
딥러닝
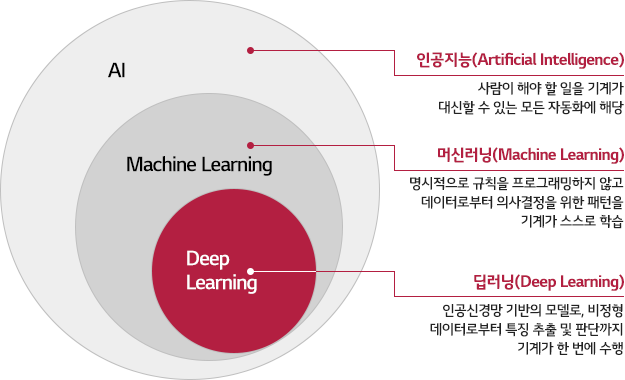
딥러닝은 머신러닝의 한 분야로, 인공신경망을 기반으로 하는 알고리즘들을 다룬다. 딥러닝은 특히 대량의 데이터를 기반으로 패턴을 학습하고 복잡한 특징을 추출하는데 효과적이다.
인공신경망: 인간의 뇌가 작동하는 방식에서 영감을 받아 만들어진 인공신경망을 사용합니다. 이는 입력층, 은닉층, 출력층으로 구성되며, 각 층은 뉴런이라는 단위로 연결되어 있습니다.
다층 구조: 다층 신경망은 많은 수의 은닉층을 포함하고 있습니다. 이를 통해 데이터의 추상화를 통해 복잡한 특징을 학습할 수 있게 됩니다.
자동 특징 추출: 딥러닝은 데이터로부터 특징을 자동으로 추출하여 학습합니다. 이는 전통적인 머신러닝 방법과 달리, 사람이 직접 특징을 정의하거나 추출할 필요가 없다는 장점을 가집니다.
대규모 데이터 사용: 딥러닝은 수백만 개에서 수십억 개의 데이터를 기반으로 학습할 수 있습니다. 대량의 데이터를 사용하면 더 정확한 모델을 학습할 수 있습니다.
역전파 알고리즘: 역전파(backpropagation) 알고리즘을 사용하여 오차를 최소화하도록 가중치를 조정합니다. 이는 신경망이 학습 데이터에 맞게 적응하도록 도와줍니다.
이러한 특징들은 딥러닝을 이미지 인식, 음성 인식, 자연어 처리 등 다양한 분야에서 효과적으로 사용할 수 있다.
딥러닝은 데이터 전처리 과정에서 NaN조치, 가변수화, 스케일링(필수임)을 해야한다.
머신러닝의 경우 스케일링이 필요할때만 진행했음
모델링 단계에선 모델구조, 컴파일, 학습, 학습곡선, 예측 및 검증을 진행한다.
딥러닝 코드
전처리과정 및 ML과정
# x, y 변수 생성
target = 'Sales'
x = data.drop(target, axis=1)
y = data.loc[:, target]
# 가변수화
dum = ['A', 'B', 'C', 'D', 'E']
x = pd.get_dummies(x, columns=dum, drop_first=True, dtype=int)
# 스케일링
scaler = MinMaxScaler()
x_train = scaler.fit_transform(x_train)
x_val = scaler.transform(x_val)
# 데이터 분할
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=.2,
random_state = 20)
# 모델선언
model = LinearRegression()
# 학습
model.fit(x_train, y_train)
# 예측
y_pred = model.predict(x_val)
# RMSE 함수가 없음, 그래서 직접 루트를 씌우지 않고 squared=False를 함
print(f'RMSE :{mean_squared_error(y_val, y_pred, squared=False)}')
print(f'MAE : {mean_absolute_error(y_val, y_pred)}')
print(f'MAPE : {mean_absolute_percentage_error(y_val, y_pred)}')DL과정
스케일링
- 딥러닝은 스케일링을 필요로함
- Normalization(정규화): 범위를 0~1로 변환
- Standardization(표준화): 평균=0, 표준편차=1로 변환
라이브러리 선언
# 라이브러리 선언
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.metrics import *
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense
from keras.backend import clear_session
from keras.optimizers import Adam모델선언
# 컬럼개수
nfeatures = x_train.shape[1]
nfeatures
# 메모리 정리
clear_session()
# Sequential 타입 모델 선언
model = Sequential( Dense(1, input_shape = (nfeatures, )) )
# 모델요약
model.summary()
- input_shape = ( , )
- feature의 1차원이냐 2차원이냐에 따라 다르게 들어감
히든 레이어를 사용한 모델선언
model = Sequential([Dense(num1, input_shape = (nfeatures, ), activation= 'relu'),
Dense(num2, activation= 'relu'),
Dense(num3, activation= 'relu'),
Dense(num4, activation= 'relu'),
Dense(1)])activation: 히든레이어 사용을 위한 활성함수 (보통'relu'사용)- 추가로
'sigmoid','tanh'가 있음
- 추가로
# 컴파일
model.compile(optimizer = Adam(learning_rate = 0.001), loss='mse')- 선언된 모델을 컴퓨터가 이해할 수 있는 형태로 변환
loss: 오차계산을 무엇으로 할지 결정 (회귀모델의 경우 보통 mse로 계산)optimizer: 오차를 최소화 하도록 가중치 조절 (0.001 디폴트)- learning_rate 가중치를 너무 크게, 너무 작게하면 최소값에 도달하지 못함
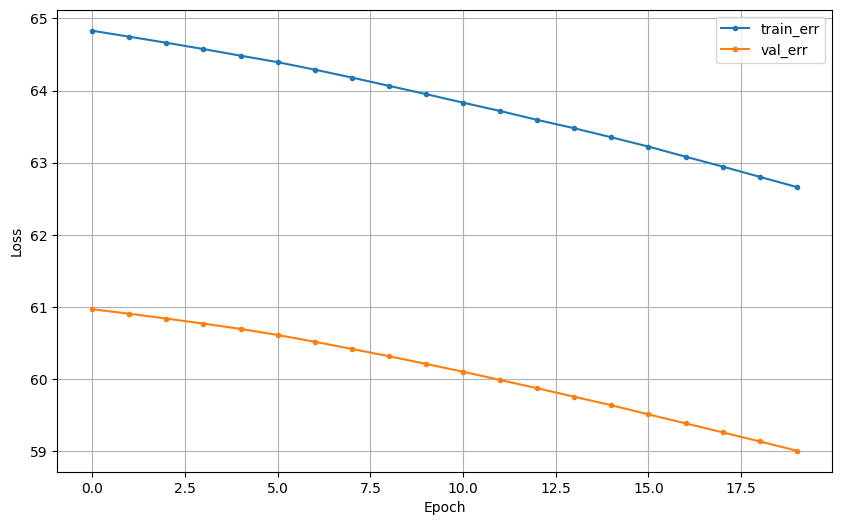
잘못 나온 것
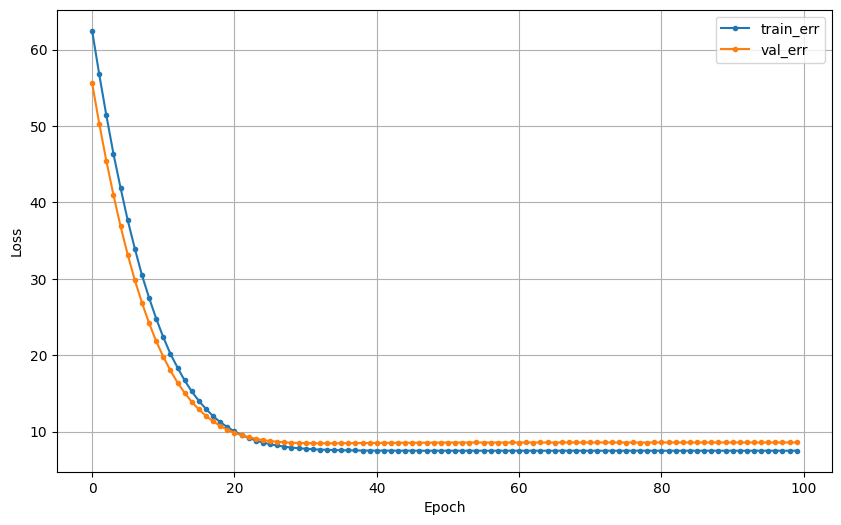
잘 나온 것
# 학습
hist = model.fit(x_train, y_train, epochs = 20, validation_split=.2, verbose=0).historyepochs: 가중치 조정 반복 횟수validation_split0.2이면 20%를 검증셋으로 분리
# 예측
pred = model.predict(x_val)
# 검증
print(f'RMSE : {mean_squared_error(y_val, pred, squared=False)}')
print(f'MAE : {mean_absolute_error(y_val, pred)}')
print(f'MAPE : {mean_absolute_percentage_error(y_val, pred)}')학습곡선 그래프 함수 만들기
def dl_history_plot(history):
plt.figure(figsize=(10,6))
plt.plot(history['loss'], label='train_err', marker = '.')
plt.plot(history['val_loss'], label='val_err', marker = '.')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend()
plt.grid()
plt.show()