
Pandas란?
대부분의 데이터 분석, 엔지니어, 사이언스 등의 직무를 희망하시는 분들이 파이썬 공부를 시작할때 가장 먼저, 많이 배우는게 Pandas 일 것이라고 생각합니다.
파이썬에서 데이터를 다루는데 가장 쉬운 도구가 되어주며 데이터 분석 프로그래밍 언어인 R 을 따라서 만든 라이브러리 입니다.
저는 파이썬으로 데이터를 다루기 이전에, R을 먼저 수업에서 사용하여 R를 먼저 사용해보고 Pandas를 공부하기 시작해서 DataFrame 개념을 인지한채로 시작해 이해하기 좀 더 수월했던 것 같습니다.
"Pandas는 스테로이드를 맞은 엑셀이다"라는 이야기가 있다는데, 과연 R에서 사용하는 DataFrame이나 Tibble 보다 더 다루기 쉬운지는 배우면서 알아봐야 할 것 같습니다.
먼저 Pandas에서의 가장 대표적인 자료구조는 DataFrame과 Series입니다.
import pandas as pd df = pd.DataFrame(....) series = pd.Series(....)
DataFrame 은 1개 이상의 column 과 1개 이상의 row로 이루어져있으며 흔히 알고있는 행렬과 같은 형태입니다.
Series는
기존에 list 형태 또는 dict 형태로 존재하던 데이터를 Series로 만들어줄 수 있습니다.
dict 자료형과 마찬가지로, 인덱스 와 데이터 가 1대1 대응되는 형태입니다.
DataFrame은 Series 여러개가 이루어져서 만들어진 행렬 , matrix 라고 이해할 수 있으며, R 에서 동일한 이름을 가진 dataframe 으로 생각하면 됩니다. r 에서는 c()를 이용해서 만든 array들을 cbind()나 rbind() 함수를 사용하여 행렬을 만들어주고 data.frame() 혹은 tibble()함수로 만들어줄 수 있습니다.(tibble은 tibble 라이브러리 패키지가 필요합니다)
s1 = [1,2,3,4] s2 = [5,6,7,8] s3 = [9,10,11,12] df = pd.DataFrame([s1,s2,s3],index = ["a","b","c"])
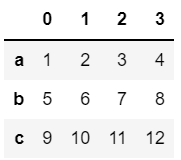
단순하게 series를 사용하지않고 list들을 사용해 위와 같은 형태로 만들 수 있습니다. index = 는 인덱스로 지정하고 싶은 명칭이나 column을 줘도 됩니다. 명칭을 직접 명시하고 싶은 경우는 예시처럼 list로 넘겨주어도 되지만 데이터 수가 많아질 경우 굉장히 불편해집니다. 그럴때 중복되지않고 데이터의 이름을 나타내는 column이 존재한다면 그 column을 사용하면 됩니다.
df = pd.DataFrame([ ["a",1,2,3], ["b",4,5,6], ["c",7,8,9], ["d",10,11,12]] ) df = pd.pivottable
위 예시와 같이
pivottable을 사용하면 기존 컬럼을 index로 바꾸어줄 수 있습니다. 엑셀에 익숙하신 분이라면 pivottable이 익숙하실 수도 있는데 pivottable 함수에 관해서는 다음에 자세히 다루도록 하고 지금은 index를 바꾸어주는 방법만 보고 넘어가겠습니다.

데이터 다루기 기초
R 을 다루면서 아주 많이 사용했던 함수가 있습니다. 바로 head() 와 tail() 입니다. matrix의 상위 5개 혹은 하위 5개 데이터를 보여주는게 default인 함수입니다.
이러한 두 함수가 pandas에도 존재합니다.
df.head()를 통해서 df의 상위 데이터 5개를 확인할 수 있으며 제가 현재 만들어둔 df는 4개의 데이터를 갖고있기 때문에 5개보다 적은 갯수의 매개변수를 주어 실행해보겠습니다.
df.head(2) df.tail(3)
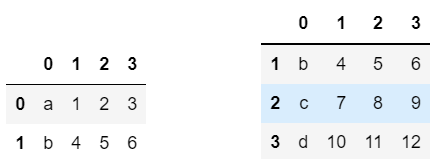
실행 결과입니다.
tail을 이용하면 인덱스의 끝이 어디인지를 유추할 수도 있습니다.
데이터를 간단히 확인해봤는데 데이터의 순서가 뒤죽박죽이어서 보기 힘든 경우 sort_values() , sort_index() 함수를 사용하여서 정렬해줄 수 있습니다.
sort_values() 의 경우 정렬하는 기준 컬럼을 지정해줄 수 있으며, 해당 컬럼에서 중복되는 값이 있을경우 기준 컬럼을 1개 이상 주어서 n번째 기준 정렬까지 명시할 수 있습니다.
by = 로 기준이되는 컬럼을 매개변수로 넘겨줄 수 있고, ascending = 으로 오름차순 정렬, 내림차순 정렬을 정해줄 수 있습니다. 앞서 만든 df가 오름차순이기 때문에 내림차순으로 정렬을 해보았습니다
df.sort_values(by=1,ascending=False)

위 사진처럼 1 컬럼을 기준으로 내림차순 정렬이 된 것을 알 수 있습니다.
컬럼삭제
이렇게 데이터를 읽어보고 정렬시켜보고 하던 도중 데이터 속에 불필요한 컬럼이 존재하는 경우가 있습니다. 그런 경우를 위해 del 과 drop 을 사용할 수 있습니다
del df[3]
df.drop(labels=2,axis=1) #labels를 생략해도 가능


슬라이싱
drop에서의 매개변수인 axis는 축을 알려주는 매개변수로 0이 가로, 1이 세로다. 즉 데이터를 하나 없앨지, 컬럼을 없앨지를 결정할 수 있다.
컬럼을 삭제했더니, 이번엔 불필요하거나 결측치가 존재하는 데이터가 있어 빼고싶다. 이런 경우에는 데이터를 삭제하면 원본 데이터가 손실되는 것이니 사용할 데이터의 인덱스만 선택하여 새로운 변수에 저장할 수도 있다. 여기서 쓰는게 인덱스 슬라이싱이다.
loc 와 iloc 두개로 나뉘는데 loc 는 명칭, iloc 는 숫자로 생각하면 이해하기 쉽다.
그것외에 가장 기본적으로 사용하는 인덱스 방식인 offset index 가 있다.
가장 기본적인 파이썬 문법중 하나로 대부분의 자료형에서 사용된다.
offset index
df[0:3] df[0::2]

df[0:3]은 첫번째 인덱스부터 2번째 인덱스까지의 데이터를 출력하는 것이고, df[0::2]는 처음부터 끝까지 2개씩 이동하면서 출력해준다는 의미이다
data[start:end:n] 으로 생각하면 쉽다. 시작, 끝, 이동간격.
물론 이동간격의 default값은 1이고, :을 한개만 써준다면 한 데이터씩 출력한다.
처음부터 끝까지가 아니라 중간부터 n번째까지도 물론 가능하다.
또한 -를 이용할 수도 있습니다.
df[-1:] df[:-1]위 두 코드는 결과가 같을까요? 전혀 다른 결과를 출력합니다.
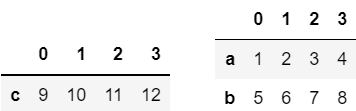
왼쪽이 df[-1:] , 오른쪽이 df[:-1] 입니다.
시작에 -1을 주게된다면 0~1까지를 제외시킨 결과를 의미하고,
끝에 -1을 주게된다면 맨 뒤에서부터 1개를 제외한 결과를 의미합니다.
loc
loc는 아까 말했던 대로 명칭으로 슬라이싱을 하는 경우인데 DataFrame의 인덱스와 컬럼을 ,를 기준으로 표현할 수 있습니다.
df.loc["a",3]
아까 ["a","b","c"]를 인덱스로 만들어둔 df에 위 코드를 실행해보면 "a"인덱스의 데이터의 3 컬럼의 값이 나옵니다. 현재는 컬럼명이 3이지만 예를들어 "weight" 같은 명칭에 각 사람의 이름이 인덱스인 데이터일 경우
df.loc["james","weight"]
이런 코드로 사용이 가능합니다.
자연스럽게 iloc를 생각해보면 이러한 조회 방식을 숫자를 써서 사용하는 방식으로, 몇번째 인덱스인지, 몇번째 컬럼인지를 생각해서 사용하면 쉽습니다.
순서로 생각해보면 "a"는 첫번째 인덱스이기 때문에
df.iloc[0,3]
위 코드는 같은 결과가 나옵니다. 그리고 loc와 iloc모두 offset index처럼 : 을 사용하여 연속된 여러 데이터를 출력할 수 있습니다.
