
IOU
- Intersection over Union(IOU) 은 물제 검출 및 분할에서 사용되는 성능 측정 지표 중 하나이다.
- 예측된 바운딩 박스(predicted bounding box)와 실제 바운딩박스(bounding box) 사이의 겹치는 영역을 찾는다.
- 겹치는 영역의 면적을 예측된 바운딩 박스 영역과 실제 바운딩 박스의 영역의 합집합으로 나눈다.
- 0 ~ 1 사이의 값으로 표현된다.
- Confidence Score(신뢰점수)
- 물체 검출 모델이 예측한 각 Bounding Box에 부여되는 확률 이나 점수
- 신뢰 점수가 높으면 해당 Bounding Box가 물체를 잘 추측하고 있음
- object가 진짜 bounding box안에 있는지? 에 대한 확신의 정도가 confidence score이다.
- Predicted Bounding Box (예측된 바운딩박스)
- 예측된 바운딩 박스는 모델 이미지 상에서 물체의 위치와 크기를 예측한 사각형 영역이다
- 물체의 경계를 포함하고 있을 수 있고 아닐 수 있다.
- 0에 가까울 수록 object가 없다고 추측
- 1에 가까울 수록 object가 있다고 추측
- Class Classification(클래스 분류)
- 클래스 분류는 물체 검출 모델이 예측된 바운딩 박스에 할당된 물체 클래스이다.
- 클래스 정보는 바운딩 박스에 어떤 종류의 물체가 있는지 나타냄
- ex) 개, 고양이, 자동차 등
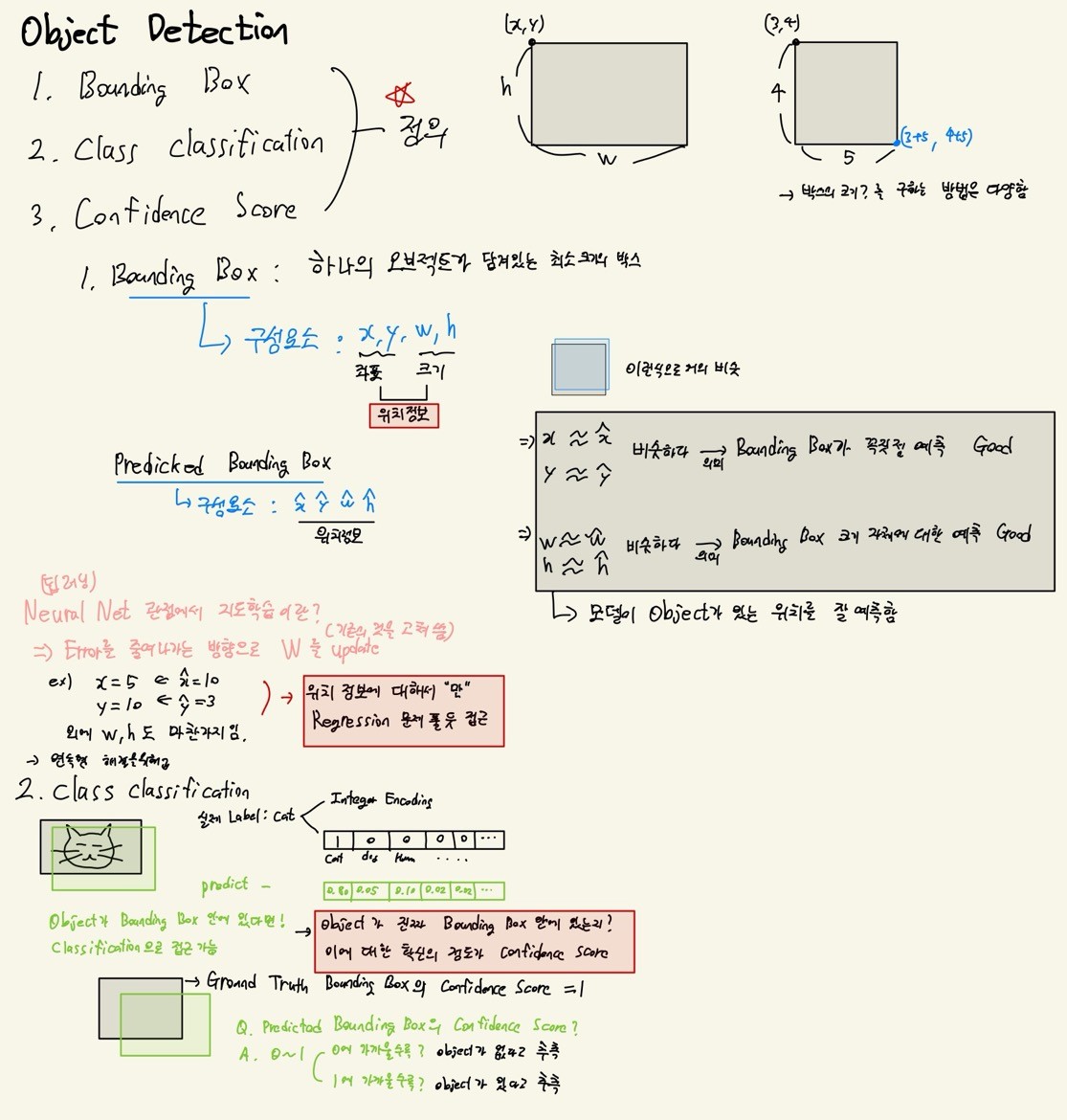
Bounding Box vs Prdicted Bounding Box
- Bounding Box: 하나의 오브젝트가 담겨있는 최소 크기의 박스
구성요소로는 x, y, w, h => 위치정보 포함
- Predicted Bounding Box: 예측된 바운딩 박스
구성요소로는 , , , => 위치정보 포함x, y, , = 좌표 정보
w, h, , = 크기 정보
- x 이거나 y 이면 Bounding Box가 꼭지점 예측을 잘했다.
- w 이거나 h 이면 Bounding Box 크기에 대한 예측을 잘했다.
=> 모델이 Object가 있는 위치를 잘 예측함
=> 겹치는 영역이 많을 수록 좋은 예측
CNN의 Object Detection에서 역할
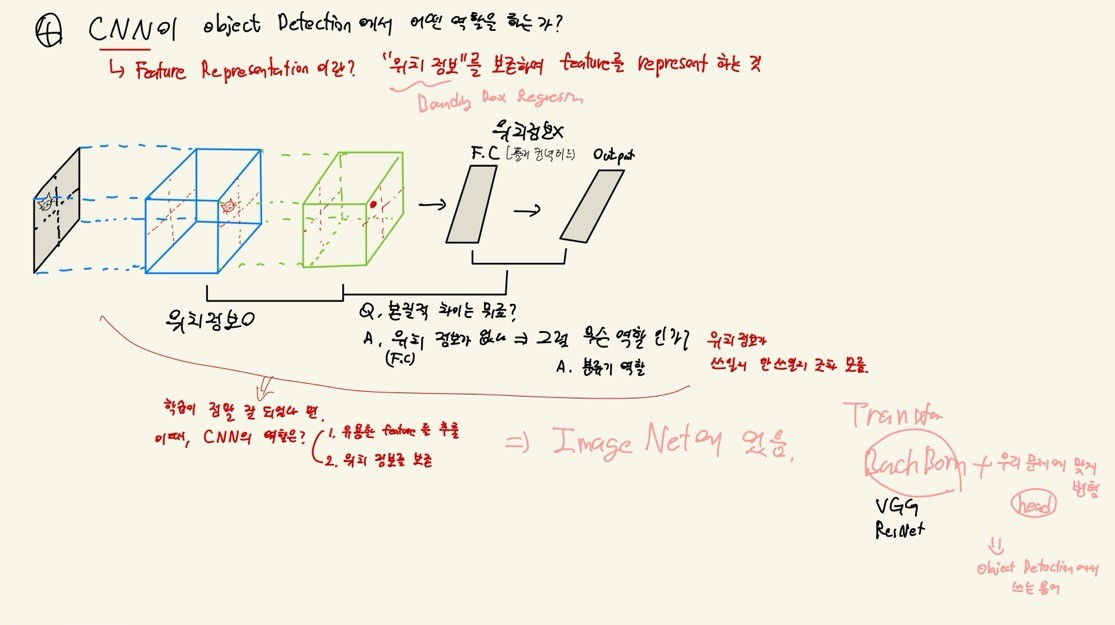
- feature representation (특징 추출)
- CNN은 이미지의 특징 추출하기 위해 여러개의 Conv층과 Pooling층으로 구성된다.
- Conv층은 이미지에서 다양한 특징을 감지하는 필터를 사용하여 입력 이미를 feature map으로 변환하여 이미지의 시각적 특징을 포착함
- 특징 추출과정을 통해 CNN은 이미지의 일반적인 특징을 학습하고 추출함
- 이런한 특징은 이미지에서 물체를 식별하는데 도움이 된다.
- Region Proposal (영역 제안)
- Object Detection에서 CNN은 주요 특징을 사용하여 이미지에서 객체가 존재할 수 있는 후보 영역을 제한한다.
- Selective Search, Region Proposal Network(RPN) 등의 알고리즘을 사용하여 생성
- 이 과정에서 CNN은 주요한 특징을 식별하여 후보영역을 추출하고 무체가 존재할 가능성이 있는 위치를 예측할 수 있음
- Object Localization (물체 위치 파악)
- 특징 표현을 사용하여 CNN은 객체를 포함하는 후보 영역의 위치를 정확하게 파악함
- 이를 통해 객체의 bounding box를 예측하고, 객체의 위치를 특정한다.
Annotation
- Image Annotation (이미지 어노테이션)
- 객체검출, 객체분할, 이미지 분류 등의 작업을 위해 사용된다.
- 객체 검출은이미지 내의 개별 객체를 둘러싸는 경계 상자를 어노테이션하여 해당 객체의 위치와 크기를 표시함
- 객체 분할에서는 이미지 내의 픽셀을 특정 객체의 일부로 분류하여 해당 영역을 어노테이션함
- 이미지분류에서는 이미지에 대한 레이블을 부여하여 이미지가 어떤 클래스에 속하는지를 나타냄
- Text Annotation (텍스트 어노테이션)
- 텍스트 데이터에 대한 어노테이션은 문장 내의 특정 단어나 구를 강조하거나 주석을 추가하는데 사용
- 감성분석, 텍스트분류, 명명된 엔티티 인식 작업에 사용
- Video Annotation (비디오 어노테이션)
- 비디오에 대한 어노테이션은 프레임마다 객체의 움직임이나 행동을 추적하는데 사용됨
- 동작인식, 객체 추적 작업에 활용된다.
YOLO
- 실시간객체 탐지를 위한 딥러닝 기반의 알고리즘
- 한 번의 순방향 전파를 통해 이미지 전체를 한번에 보고 객체를 탐지
- 이는 기존의 객체 탐지 방법과 다르게 이미지를 격자로 나누지 않고 전체 이미지에 대한 한번의 추론을 수행하여 빠르고 효율적임
특징
- 실시간 처리속도: 한번의 전방향 패스만으로 객체를 탐지하여 실시간 처리속도를 제공함
ex) 자율주행자동차, 보안 시스템, 로봇 - 객체 탐지 및 분류: 이미지 내의 객체를 탐지하고 분류할 수 있고 이미지 내의 여러 객체의 유형과 위치를 식별함
- 단일 네트워크 하나의 신경망으로 모든 것을 수행하여 복잡한 파이프라인이 필요하지 않고, 개발 및 배포를 단순화함
- 다양한 응용분야 보안감시, 교통흐름분석, 의료영상, 자율주행자동차 등의 분야에 사용
# 라이브러리 설치
!pip install ultralytics
# YOLO 불러오기
from ultralytics import YOLO
# YOLO 모델 선언
model = YOLO()
# 모델 학습
model.train()
# 성능 평가
model.val()
# 예측
model.predict(save=True, save_txt=True)
뒤늦게 프로그래밍을 시작한 응애