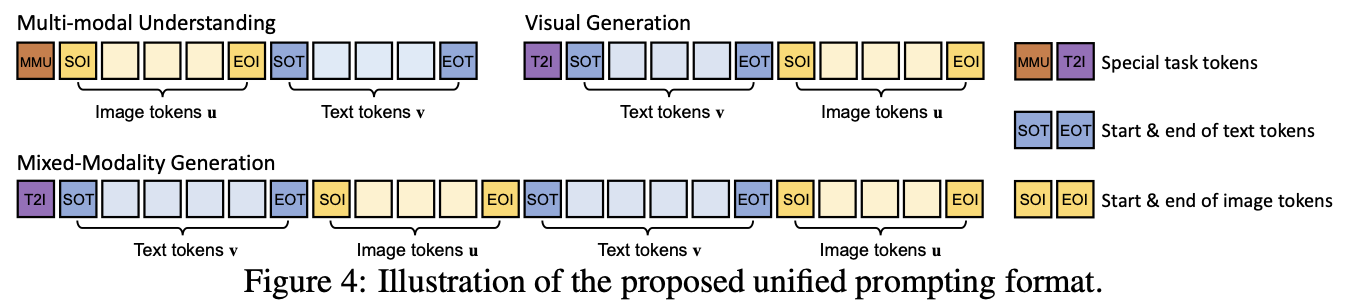
아이디어 1: Unified Prompting
-
핵심: 모든 Task를 토큰 시퀀스를 주고, 토큰 시퀀스를 예측하는 문제로 변경
-
방법: 각 토큰들을 그냥 섞는 게 아닌, 경계 토큰과 task 토큰을 두고 규칙있게 배열하는 방식
-
Task1: 멀티모달 이해
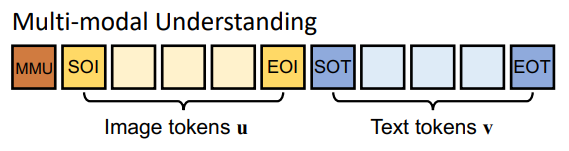
-
Task2: 이미지 생성
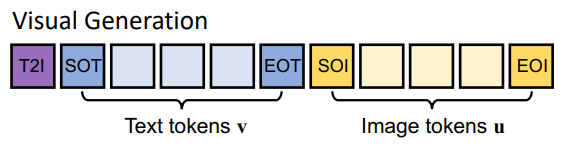
-
[MMU] : 멀티모달 이해 (VQA, Captioning)
-
[T2I] : 텍스트 → 이미지 생성
-
[SOT] / [EOT] : 텍스트 시작 / 끝
-
[SOI] / [EOI] : 이미지 시작 / 끝
-
⇒ 토큰을 일정한 양식을 두고 배치함으로써, 모델 입장에서 각 시퀀스가 어떤 task인지 프롬프트 토큰이 전부 알려주는 효과
아이디어 2: Omni-Attention
- 핵심: 텍스트 토큰은 그대로 causal하게, 이미지 토큰은 full하게 어텐션을 적용하자
- 텍스트: 문법/의미 등 순서에 의존적이므로 미래 단어를 보면 안됨 → Causal Attention
- 이미지: 픽셀/패치 등 전역적으로 동시에 구조를 참조해야함 → Full Attention
- VQA / T2I 등, 입력 시퀀스 구조에 따라 어텐션 규칙이 자동으로 바뀌는 것이 Omni-Attention
⇒ 하나의 어텐션으로 모든걸 처리하는 게 아닌, 모달리티의 성질을 어텐션에 반영하는 방식
3) 모델을 ‘하나의 토큰 예측 문제’로 바라본 Loss 설계
-
전제: Show-o는 두 가지 서로 다른 성질의 토큰을 다루기 때문에 Loss도 두 개로 나뉜다
1. Next Token Predictoin (텍스트용)
-
일반적인 LLM loss와 완전히 동일 → 다음 텍스트 토큰을 맞히는 것
-
텍스트를 왼쪽부터 하나씩 예측하나, 이미지 토큰은 조건으로 함께 제공
2. Mask Token Prediction (이미지용)
-
이미지 토큰을 일부 가리고, 다시 맞히게 함 → Discrete Diffusion 형태
순서 1. 초기엔 이미지 토큰 전부가 깜깜한 Mask로 채워진 상태
순서 2. 각 Mask 위치에 대해 ‘여기에 어떤 토큰이 가장 그럴듯한가’를 예측
순서 3. 일부 Mask만 선택적으로 복원: 확신이 높은 토큰부터 점진적으로 채움
-
여러 Mask 토큰을 병렬적으로 복원 + CFG로 조건을 얼마나 반영할지 조절
3. 전체 Loss
-
이미지 생성 능력(MTP)와 텍스트 이해/생성 능력(NTP)을 가중치 α로 조절
⇒ 텍스트 모델 위에 이미지 loss를 얹은 게 아닌 처음부터 두 목표를 함께 학습함으로써, 구조적으로 단순 + 이론적으로 일관 + 확장이 쉬운 모델로 설계
4. Experiment Analysis
1) Multimodal Understanding 성능 평가
- Show-o는 VQA, Captioning, Reasoning 같은 다양한 이해 task에서 기존 MLLM과 비슷한 성능을 달성
- 생성 모델과 통합된 구조임에도, 이해 성능이 크게 저하되지 않았음을 실험적으로 보여줌
- 소형 파라미터(1.3B) 모델에서도 준수한 성능을 보이며 unified 모델의 효과를 증명함
2) Visual Generation 성능 평가
- T2I 생성에서 AR기반 모델보다 현저히 작은 sampling step으로 고품질의 이미지를 생성이 가능함
- Discrete Diffusion 방법으로도 생성 효율 ↔ 시각적 품질 간의 밸런스를 조화롭게 유지함
- 텍스트 인코더+UNet 기반의 기존 diffusion 모델과 달리, 단일 구조임에도 준수한 생성 능력 보임
⇒ ‘이해’와 ‘생성’ task를 하나의 트랜스포머에서 동시에 효과적으로 수행할 수 있음을 뒷받침함
3) Unified 모델링의 효과 분석(Ablation)
- AR+ Discrete diff를 분리/통합한 실험을 통해, 두 방식의 결합이 성능에 큰 영향을 미친다는 것을 보임
- 이미지 토큰 표현(이산적 vs 연속적), 데이터 규모, 해상도 변화에 따른 실험으로 설계의 합리성을 증명
- 단일 트랜스포머 구조 내에서 causal attention ↔ full attention을 유연하게 활용 가능함을 보임
5. Significance of Paper
1) 텍스트+이미지 토큰을 모두 ‘discrete’하게 모델링해 하나의 시퀀스로 통합
- show-o는 텍스트와 이미지를 모두 discrete 토큰으로 변환해 통합적인 표현 방식을 제안함
- 이미지 생성을 continuous latent → discrete token ****예측 문제로 바꿔, 언어 모델과 같은 매커니즘 정의
- 모든 모달리티를 동일한 토큰 공간에서 다룰 수 있는 foundation model 설계 가능성을 제시함
2) Autoregressive & Diffusion을 유연하게 분리/공존시킨 논문
- 텍스트는 AR, 이미지는 Diffusion(discrete)으로 각 표현에 최적화된 생성 방식으로 결합
- 두 생성 방식을 단순히 결합한게 아닌 attention 레벨에서 유연하게 전환하는 방법을 보여줌
- 이를 통해 하나의 트랜스포머 내에서 추론과 생성을 충돌 없이 수행 가능함을 보여줌
3) 이해+생성+혼합 모달리티를 포괄하는 범용성
- VQA, Captioning, T2I, Inpainting, Mixed-modality generation까지 추가 ****fine-tuning 없이 지원
- 미래에 비디오 이해/생성, agent 기반 모델로 확장이 가능한 구조를 갖춤
- 여러 task를 하나의 트랜스포머 모델에서 수행 → 실용적 foundation 모델 가능성을 기대할 수 있음
6. Future Directions
1) 생성 결과물을 다시 이해로 넘기는 자기 검토
발단
- Show-o → 하나의 모델 안에서 ‘이해’와 ‘생성’을 모두 수행할 수 있는 통합 모델
- 그렇다면 모델이 생성한 이미지를 다시 ‘이해’ 모드로 넘기면 자신이 만든 결과물을 스스로 검증하고 수정하도록 만들 수 있지 않을까? → 결과물의 퀄리티를 한 단계 더 끌어올릴 수 있을까?
아이디어의 흐름
- 사용자가 텍스트 프롬프트를 입력하면 모델은 [T2I] 모드에서 discrete 이미지 토큰을 생성
- 이미지 생성 직후, 모델이 작업 모드를 [MMU] (멀티모달 이해)로 전환
- 모델이 생성한 이미지 토큰을 입력으로 넣은 뒤 스스로 검증하는 과정을 수행
- Ex) “이미지에 사과가 정확히 5개가 있어?”, “남성이 초록색 바지를 입고 있어?”
- 이해 단계에서 부정적인 답변, 확신도가 낮은 답변이 나올 경우, 모델은 오류가 발생했을 가능성이 높은 영역(토큰)을 추정
- 해당 영역을 다시 [MASK] 토큰으로 치환한 뒤, [T2I] 모드에서 해당 부분만 다시 재생성해 이미지를 수정
Pros & Cons
- Pros: 논문에서 언급된 물체 카운팅 오류, 텍스트 인식 실패 같은 생성 실패를 개선할 수 있음, 별도 외부 모델 없이 모델이 가진 능력을 루프로 활용하는 방식
- Cons: 모델의 이해 능력 자체가 부족한 경우, 잘못된 피드백으로 인해 이미지가 왜곡되거나 이상한 루프에 빠질 수 있음
2) ‘Discrete 토큰화 + 단일 토큰 시퀀스’ 패러다임 변경해보기
발단
- Show-o는 텍스트와 이미지를 모두 1) discrete 토큰으로 변환한 뒤, 2) 이를 하나의 토큰 시퀀스로 통합하여 단일 Transformer에서 처리한다
- 여기서, ‘discrete 토큰 시퀀스’ 방식 자체를 더 효율적으로 만들거나, 대체할 수 있는 다른 표현, 패러다임이 있을지 고민해보았다
생각 1: 텍스트를 continous하게 모델링?
기존 언어 모델은 텍스트를 토큰 단위의 이산적(시퀀스)으로 다루지만, 이를 연속적인 벡터 흐름으로 모델링할 수 있을까?
- 텍스트와 이미지를 모두 연속 벡터로 보고, 다음 토큰이 아니라 ‘다음 상태’를 순차적으로 예측하는 방식
- 텍스트와 이미지가 같은 표현 형태(continuous)를 가지게 하여, 멀티모달 통합을 더 자연스럽게 만들 수 있을 것 같다
생각 2: 텍스트와 이미지를 모두 diffusion으로 모델링?
Show-o에서는 텍스트와 이미지가 서로 다른 생성 방식(텍스트는 AR, 이미지는 diffusion)을 사용함
- 만약 텍스트와 이미지를 모두 diffusion으로 생성한다면 두 모달리티를 동일한 ‘생성 과정’으로 다룰 수 있을까?
- 즉, 텍스트와 이미지를 모두 노이즈에서 점차 의미 있는 형태로 복원되는 대상으로 취급해보는 시도를 해볼 수 있을 것 같다
관련 연구
[1] Dual Diffusion for Unified Image Generation and Understanding (2025, CVPR)
- 텍스트와 이미지를 모두 diffusion 기반으로 생성+이해하는 통합 프레임워크를 제안한 연구
[2] Continuous Autoregressive Language Models (arXiv preprint)
- 언어 모델링 자체를 연속 영역으로 옮기는 시도. 텍스트를 토큰 단위가 아닌 연속적인 의미 표현(latent)으로 다루며, 다음 언어 상태를 순차적으로 예측
