
데이터 전처리에는 두가지 단계가 있다.
- 데이터 구조 만들기
- 모델링을 위한 전처리
이를 수행하기 위해서는 데이터 구조를 이해가 필요하고 생성할 수 있어야한다.
또, 데이터 분석 절차를 이해하고 분석 도구를 사용할 수 있어야 한다.
1. 데이터프레임 변경
(1) 열 이름 변경
- 열 이름 복잡하게 되어있을 경우 식별이 좋게 변경하는 경우가 있다.
1) 모든 열 이름 변경
data.columns = ['새로운 열1', '새로운 열2',
'새로운 열3', '새로운 열4', '새로운 열5'] - 변경할 열 이름을 나열하면 변경이 된다.
2) rename(columns={},inplace= )
data.rename(columns = {'기존 열1' : '새로운 열1',
'기존 열2' : '새로운 열2',
'기존 열3' : '새로운 열3',
'기존 열4' : '새로운 열4'}, inplace = True)- inplace=True는 데이터 프레임에 변경을 적용할 때 사용한다.
- 반대로 False는 변경에 적용하지 않고 보여주기(조회)만 한다.
(2) 열 추가
1) 없는 열 추가
data['새로운 열 이름'] = data['기존 열1'] + data['기존 열2']- 이런식으로 새로운 열이 추가되면 연산도 수행 가능하다.
- 여기서 같은 데이터프레임 끼리 연산이 가능하다는 걸 기억하자
- 다른 데이터프레임끼리 연산하려면 merge함수를 통해 합치고 연산 수행.
- merge함수는 뒤에서 배운다.
2) 지정한 위치에 열 추가 insert()
data.insert(자리(인덱스 입력), '새로운 열 이름', 수행할 계산 식)- 원하는 위치의 인덱스를 입력하면 연산되어 새로운 이름으로 생성된다.
(3) 열 삭제 drop()
- drop() 사용
- axis = 0은 행 삭제(default 값)
- axis = 1은 열 삭제
- inplace = True 옵션을 지정해야 반영 (rename과 유사)
- False: 삭제한 것 처럼 보여주기(조회)
1) 열 하나 삭제
data.drop('삭제할 열이름', axis=1, inplace=True)- 입력한 열이름의 열이(axis=1) 삭제된다.
2) 여러 열 삭제
data.drop(['삭제 열1', '삭제 열2], axis=1, inplace=True)- 삭제할 열을 리스트[] 형태로 입력하여 제거
(4) 값 변경 (map, cut)
- 먼저 값을 변경하기 전에 되돌리기 위해 data.copy()하여 잘못되었을 때, 되돌리기 위한 준비가 꼭 있어야 한다. 실수하면 큰일...
1) 열 전체 값 변경
data['열1'] = 0- 열1의 모든 값을 0으로 변경한다.
2) 조건 추가 loc
data.loc[ data['열1'] < 10, '열1'] = 0- 열1의 값이 10보다 작으면 값 들을 0으로 바꿔라.
- 다른 열 끼리도 사용 가능하다.
3) 조건 추가 np.where
data['열1'] = np.where(data['열1'] < 10, 0, 1)- 열1의 값이 10보다 작으면 0, 크면 1
4) .map()
data['열1'] = data['열1'].map({'값1': 10, '값2' : 20})- 열1에 있는 값을 값1은 10으로 값2는 20으로 변경 한다.
5) pd.cut()
- 숫자형에서 범주형 변수로 변환할 수 있다.
- ex) 나이 - 나이대, 고객 구매액 - 고객 등급
- pd.cut(대상, bins=[], labels=[]) 만 기억하자..!
data['열2'] = pd.cut(data['열1'], bins = [], labels=[] )- 열1에서 bins에 범위를 설정하고, labels에 그 범주의 값 이름 설정하여 열2로 새로 생성.
age_group = pd.cut(data2['Age'],
bins =[0, 40, 50, 100] ,
labels = ['young','junior','senior'])- Age열에서 0~40까지, 40~50까지, 50~100까지로 범위를 나눈다.
- 범위 별로 young, junior, senior로 설정하여 새로운 열 age_group을 생성
2. 데이터프레임 결합
(1) concat
- 매핑 기준: 인덱스(행), 컬럼이름(열)
1) axis = 0, 세로로 합치기
- 열 방향(위, 아래로 붙여라)
- 컬럼 이름 기준
- join
- inner: 같은 행만 합침
- outer: 모든 행과 열 합치기
아래와 같은 데이터 프레임을 갖는다
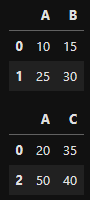
df1
df2
pd.concat([df1, df2], axis = 0, join = 'inner')-
df1과 df2를 세로로 행이 같은 것(A)를 기준으로 위, 아래로 합침

pd.concat([df1, df2], axis = 0, join = 'outer') -
df1과 df2를 세로로 모두 합침
-
빈자리는 NAN으로 채움
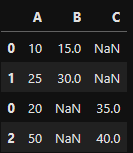
2) axis = 1, 가로로 합치기
- 행 방향(옆으로 붙여라)
- 행 인덱스 기준
- join
- inner: 같은 행과 열만 합친다.
- outer: 모든 행과 열을 합친다.
pd.concat([df1, df2], axis = 1, join = 'inner')- 행 0만 같아서 0을 기준으로 옆으로 합침

pd.concat([df1, df2], axis = 1, join = 'outer')- 행을 기준으로 옆으로 합침 (빈 값은 NAN)
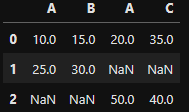
(2) merge
- 매핑 기준: 특정 컬럼(key)의 값 기준으로 결합
- 옆으로만 병합
- 어떤 컬럼을 기준으로 할지
- concat과 다르게 두 개 씩만 가능
- how와 on을 생략할 수 있음
- how는 inner 조인, on은 자동으로 함
- pd.merge(df1, df2, how = '', on = '')
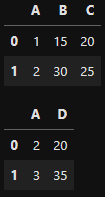
df1
df2
pd.merge(df1, df2, how = 'inner', on = 'A')- df1과 df2를 병합하고 inner방식으로 A 컬럼을 기준
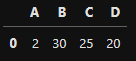
pd.merge(df1, df2, how = 'left') # df1을 기준으로 병합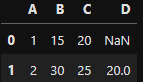
pd.merge(df1, df2, how = 'right') # df2를 기준으로 병합한다.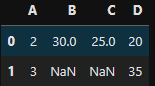
(3) pivot
- 집계(groupby)된 데이터를 재구성함
- df.pivot(index='', columns='', values='')
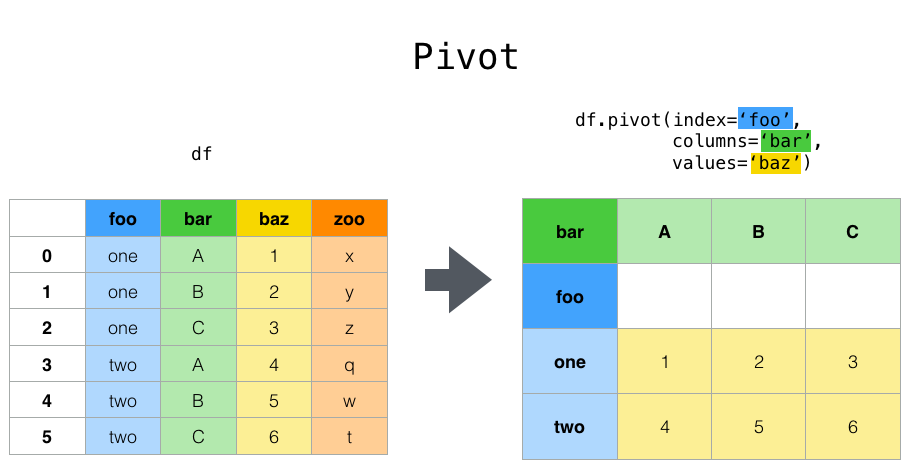
이 그림 처럼 df(데이터프레임)을 재구성할 수 있음
3. 시계열 데이터 처리
- 시계열 데이터는 행과 행에 시간의 순서가 있다.
- 행과 행의 시간 간격이 동일한 데이터(등간격)이다.
(1) 날짜 데이터 요소
- .df.날짜요소
- 각 날짜 별 원하는대로 뽑고싶을 때 사용하는 함수
- 옛날 데이터라 내일 자료 다시 받고 업로드함!!!!!!!
(2) shift
- 시계열 데이터에서 시간의 흐름 전후로 정보를 이동시킬 때 사용함.
# 전날 매출액 열을 추가 temp['Amt_lag'] = temp['Amt'].shift() #default = 1 # 전전날 매출액 열을 추가 temp['Amt_lag2'] = temp['Amt'].shift(2) # 2행 shift
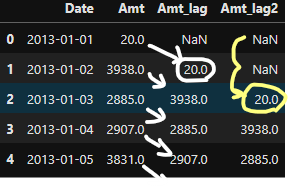
- Amt_lag는 한 칸씩 밀었음. shift안에 빈칸일때, 1칸으로 함
- Amt_lag2는 두 칸씩 밀었음.
(3) rolling + 집계함수(mean, max, min 등)
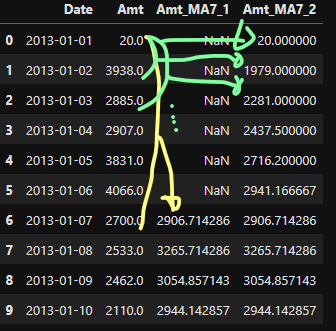
temp['Amt_MA7_1'] = temp['Amt'].rolling(7).mean()- 총 7(0번 인덱스~6번 인덱스)칸의 평균 값을 작성함
- 평균을 하는 동안 앞의 6개의 값은 평균 값을 나타내지 못함.(NaN)
temp['Amt_MA7_2'] = temp['Amt'].rolling(7, min_periods = 1).mean()- min_periods = 1으로 한 개 단위로 끊어줌
- 첫번째 값에는 1개의 평균
- 두번째는 2개의 평균
- 세번째는 3개의 평균 ... 이렇게 7번째(6번 인덱스)으로 가면 같아짐
(4) .diff 차분
- 보통 차분은 과거 데이터로 차분을 진행함
- 미래 데이터는 없는 경우가 있고, 과거 데이터를 현재 인덱스의 데이터와 관계를 파악하여 사용하는 경우가 많음
temp['Amt_D1'] = temp['Amt'].diff() # 바로 앞칸과의 차
temp['Amt_D2'] = temp['Amt'].diff(2) # 두칸 앞과의 차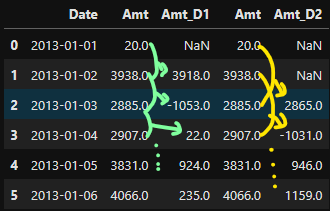
4. 데이터 분석 방법론
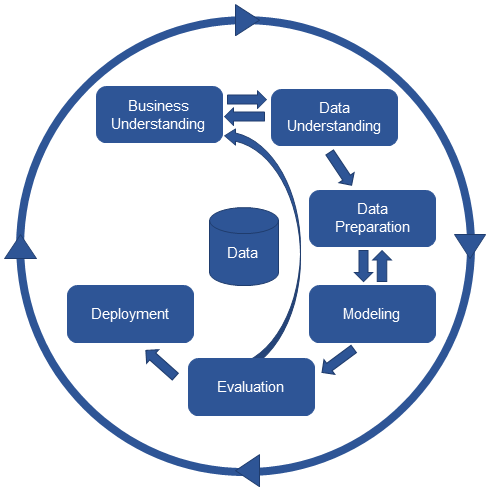
(1) Business Uderstanding - 가설수립 단계
- 무엇이 문제인가? (문제를 정의)
- 데이터 분석 방향, 목표 결정
- 요인을 파악하기 위해서 가설을 수립
- 기존의 연구 결과인 귀무가설
- 새로운 연구 가설인 대립가설
- 가설 수립 절차
- 해결할 문제 정의 (목표, 관심사, Y)
- 설명하기 위한 요인 추측 (X)
- 가설의 구조를 정의 (x->y인 이유)
(2) Data Understanding
-
데이터 취득 후
- 내부 데이터
- 가공이 필요 없는 데이터 (가용 가능)
- 가공이 필요한 데이터 (가용 가능)
- 외부 데이터
- 취득 가능 (가용 가능)
- 취득 불가능 (가용불가)
- 내부 데이터
-
데이터 탐색 방법
- 통계량
- 시각화
위 탐색방법을 통해 EDA, CDA분석을 진행
-
EDA(Exploratroy Data Analysis): 탐색적 데이터 분석
(그래프, 통계량) -
CDA(Confirmatory Data Analysis): 확증적 데이터 분석
(가설검정, 실험)
이를 통해
- 단변량 분석, 이변량 분석을 실시해야 한다.
(3) Data Preperation
- 모든 셀에 값이 있어야 한다. (N/A값 불가능)
- 모든 값이 숫자이어야 한다.
- 값의 범위를 일치하여야 한다.
이를 하기 위해
- 결측치 조치, 가변수화, 스케일링, 데이터 분할 실시
(4) Modeling
- 데이터로부터 패턴을 찾는 과정
- 오차를 최소화 하는 패턴
- 결과물인 모델은 수학식으로 표현 된다.
(5) Evaluation
- 문제가 해결되었는가?
- 기술적 관점 평가
- 비즈니스 관점 평가
(6) Deployment
- 문제가 해결되었으면
- 모델 관리
- AI 서비스 구축 및 배포
[참고] 한기영 강사님 강의 자료

뒤늦게 프로그래밍을 시작한 응애