
미니프로젝트
- 미세먼지 데이터를 활용하여 데이터를 전처리하고 미세먼지 농도를 예측하는 머신러닝 모델을 구현하는 프로젝트를 하였습니다.
데이터 기본 탐색 및 분석
- 주어진 데이터는 날씨데이터, 미세먼지데이터
- 각 변수 중 '측정일시', 'PM10', 'PM25', '일시' 데이터를 변수의 의미와 결측치, 수치범주, 기초통계량을 확인하고 시각화를 진행했습니다.
plt.plot,info(),isnull(),corr()메서드를 활용하여 변수 분석을 진행했음
- 측정일시
- PM10
- PM25
데이터 전처리
- 수치형데이터를 새로운 변수에
pd.to_datatime(df, format = '%Y%m%d%H')사용하여 시계열 데이터로 변환함 set_index('변수', inplace=True),sort_index(inplace=True)으로 변수를 인덱스로 사용하고 오름차순으로 정렬함

-
위 변수들 중 미세먼지(PM10)에 영향을 끼칠 변수만 골라 결측치제거 및 머신러닝을 위해 데이터 분할을 진행함
-
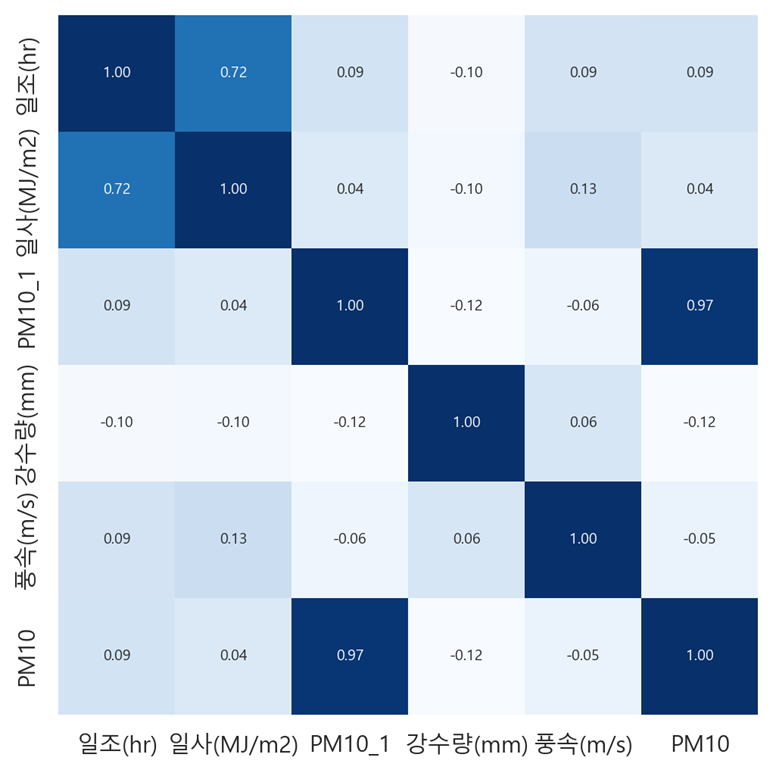
우리조 가설
- 일조량과일사량이 미세먼지 농도에 관련이 있을 것이다.
- 강수량과 풍속이 미세먼지 농도에 관련이 있을 것이다.
-
'일조(hr)', '일사(MJ/m2)', 'PM10_1', '강수량(mm)', '풍속(m/s)', 'PM10' 위 가설을 증명하기 위해 데이터를 뽑아서 진행했음
-
일조량, 일사량, 강수량은 결측치가 존재
- 강수량은 0으로 결측치를 채움
- 일조량 일사량은 평균으로 결측치를 채움
-
이를 히트맵을 통해 시각화 진행
-
모두 관련이 적어서 관련이 적다고 판단했음
머신러닝 모델링
model_name = ['KNeighborsRegressor', 'LinearRegression', 'Lasso', 'Ridge',
'DecisionTreeRegressor', 'RandomForestRegressor',
'GradientBoostingRegressor']
models = [KNeighborsRegressor(n_neighbors=5), LinearRegression(), Lasso(),
Ridge(), DTR(max_depth=5), RFR(), GBR()]
def create_model(models, model_name, x_train, x_test, y_train, y_test):
for model, model_name in zip(models, model_name):
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
print('=' * 10, model_name, '=' * 30)
print('MSE : ', mse(y_test, y_pred).round(5))
print('MAE : ', mean_absolute_error(y_test, y_pred).round(5))
print('R2 : ', r2_score(y_test, y_pred).round(5))
joblib.dump(model, model_name + '.pkl')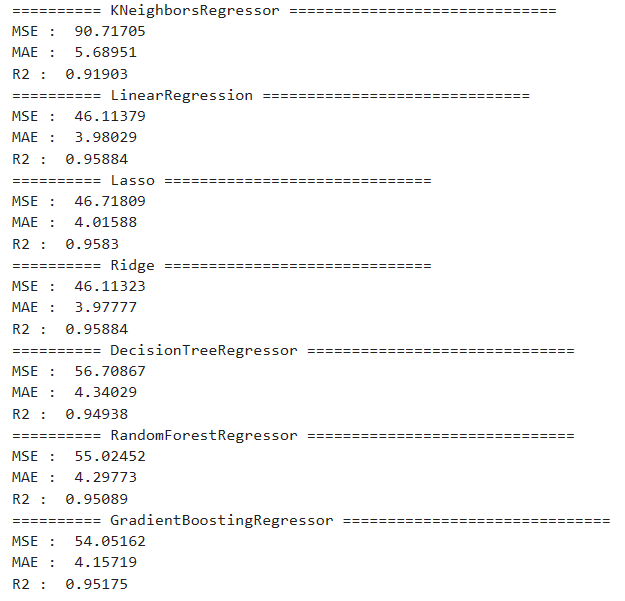
LinearRegression의 성능이 가장 좋게 나옴- 시각화를 위해
RandomForestRegressor,GradientBoostingRegressor사용함
GradientBoostingRegressor

RandomForestRegressor
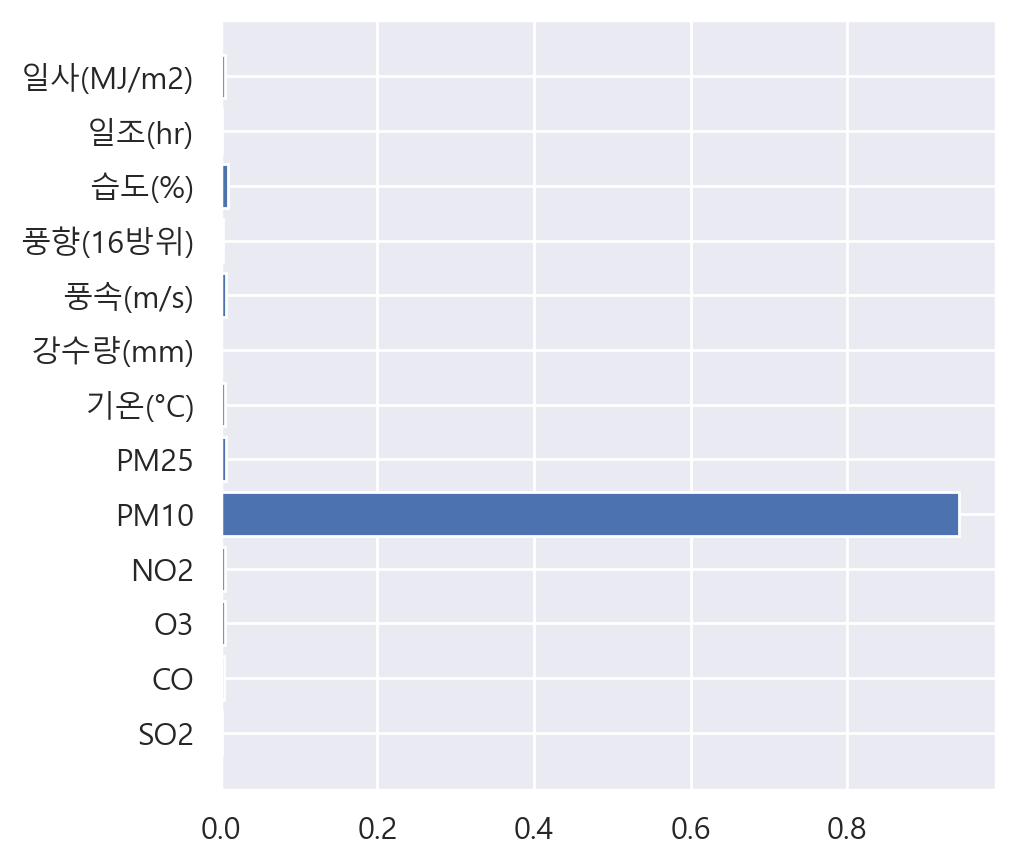
- PM10이 너무 크게 나와 다른 변수들을 보기 어려움 => PM10을 제외함
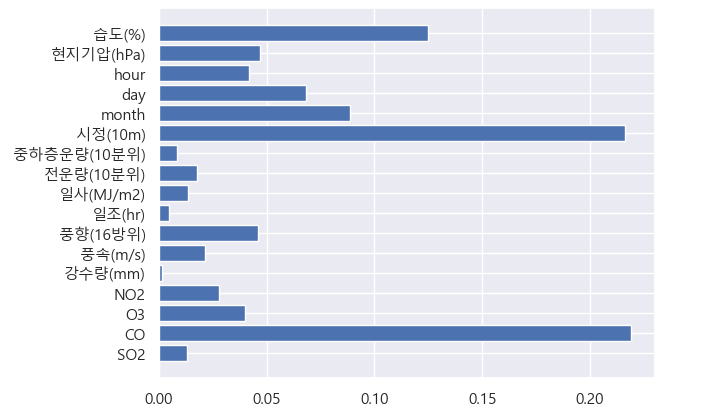
- PM10을 제외한 것
결론
- 일조량, 일사량, 강수량, 풍속보다는 오히려 CO, 시정, 습도 같은변수들이 PM10예측에 있어서 중요도가 더 높았다.

뒤늦게 프로그래밍을 시작한 응애