Machine Learning
머신러닝이란 아더 사무엘이 처음 사용한 용어로 제공된 정보를 기계가 학습하여,
학습한 정보를 기반으로 결과를 예측하거나 분류하는 등의 행위라고 할 수 있다.
심심이나 아키네이터같은 웹 상으로 체험할 수 있었던 간단한 서비스도 머신러닝이라고 할 수 있다.
엔트로피 (Entropy)
엔트로피란 정보의 무질서도를 나타내는 측도이다.
정보의 무질서도라는건 정보가 얼마나 여러가지인지? 라고 이해했다.
어떤 사건(event)이 특정 확률 분포로 일어나는데,
그 사건을 표현하는데 필요한 정보의 양을 나타내는 값이다.

예를 들어 10개의 빨간색 구슬과 6개의 파란색 구슬이 들어있는 구슬주머니를
엔트로피로 표현하면
Entropy = 이다.
파란색 구슬과 빨간색 구슬을 하나의 직선으로 구역을 나누어서 가장 낮은 엔트로피를 구하고 싶은 경우,
두개로 나눈 뒤 각 구역의 엔트로피 값을 구해서 둘이 더한 뒤 2로 나눈다.
그렇게 가장 엔트로피 값이 낮아지는 직선을 찾으면 된다.
지니계수
불순도율이라고도 부르며, 계산량이 엔트로피보다 더 작다.
계산량이 작다는 장점 때문에 엔트로피보다 선호되기도 한다.
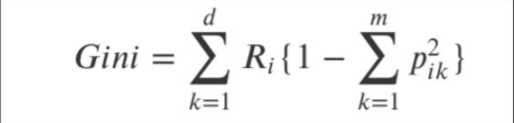
위에서 이야기한 16개의 구슬 주머니의 지니계수는
이다.
Scaler
Encoder
CS에서는 정보를 다른 형식으로 바꿔주는 걸 encoding, decoding이라고 한다.
머신러닝에서 encoder가 해주는 역할도 비슷하다. dataset의 특정 정보를 다른 형식으로 변환해준다.
1. Label Encoder
label encoder는 문자를 숫자로 바꾸어준다.
우리가 머신러닝 모델을 사용할 때, 문자형 변수는 사용할 수 없다.
그렇기 때문에 문자형 변수의 값을 각각 숫자로 매핑하여 변환시켜준다.
하지만 단순 명목형 변수에만 사용하는걸 추천한다.
왜냐하면 문자를 숫자로 매핑할 때, 문자순으로 정렬하여 숫자를 매핑하기 때문이다.
순위나 정도를 매핑하려할 경우 "good"이 "well"이나 "soso"보다 작은 값을 가지게된다.
2. One Hot Encoder
one hot encoder는 명목형 변수에 존재하는 카테고리 별로 컬럼을 만들어 0또는 1로 값을 매겨 컬럼을 추가해주는 방법이다.
예를 들어, drink라는 column이 coke, juice, bodka라는 값으로 존재하였다면
coke, juice, bodka라는 컬럼을 각각 만들어 해당하는 컬럼에 1, 아닌 컬럼에 0을 저장하는 방식이다.
-
Min Max Scaler
min max scaler는 컬럼의 모든 값을 1과 0사이의 값으로 축소시켜주는 방법이다.
각 컬럼의 최대값과 최소값을 먼저 찾아내, 각각의 값에 최소값을 빼준 뒤,
최대값과 최소값의 차이로 나눠준다.
-
Stadard Scaler
우리들에게 가장 익숙한 표준 정규분포로 정규화하는 방법이다.
x에서 평균을 빼준 뒤 표준편차로 나눈다. -
Robust Scaler
robust는 다른 scaler들과 크게 다른점은 극단값에 대한 영향을 제거한다는 점이다.
그렇기 때문에 median에 집중하는데, 보통 극단값을 삭제하거나 처리해주지 못한 경우에 사용한다.
어떤 scaler를 사용해야지! 하고 골라서 사용하기보다 전부 사용해보고 비교해서 고르는것이 좋을 듯 하다.
