
크롤링의 응용
앞서 여러 게시글에서 bs4 나 selenium 을 사용한 크롤링 방법을 알아봤습니다.
이번엔 크롤링으로 데이터를 모으고, 그 데이터를 기반으로 간단한 시각화를 해보겠습니다.
제가 작성한 코드입니다. 해당 코드를 기반으로 설명하겠습니다.
(https://github.com/now2466/Python_codes_for_Data_Science/blob/1491c99e3cf9f356e09ceb2048c64a967deeea52/Code_for_Crawling_google_images)
저는 anaconda jupyter notebook 환경에서 작성했기 때문에 제가 작성한 셀별로 설명을 하겠습니다.
jupyter를 사용하지 않는 분들은 ipynb파일을 다운받으셔서 colab으로 실행하시면 됩니다.
우선 스타벅스 드라이브스루 지점의 정보를 크롤링해오겠습니다.
from selenium import webdriver import warnings warnings.simplefilter(action="ignore") import time import pandas as pd driver = webdriver.Chrome("../driver/chromedriver.exe") url = "https://www.starbucks.co.kr/store/store_map.do" driver.get(url) time.sleep(2)실행 결과 :
우선 첫번째 셀입니다, 기본적으로 필요한 selenium webdriver 와 time을 import해주고, 현재 selenium을 사용하면 코드엔 문제가 없으나 경고문구가 나타나는데, 해당 경고문구를 없애주기 위해 warnings를 import해와서 ignore을 설정해줍니다.
이전 게시글에서도 설명드렸듯이, selenium을 사용하기 위해선 파이썬파일이 존재하는 폴더에 크롬드라이버가 함께 있거나 크롬드라이버의 상대/절대 경로를 명시해주어야 합니다.
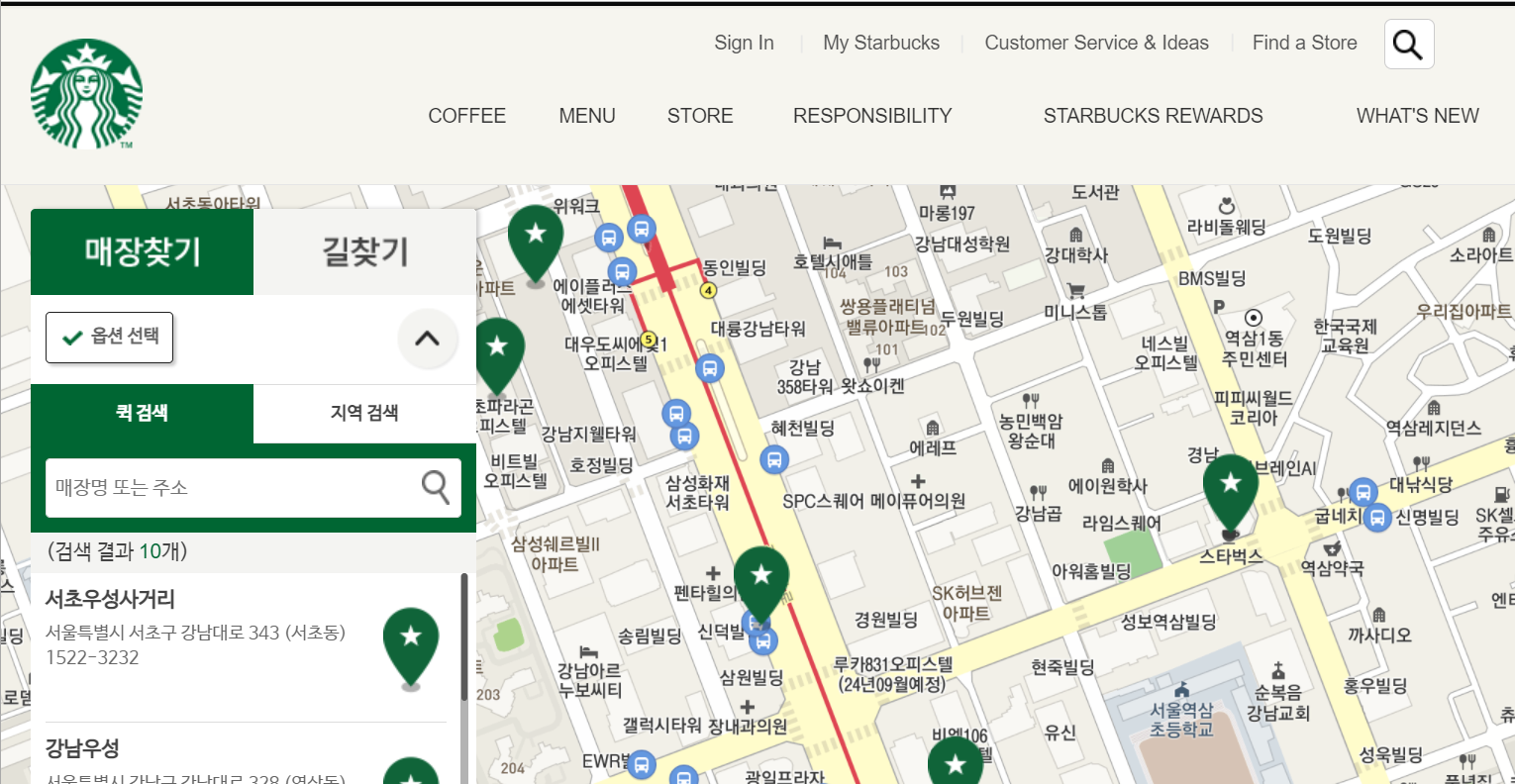
url 변수에는 스타벅스의 지점 검색 페이지를 주어서 실행시켰습니다.
driver.find_element_by_css_selector("#container > div > form > fieldset > div > section > article.find_store_cont > article > header.loca_search > h3 > a").click() #지역검색 버튼 누르기 time.sleep(1) driver.find_element_by_css_selector("#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a").click() #서울 누르기 time.sleep(1) driver.find_element_by_css_selector("#mCSB_2_container > ul > li:nth-child(1) > a").click()실행 결과 :
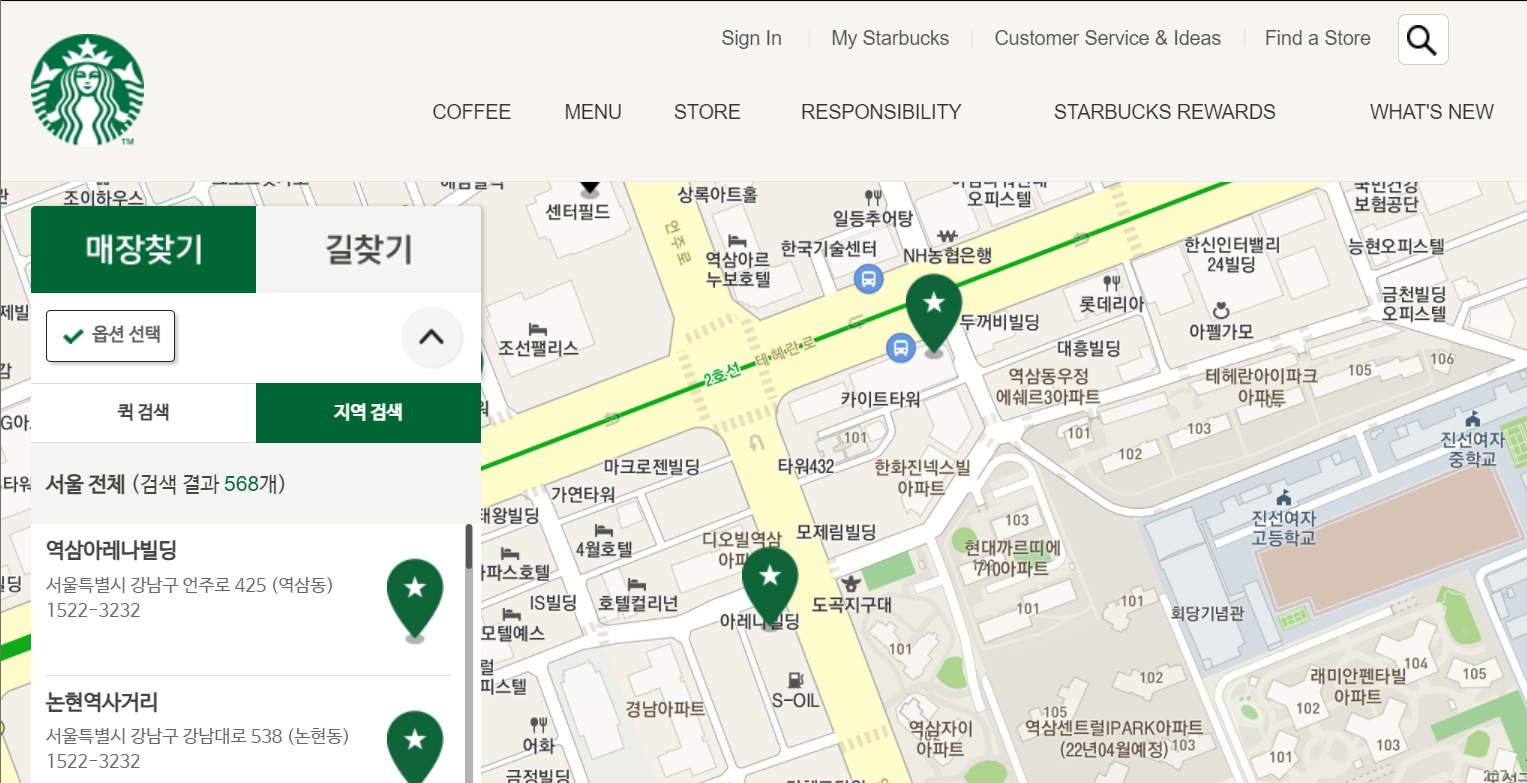
해당 코드는 매장 찾기에서 지역검색 설정 후 서울을 선택하는 코드입니다.
#옵션버튼 누르기 time.sleep(1) driver.find_element_by_css_selector("#container > div > form > fieldset > div > section > article.find_store_cont > header > p > a").click() time.sleep(2) #드라이브스루 누르기 driver.find_element_by_css_selector("dl.opt_select_dl1>dd.right>.icon02").click()실행결과 :
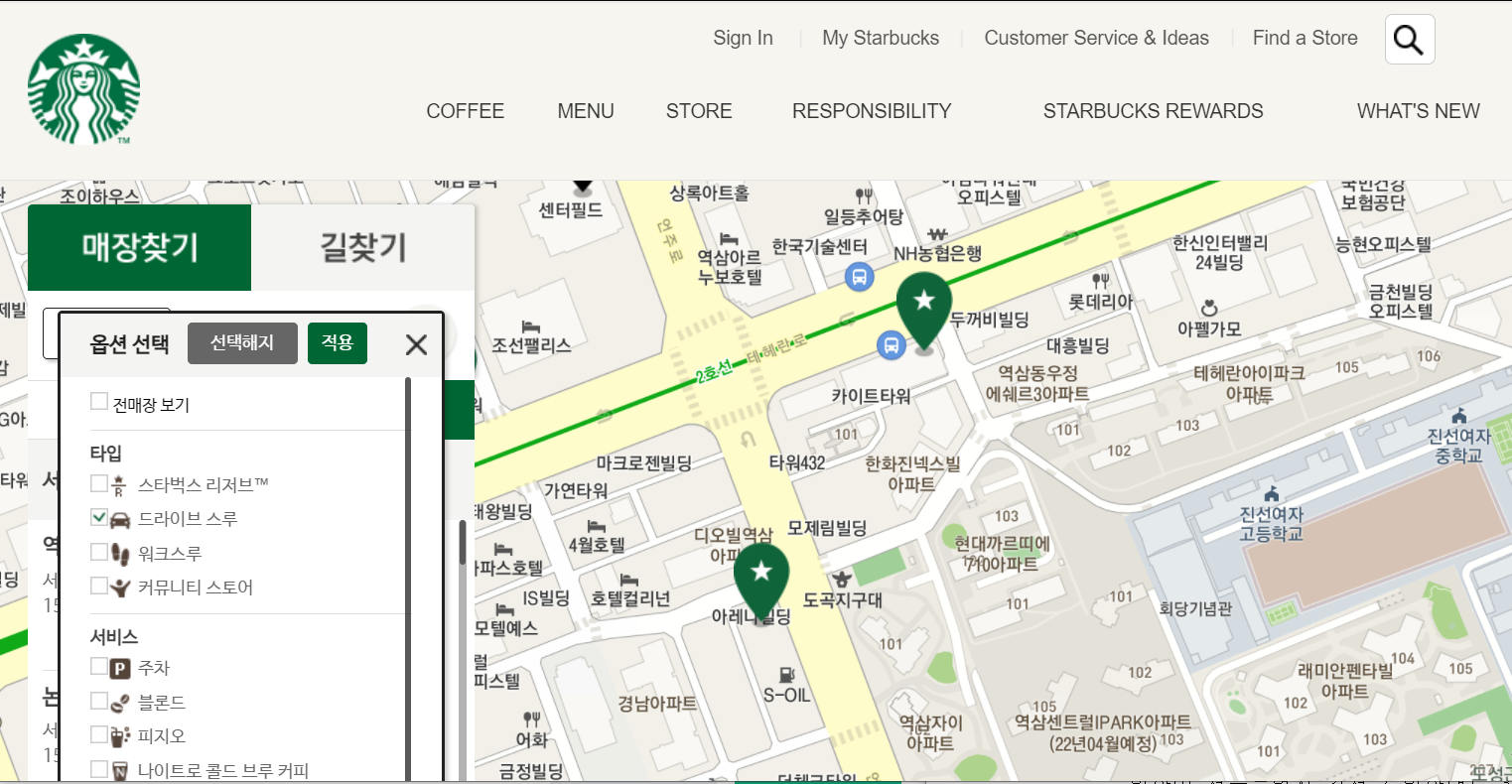
해당 코드는 옵션 버튼 클릭 후 드라이브 스루를 선택하는 방법입니다.
모든 css요소는 개발자도구에서 css selector를 복사해와서 사용하였습니다.
버튼은 여러개가 있으니 원하는 버튼의 css만 선택할 수 있도록 class나 id를 잘 선택하고 사용해야 합니다.
driver.find_element_by_css_selector("#storeMap > form > fieldset > div > ul > li.li2 > a").click() #적용버튼 누르기실행 결과 :
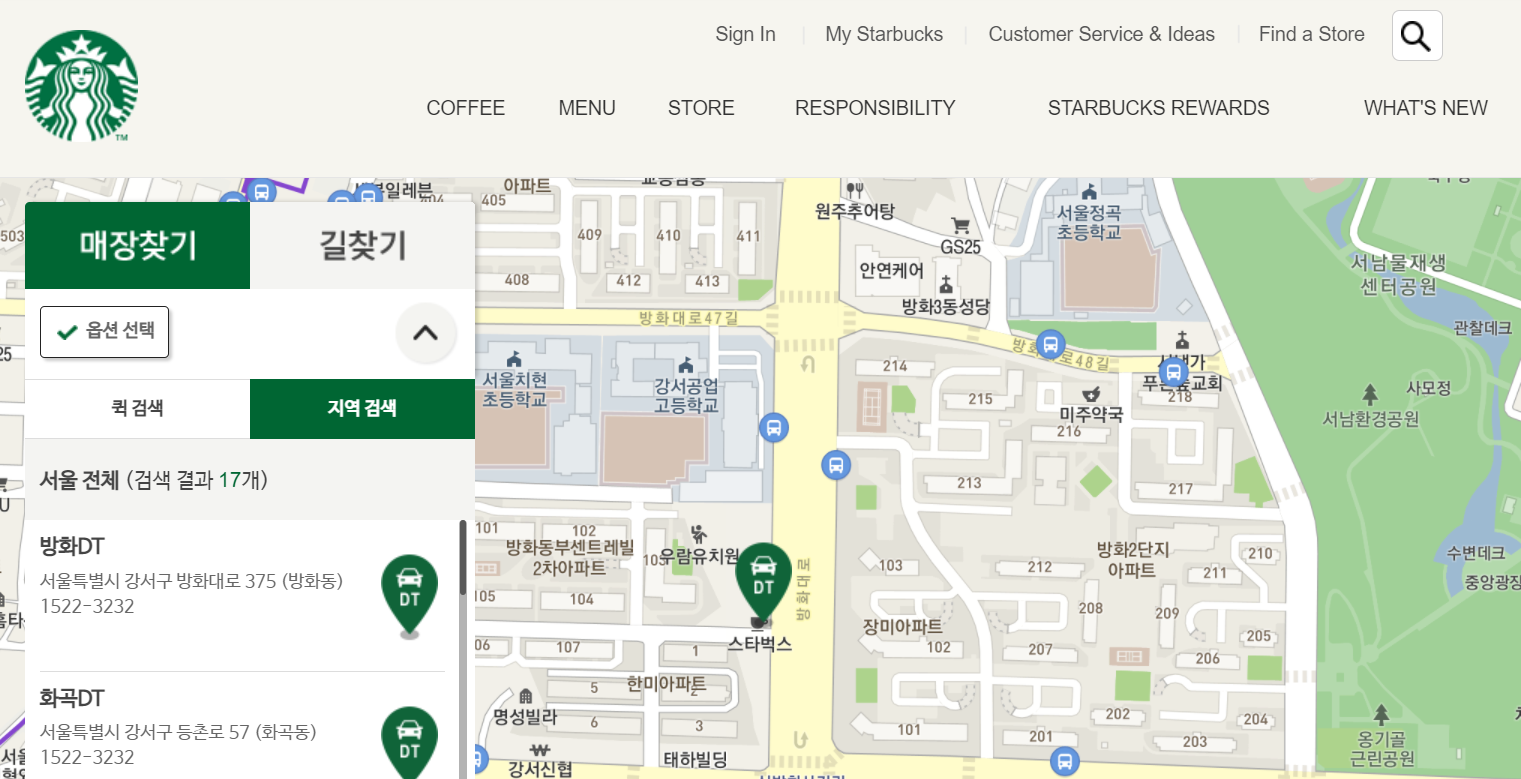
그 다음 적용 버튼을 누른 결과입니다.
짧은 코드이지만 ui의 변화 과정을 보여드리고 싶어서 따로 실행했습니다.
그 다음, 위 사진의 좌측 하단에 보이는 검색 결과 17개를 크롤링할 차례입니다.
하지만 크롤링을 해보면 아시겠지만 한가지 문제가 생깁니다.
먼저 지점의 이름, 주소에 관한 css를 간단히 설명해드리면,
"#mCSB_3_container > ul > li:nth-child(1)" 라는 css구조로 이루어져있습니다.
mCSB_3_container라는 id를 가진 태그의 자식태그인 ul(unoldered list)가 있습니다.
리스트니까 자식들이 여러개가 존재할 것이라고 유추할 수 있는데, 바로 이 리스트가 지점들의 정보를 담은 리스트입니다.
그리고 자식으로 li:nth-child(1)라는 부분이 바로 자식을 나타내는 부분입니다.
nth-child(n)은 부모태그의 밑에 여러개의 자식태그가 있을 경우, id나 클래스로 구분하기 보단, nth-child라는 문법을 사용하여 부모태그 밑에서 몇번째로 존재하는 태그 라는 의미를 나타냅니다.
현재 다루고있는 태그를 예시로 들어 설명하자면, ul이라는 부모태그의 하위태그에 li라는 자식 태그가 여러개가 존재하는데, 그 li중 1번째로 있는게 li:nth-child(1)입니다.

사진 속에서 빨간색원이 부모태그, 파란색 원이 자식태그입니다.
우리가 찾은 li:nth-child(1)이 바로 빨간색 원 발로 밑의 파란색 원이 쳐진 li요소입니다.
해당 li의 data-name이 방화DT인것을 볼 수 있습니다.
data = driver.find_element_by_css_selector("#mCSB_3_container > ul > li:nth-child(1)") data.get_attribute("data-name")실행 결과 :
방화DT
이렇게 css요소가 정확한것을 확인할 수 있었습니다.
그렇다면 다른 지점들까지 모두 데이터를 가져오고 싶다면 어떻게 하면 될까요?
바로 :nth-child를 지워주고, 함수를 find_element_by_css_selector 에서 find_elements_by_css_selector 로 바꾸어주면 됩니다.
data = driver.find_elements_by_css_selector("#mCSB_3_container > ul > li") name_list = [name.get_attribute("data-name") for name in data] lng_list = [lng.get_attribute("data-long") for lng in data] lat_list = [lat.get_attribute("data-lat") for lat in data] print(len(name_list),len(lng_list),len(lat_list)) print(name_list[16],lat_list[16],lng_list[16])실행 결과 :
17 17 17
강동암사DT 37.555054 127.130065
사실 이 방법 이전에 css selector를 사용하여 지점의 이름, 주소를 가져온 후, 주소를 google maps api를 이용하여 lat,lng 좌표를 가져왔었는데, lat, lng좌표 값이 태그의 속성값으로 지정되어있어서 직접 가져왔습니다.
그리고 지점 이름과 주소를 속성 값이 아닌 태그의 text를 가져오려할때는 검색결과의 스크롤을 내려주지 않으면 빈 값이 크롤링 되었었는데, 속성값은 스크롤을 내리지 않아도 모든 값이 제대로 크롤링 할 수 있어서 시간을 절약할 수 있었습니다.
new_df = pd.DataFrame({"title":name_list,"lat":lat_list,"lng":lng_list}) new_df.head()실행 결과 :
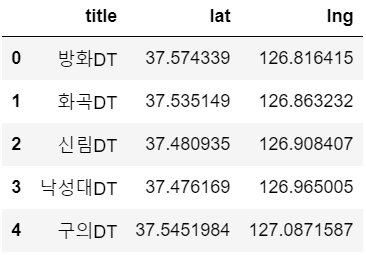
이렇게 스타벅스 DT 지점들의 지점명, 좌표 크롤링이 끝났습니다.
맥도날드 크롤링
url = "https://www.mcdonalds.co.kr/kor/store/list.do" driver.get(url)실행 결과 :
맥도날드 페이지로 이동해줍니다.
url변수에 맥도날드 지점찾기 페이지를 저장했습니다.
맥도날드는 검색어를 서울로 입력하고 검색하면 제대로 검색이 되지않아서 구별로 성북구, 강북구 이런식으로 입력해서 검색을 일일이 해줘야했습니다.
그리고 검색할 때 마다 드라이브 스루 버튼을 눌러주지 않으면 드라이브 스루 지점만 검색이 되지않았는데, 가장 이상했던 점이 있습니다.
압구정 DT점은 드라이브 스루 버튼을 누르지 않은 채로, 강남구만으로 검색하면 검색 목록에 나타나지 않습니다.
때문에, 드라이브 스루 버튼을 검색시 필수적으로 누르도록 코드를 추가해줬습니다.
# 모든 구의 이름을 직접 저장했습니다 real_gu = ["강남구","강동구","강북구","강서구","관악구","광진구","구로구","금천구","노원구","도봉구","동대문구","동작구","마포구","서대문구","서초구","성동구","성북구","송파구","양천구","영등포구","용산구","은평구","종로구","중구","중랑구"] macs = [] for gu in real_gu: print(gu) try: driver.find_element_by_css_selector("#searchWord").clear() except: pass driver.find_element_by_css_selector("#searchWord").send_keys(gu) driver.find_element_by_css_selector("#searchForm > div > div > div > span:nth-child(2) > label").click() driver.find_element_by_css_selector("#searchForm > div > fieldset > div > button").click() time.sleep(1) dt_list=driver.find_elements_by_css_selector("#container > div.content > div.contArea > div > div > div.mcStore > table > tbody > tr") for data in dt_list: tmp = data.find_element_by_css_selector("td.tdName > dl > dt > strong > a") lat,lng = tmp.get_attribute("href")[19:-2].split(",") #원문이 javascript:moveMap(37.5667729,126.9794809); #형식이기 때문에 앞에 구문을 지워주고, ","를 기준으로 split해서 저장. title = tmp.text text = data.text if("서울" in text and "맥드라이브" in text): macs.append({ "title":title, "lat":lat, "lng":lng })실행 결과 :
강남구
강동구
강북구
강서구
관악구
광진구
구로구
금천구
노원구
도봉구
동대문구
동작구
마포구
서대문구
서초구
성동구
성북구
송파구
양천구
영등포구
용산구
은평구
종로구
중구
중랑구
이번엔 코드가 한눈에 보기에 좀 길기 때문에 코드 사이사이에 주석을 달았습니다.
사용한 메소드를 보면, clear() 함수는 해당 요소가 값을 입력받는 요소라면 , 해당 요소에 입력되어있는 값을 비우는 함수입니다.
검색을 반복해야하기 때문에 검색 입력창을 비워주고, 구 이름을 입력한 뒤 검색 버튼을 눌러줍니다.
검색 결과로 나오는
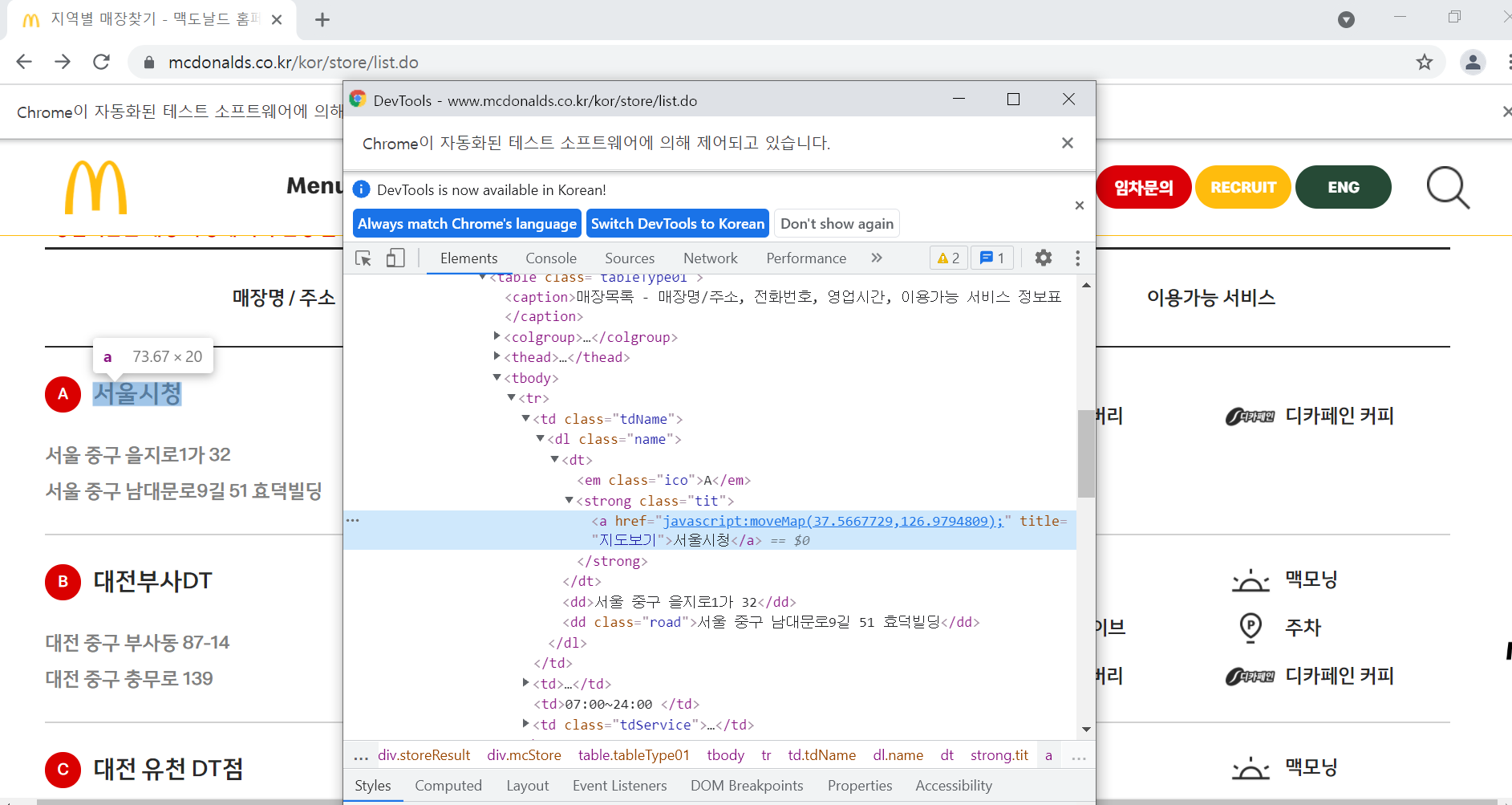
이런 화면에서 저 서울시청이라는 지점명과 css요소의 속성값으로 존재하는 위도, 경도 좌표를 가져왔습니다.
중구는 서울뿐만 아니라 여러 지역에 존재하고, 또 드라이브스루점이 아닌 지점도 나오는 경우가 많기 때문에, 필터링을 통해 크롤링을 해주어야합니다.
일반적인 html의 구조이며, 해당 페이지에도 적용된 태그인 table항목의 tr(table row)별로 크롤링을 해주면, 저 사진속의 서울시청에 해당하는 모든정보, 대전부사DT의 모든 정보가 tr속에 들어있는데, 해당 tr의 text를 추출하면
'A서울시청\n서울 중구 을지로1가 32\n서울 중구 남대문로9길 51 효덕빌딩\n070-7017-0155\n07:00~24:00\n맥딜리버리\n맥모닝\n디카페인 커피'이런 문자열로 추출이 됩니다.
해당 문자열에 서울이라는 단어가 포함되는지, 맥드라이브가 포함되는지를 통해 필터링을 해주었습니다.
총 25개의 항목들로, 모두 주소가 서울이고, 맥드라이브 항목을 갖는 데이터들입니다.
이제 데이터들을 합쳐줄 차례입니다.
mac_df["brand"]="mcdonals" new_df["brand"]="starbucks" all_data = pd.concat([new_df,mac_df]) all_data실행 결과 :
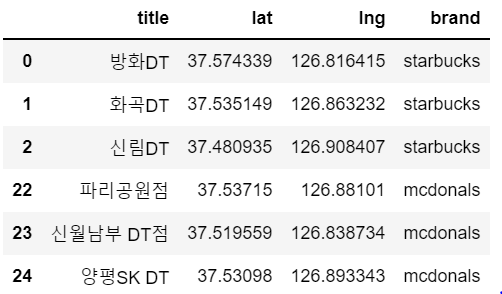
이제 좌표들을 이용하여 시각화를 해줄 차례입니다.
m = folium.Map( location = [37.555064263408916, 126.98780752799638], zoom_start=11 ) for idx,rows in all_data.iterrows(): if(rows["brand"]=="starbucks"): folium.Marker( location = [rows["lat"],rows["lng"]], tooltip = rows["title"], icon=folium.Icon(color='green',icon='star') ).add_to(m) else: folium.Marker( location = [rows["lat"],rows["lng"]], tooltip = rows["title"], icon=folium.Icon(color='red') ).add_to(m) m실행 결과 :
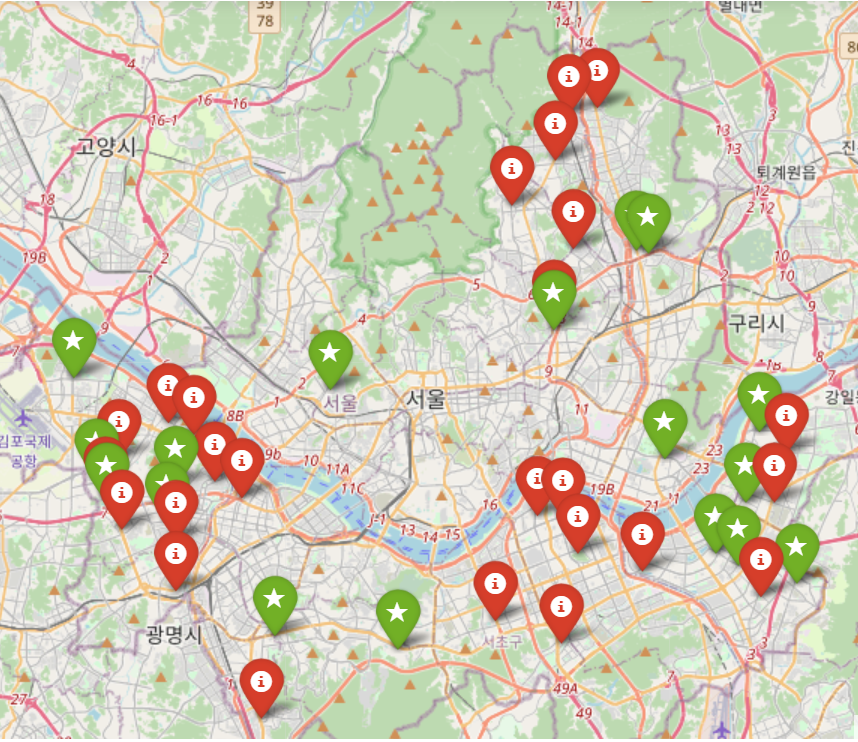
folium을 사용해 지도에 가게별 위치를 표시해주고, 브랜드별로 마커의 색을 다르게 설정해주었습니다.
간단하게 folium의 메소드들을 설명하자면, folium.Map() 은 location 이라는 인자에 지도의 중점으로 설정할 좌표를 입력해주고, zoom_start 라는 인자로 어느정도 확대할지를 설정해줄 수 있습니다.
다음으로는 folium.Marker() 라는 함수인데, location 인자뿐만 아니라, tooltip 이라는 인자에 문자열을 주어서, 마우스 커서를 마커에 올렸을 때 tooltip 으로 넘겨준 문자열이 나타나도록 할 수 있습니다.
또한, icon 인자를 통해 색깔, 마커에 표시되는 그림을 지정해줄 수 있습니다.
