
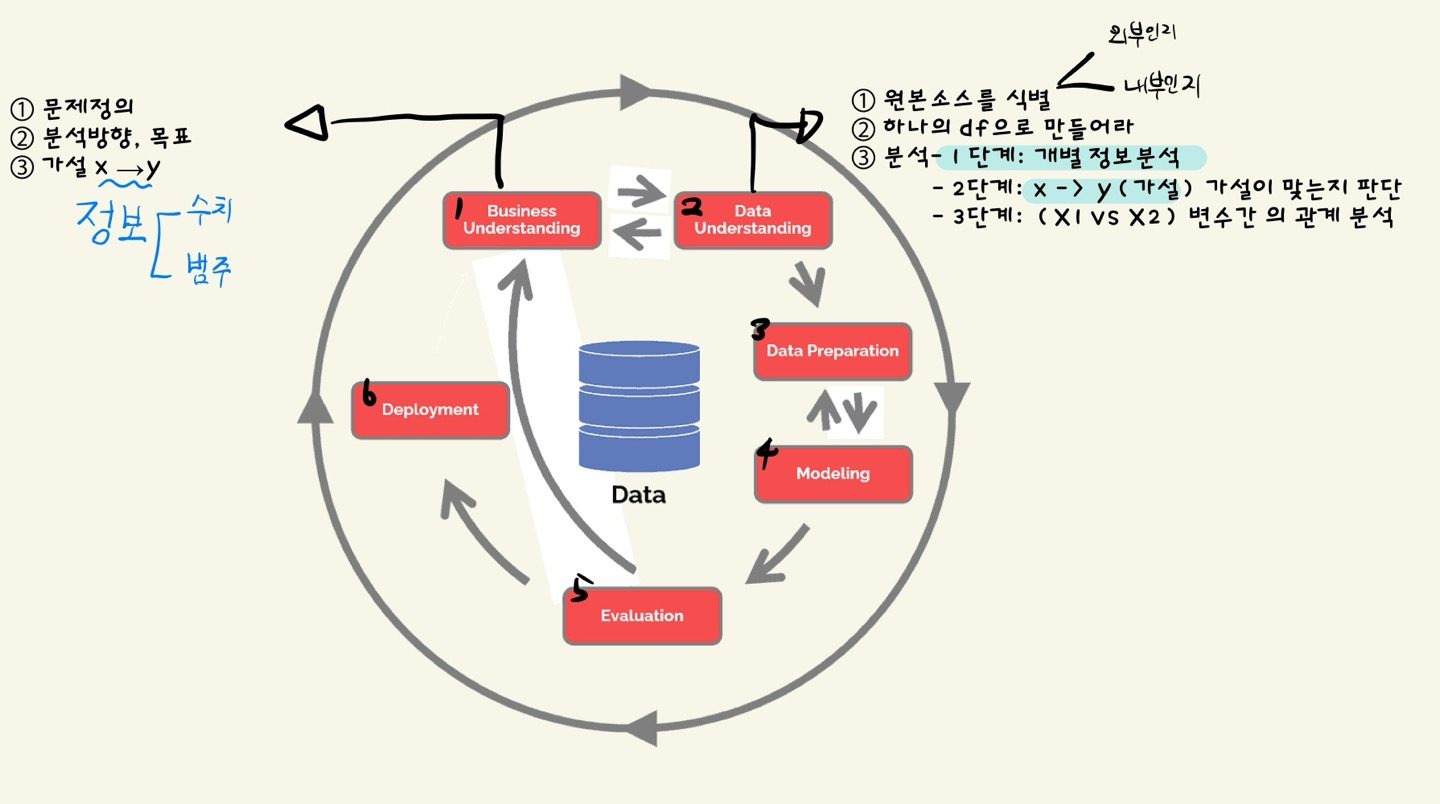
강사님께서 오늘도 어김 없이 CRISP-DM에 대해서 설명하며 강의를 시작하였다.
- CRISP-DM
- 저번 시간엔 하나의 데이터프레임(df)로 만드는 merge, concat 등의 함수를 배웠다.
- 오늘은 Data Understading에서 ③ 1단계: 개별정보 분석 단계, ② 2단계 x -> y 를 진행하였다.
- 개별 정보를 시각화 및 통계화 하여 시각화 한 정보를 가지고 어떤 생각(분석) 을 할 수 있는지 생각해 볼 수 있는 시간을 가졌다.
- 다양한 사람들의 의견을 들으며 각자의 생각이 달라 팀 프로젝트를 진행할때 가장 많이 대화를 해야하는 부분이 아닌가 생각이 든다.
- 그리고 그 분야에 대한 도메인지식이 많이 필요하다.
갑자기 생각 난 강사님 말씀
CRISP-DM 단계를 빠르게 두 번은 과정대로 돌면, 볼 수 없던 부분도 보이고 완성도가 높은 프로젝트가 될 수 있다.
(나중에 프로젝트때 기억하자)
4. 시각화라이브러리
-
데이터를 한 눈에 파악하는 방법
- 그래프(시각화)
- 통계량(수치화)
-
데이터 시각화의 한계점
- 요약된 정보가 표현된다.
- 요약하는 관점에 따라 해석의 결과가 달라진다.
- 요약은 정보의 손실(원본데이터 손실)과 같다.
(1) 기본차트 그리기
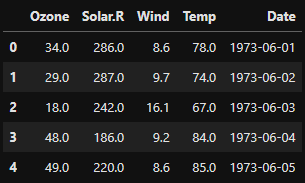
데이터를 불러왔다.
이제 이 데이터프레임을 통해 차트를 그려 보겠다.
plt.plot(data['Date'], data['Temp'])
plt.plot('Date', Temp', data = data) # 위와 같은 표현임
plt.show()
차트를 가지고 왔다.
아마 이 차트를 가지고 현업 상사님께 제출한다면 ㅋㅋㅋㅋ 상상도 하기 싫다.
- 여기서 뭘 나타내는지
- 각 축은 뭐를 다타내는지
- x축은 왜 저렇게 표현되지?
이런걸 해결하고 가독성을 높여 줄 방법을 보자
(2) 차트꾸미기
plt.plot(data['Date'], data['Ozone'])
plt.xticks(rotation = 30) # x축 값 꾸미기 : 방향을 30도 틀어서
plt.xlabel('Date') # x축 이름 지정
plt.ylabel('Ozone') # y축 이름 지정
plt.title('Daily Airquality') # 타이틀
plt.show()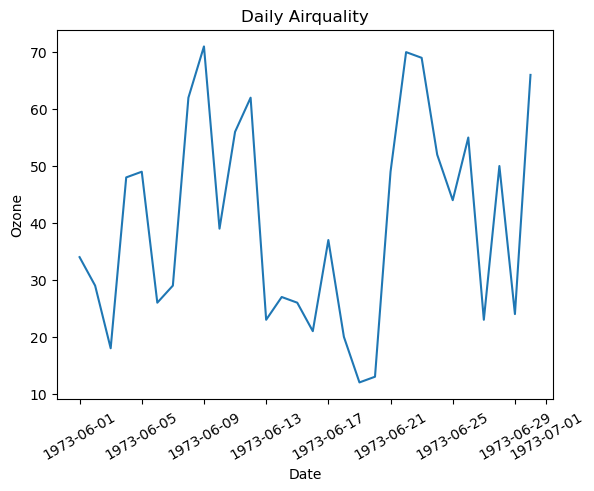
위와같은 방법으로 가독성이 좋은 차트를 보일 수 있다.
이 외에도
- color = 'red', 'green' 등
- linestyle = '-', '--', '-.' '.' 이 있다.
- marker
| marker | description |
|---|---|
| "." | point |
| "," | pixel |
| "o" | circle |
| "v" | triangle_down |
| "^" | triangle_up |
| "<" | triangle_left |
| ">" | triangle_right |
여러 그래프를 겹쳐서 그리기
여러 그래프를 겹치고 꾸며서 그려보자
plt.plot(data['Date'], data['Ozone'],
color='green',
linestyle='dotted',
marker='o')
plt.plot(data['Date'], data['Temp'],
color='r',
linestyle='-',
marker='s')
plt.xlabel('Date')
plt.ylabel('Ozone')
plt.title('Daily Airquality')
plt.xticks(rotation=45)
plt.show()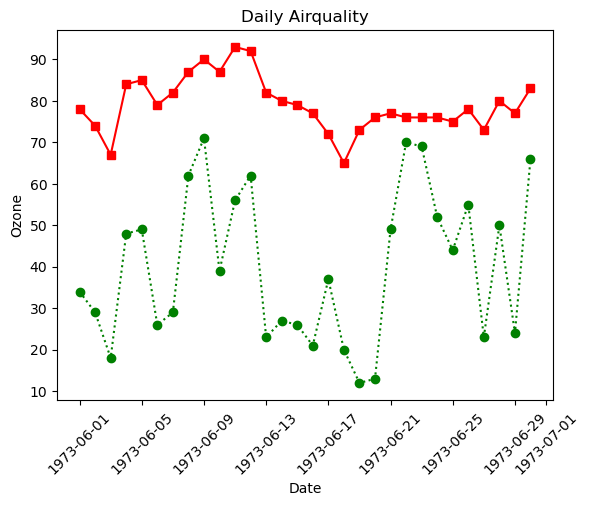
그 외 함수
- plt.legend(loc = '위치') # 범례
- plt.grid() # 그리드
- plt.xlim(시작,끝) # x 범위
- plt.ylim(시작,끝) # y 범위
- plt.axhline(위치, color = 'grey', linestyle = '--') # 수평선 (가로)
- plt.axvline(위치, color = 'red', linestyle = '--') # 수직선 (세로)
- plt.text(5, 10, '40') # (5, 10) 지점에 40 텍스트 작성
subplot(행, 열, 위치)
plt.figure(figsize = (8,4))
plt.subplot(3,1,1)
plt.plot('Date', 'Temp', data = data, marker = 'o', color ='r')
plt.grid()
plt.subplot(3,1,2)
plt.plot('Date', 'Wind', data = data, color = 'b')
plt.subplot(3,1,3)
plt.plot('Date', 'Ozone', data = data)
plt.grid()
plt.ylabel('Ozone')
plt.tight_layout() # 그래프간 간격을 적절히 맞추기
plt.show()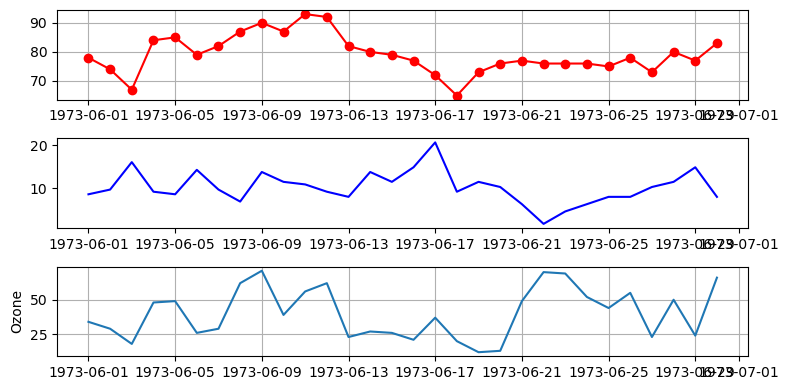
5. 단변량 분석_숫자형 변수
(1) 숫자형 시각화
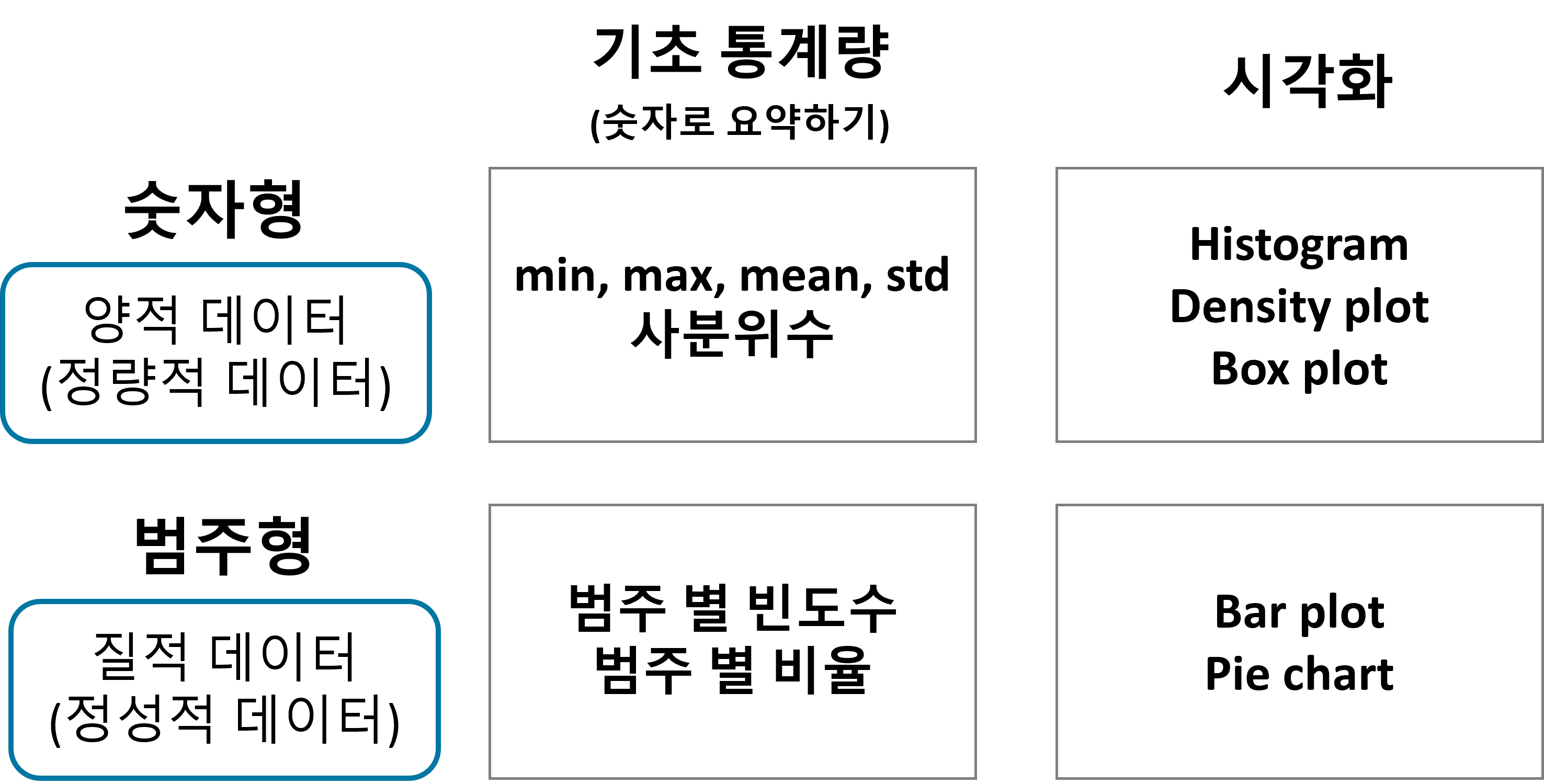
이 그림은 각 데이터 마다(수치형, 범주형마다) 데이터를 분석하는 방법과 시각화 하는 방법이다.
숫자로 요약
- 수치형 변수로 정리하는 방법
- 숫자로 요약하기 (평균, 중앙값, 최빈값, 사분위수) -> 기초 통계량
- 사분위수는 데이터를 오름차순으로 정렬한 후 전체를 4등분 하고 25%, 50% 75%를 의미함
- 구간을 나누고 빈도수 계산 (도수 분포표)
#평균
np.mean(titanic['Fare'])
titanic['Fare'].mean()
#중앙값
np.median(titanic['Fare'])
titanic['Fare'].median()
#최빈값
titanic['Pclass'].mode()
#시각화
df.describe()| Fare | |
|---|---|
| count | 891.000000 |
| mean | 32.204208 |
| std | 49.693429 |
| min | 0.000000 |
| 25% | 7.910400 |
| 50% | 14.454200 |
| 75% | 31.000000 |
| max | 512.329200 |
- describe() 로 시각화를 하면 이런 식으로 기초통계량이 모두 나온다.
강의 중 사분위수를 통해서 그래프를 예측하며 손으로 그리는 연습을 했다.
이런식으로 연습하면서 더 잘 이해할 수 있을 것이다.
(2) 차트형 시각화
1) 히스토그램 histplot
plt.hist(titanic['Fare'], bins = 5, edgecolor = 'gray')
plt.xlabel('Fare')
plt.ylabel('Frequency')
plt.show()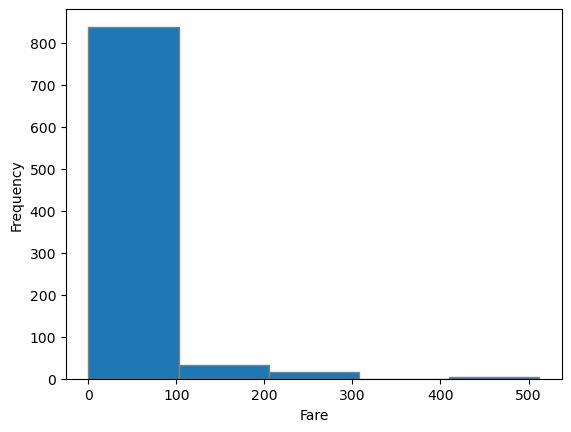
- 'Fare'를 활용하여 5개 구간으로 나누고 윤곽선을 회색으로 했음
- x좌표는 Fare
- y좌표는 Frequency
이건 Seaborn 패키지로 한거다.
sns.histplot(x= 'Fare', data = titanic, bins = 20)
plt.title('plt can use sns')
plt.grid()
plt.show()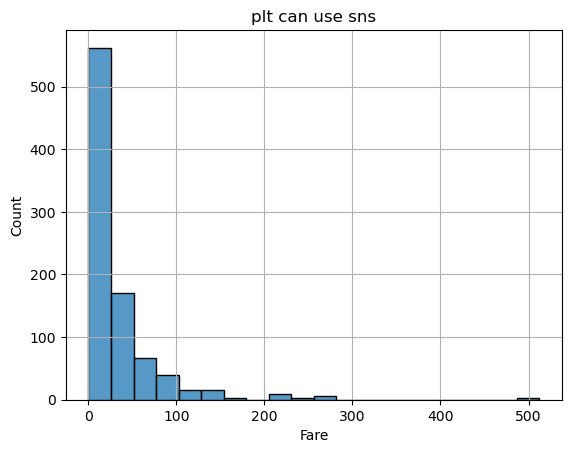
- edgecolor도 자동으로 해주고, x 축 y축 설정을 안해도 자동으로 설정해준다.
- 그래서 강의하는 동안 sns를 많이 쓸거다.
2) 밀도함수 그래프 kdeplot
- 히스토그램의 단점
- 구간(bin)의 너비를 어떻게 잡는지에 따라 전혀 다른 모양이 될 수 있음
- 밀도함수 그래프
- 막대의 너비를 가정하지 않고 모든 점에서 데이터의 밀도를 추정하는 커널 밀도 추정(Kernel Density Estimation)방식을 사용하여 이러한 단점을 해결.
- 밀도함수 그래프 아래 면적은 1
sns.kdeplot(titanic['Fare'])
plt.show()sns.kdeplot(x='Fare', data = titanic)
plt.show()- 같은 결과 값 나옴
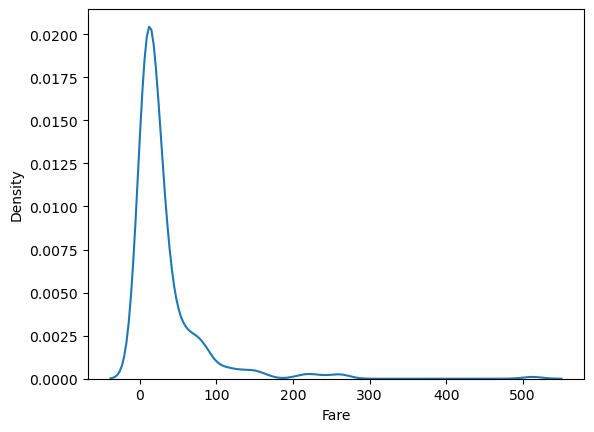
#이런식으로도 사용할 수 있음!!!
sns.histplot(x = 'Age', data = titanic, bins = 16, kde = True)3) boxplot
- matplotlib은 NaN(결측값)을 제거하고 그려야 한다.
- .notnull()을 사용하여 제거한다.
temp = titanic.loc[titanic['Age'].notnull()] - NaN가 아닌 값을 조회(loc)하여 temp에 저장해라
#plt
plt.boxplot(temp['Age'], vert = False)
plt.grid()
plt.show()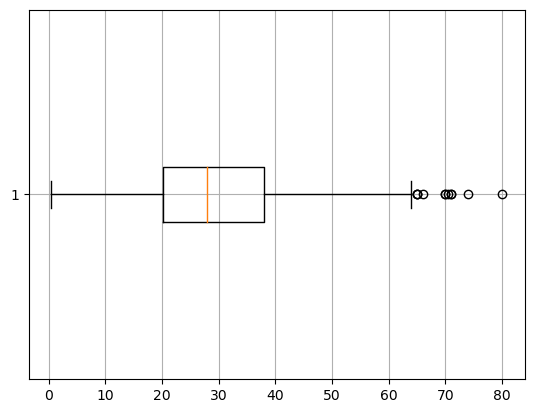
- vert = False 를 사용하여 누운 모양이 출력 되었음(안써도 된다.)
# sns
sns.boxplot(x = titanic['Age'])
plt.grid()
plt.show()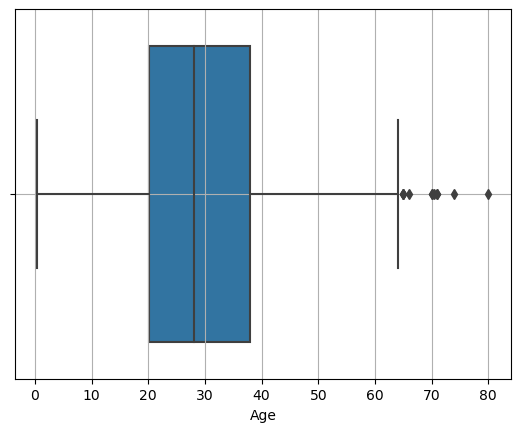
6. 단변량분석_범주형변수
범주별 숫자형 표현 value_counts()
범주별 빈도수 표현 value_counts()
titanic['Embarked'].value_counts()결과값: Embarked 변수에 있는 값들의 개수를 시리즈로 출력
Embarked(변수 명)
Southampton 644
Cherbourg 168
Queenstown 77
Name: count, dtype: int64
범주별 비율 표현 value_counts(normalize=True)
titanic['Embarked'].value_counts(normalize = True)결과값: Embarked 변수에 있는 값들의 비율을 시리즈로 출력 (빈도를 전체 데이터로 나눈 값)
Embarked
Southampton 0.724409
Cherbourg 0.188976
Queenstown 0.086614
Name: proportion, dtype: float64
범주별 시각화 표현 bar chart
sns.countplot(x = 'Pclass', data = titanic)
plt.grid()
plt.show()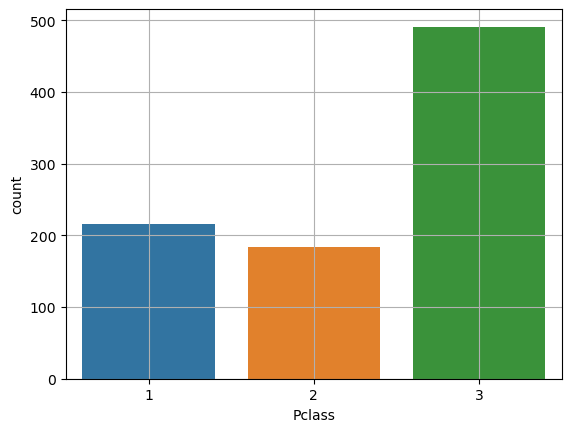
- sns.countplot는 알아서 빈도 수 계산 bar 그림
- plt.bar는 직접 범주별 빈도수를 계산하고 그 결과를 입력해야 bar가 그려짐
그 외
공통점: Y축이 같다(count), x축이 다르다.
-
히스토그램(hist): x축 순서를 바꿀 수 없다.
-
막대그래프(bar): x축 순서를 바꿀 수 있다.
데이터 분석의 시간
- 이 후 타겟변수를 지정하고, 피쳐를 설정한 데이터가 주어졌다.
- 주어진 데이터를 시각화하여 x->y 가설을 세우고 추가 분석해야하는 것을 알아 보았다.
- 단변량 분석으로 모든 걸 판단할 수 없다.
- 데이터 분석을 하는 건 신기하고 재밌는 수업이었다.
- 또 같이 수업듣는 에이블러들이랑 의견을 공유하면서 서로 다른 생각을 한다는게 신기했다.
- 빨리 내일 수업인 다변량시각화를 하여 분석을 하고 싶다.
- 이 말을 한거 내일 후회할 듯 싶다ㅋㅋㅋ
