
언어지능 딥러닝
언어지능을 이해하기 위해서는 언어를 수치로 변화해야 한다.
예를 들어, 연설문의 경우 특정 키워드를 추출하여 그 키워드를 수치로 이루어지는 벡터로 변환한다.
내가 만약 검색창에 연설문의 벡터와 유사한 벡터를 가지는 키워드를 입력 시 연설문이 상단에 노출된다.
또 다른 예시로는 넷플릭스의 추천 컨텐츠이다.
넷플릭스의 A영화에 대해 줄거리 및 키워드들의 수치적으로 벡터가 생성되어 있다.
여기서 우리가 보고싶었던 영화나 장르를 선택하거나 시청했다면 기록이 남는데, 이 기록에서 우리가 좋아하는 장르나 컨텐츠의 벡터가 생성된다.
넷플릭스는 이와 유사한 벡터를 가진 비디오를 추천해준다.
그래서 먼저 어떤 컨텐츠나 연설문, 문장을 이해하기 위해서는 키워드를 뽑아야하는데, 그 방법 중 하나가 TF-IDF 이다.
TF-IDF
-
Term Frequenct-Inverse Document Frequency의 약자로 자연어 처리에 사용되는 텍스트 데이터의 특징을 추출하는 기법 중 하나이다.
-
문서 내에서 각 단어의 중요성을 수치적으로 표현함
-
이를 사용하여 벡터 표현을 생성할 수 있다.
-
TF: 문서 내에서 특정 단어의 출현 빈도를 나타낸다. 즉, 단어가 문서 내에서 얼마나 자주 등장하는지 나타낸다.
-
IDF: 전체 문서 집합에서 특정 단어가 얼마나 공통적으로 나타나는지를 나타낸다. (단어의 희귀성을 의미하고, IDF가 높을 수록 드물게 등장하는 것)
-
One-Hot-Encoding
-
단어를 수치화 하는 방법은 One-Hot-Encoding을 사용한다.
-
하지만,
One-Hot-Encoding은 자연어 단어 표현에는 부적합 하다- 단어가 너무 많고 신조어 같은 것이 생겼을 때 표현이 어려움
- 연관성을 표현하기 어렵다.
- 예를 들어, One-Hot-Encoding 되어 A(1, 0, 0) / B(0, 1, 0) / C(0, 0, 1) 처럼 구분하고자 하는 벡터의 갯수 만큼 생성된다.
- 벡터 좌표로 표현하면 모두 90도가 이루어져 아무 관련이 없다는 결론이 나와 연관성을 표현하기 어렵다.
- 만약 데이터가 백만 개가 있으면 원 핫 인코딩하면 더 추가 되어 1조 개가 된다.
- 이것을 고차원 저밀도로 복잡한 벡터를 구성한다.
분포가설
분포가설은 벡터의 크기가 작으면서 단어의 의미를 표현하는 방법이다.- 비슷한 문맥에서 함께 나타나는 단어들은 의미적으로 유사하거나 관련이 있다는 것을 말하고 두가지 데이터 표현 방법이 있다.
- 카운트 기반 방법
- 예측 방법
Jaccard Similarity
- 두 문장을 각각 단어의 집합으로 만든 뒤 두 집합을 통해 유사도 측정하는 방법
- 두 집합의 교집합인 공통된 단어의 개수 / 집합이 가지는 단어의 개수
- 0 ~ 1 사이의 값을 가짐
자카드유사도 코드사용
# 라이브러리 불러오기
import numpy as np
from sklearn.metrics import accuracy_score
# array 생성
a = np.array([1,3,2])
b = np.array([1,4,5])
c = np.array([4,1,5])
d = np.array([1,1,0,0])
e = np.array([1,1,0,2])
f = np.array([1,0,1,0])# 원소 하나 하나가 같은지 다른지 확인
print('a b 비교:', accuracy_score(a,b))
print('b c 비교:', accuracy_score(b,c)) # 리스트 형태라 순서 고려
print('a c 비교:', accuracy_score(a,c))
print('d e 비교:', accuracy_score(d,e))
print('d f 비교:', accuracy_score(d,f))
>
a b 비교: 0.3333333333333333
b c 비교: 0.3333333333333333
a c 비교: 0.0
d e 비교: 0.75
d f 비교: 0.5-
집합(Set) 형태: 집합은 요소의 순서를 고려하지 않으며, 각 요소는 중복되지 않습니다. 따라서 자카드 유사도를 계산할 때, 집합은 순서와 중복을 고려하지 않는다.
-
리스트(List) 형태: 리스트는 요소의 순서를 유지하고 중복을 허용할 수 있습니다. 따라서 리스트를 사용하여 자카드 유사도를 계산할 때, 요소의 순서가 중요하며 중복된 요소도 고려함
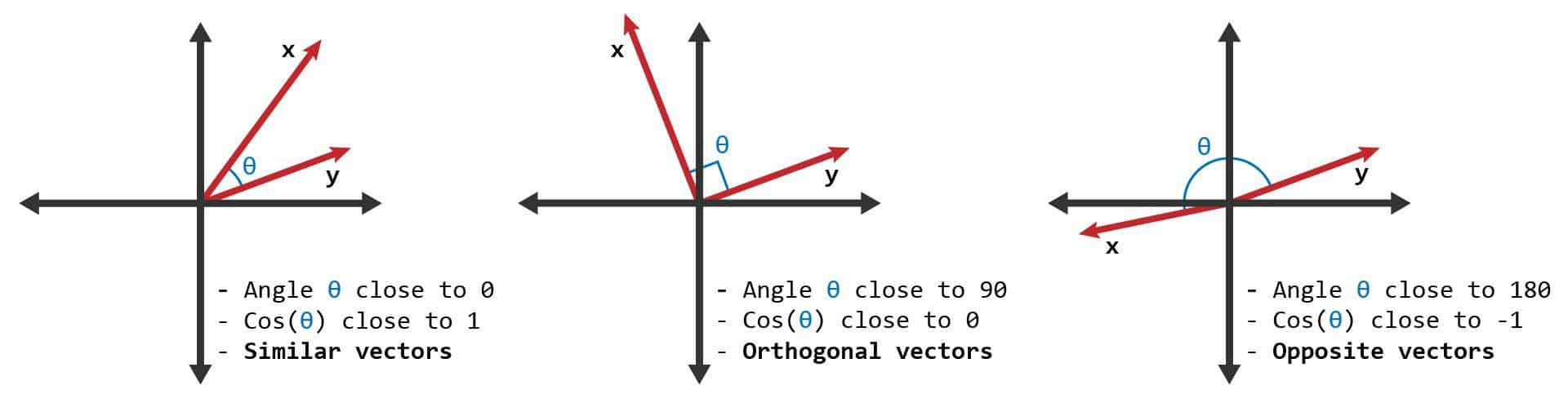
Cosine Similarity
- 두개의 벡터값에서 코사인 각도를 구하는 방법
- -1 ~ 1 사이의 값을 가진다.
x, y로 표현하면,
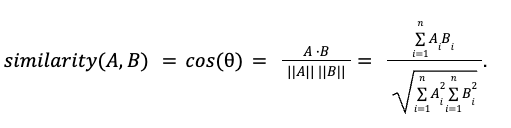
양의 관계로 Similar vector를 의미한다.
관계가 없음을 의미하고, Orthogonal(직교) vector를 의미한다.
음의 관계로 Opposite vector를 의미한다.
코사인유사도 코드사용
TfidfVectorizer와 cosine_similarity 사용
# TF-IDF 특성으로 변환하는 라이브러리
from sklearn.feature_extraction.text import TfidfVectorizer
# consine similarity 함수 라이브러리
from sklearn.metrics.pairwise import cosine_similaritysentence = ("휴일인 오늘도 서쪽을 중심으로 폭염이 이어졌는데요, 내일은 반가운 비 소식이 있습니다.",
"폭염을 피해서 휴일에 놀러 왔다가 갑작스런 비로 인해 망연자실하고 있습니다.")
# TfidfVectorizer 생성
vector = TfidfVectorizer(max_features=100)
# 텍스트 문장(sentence)을 TF-IDF 벡터로 변환
tfidf_vector = vector.fit_transform(sentence)
# 결과 출력
print(cosine_similarity(tfidf_vector[0], tfidf_vector[0]))
print(cosine_similarity(tfidf_vector[0], tfidf_vector[1]))
>
[[1.]]
[[0.05325384]]- 결과가 -1 ~ 1 사이 값으로 출력되지만, 음수인 경우는 어떤 의미도 갖지 않는다는 것을 의미한다.
- 일반적으로 0~1 사이의 값을 가지고
- 0에 가까울수록 단어의 중요성이 낮다.
- 1에 가까울수록 단어의 중요성이 높다.
machine learning
비지도학습
- 비지도 학습은 정답이 없는(unlabeled) 데이터를 사용하여 모델을 학습시키는 방법이다.
- 모델은 데이터의 구조, 패턴 또는 규칙을 발견하거나 데이터를 그룹화(clustering)하는 방법을 학습합니다.
- 대표적인 예로는 군집화(Clustering), 차원 축소(Dimensionality Reduction), 이상치 탐지(Outlier Detection) 등이 있다.
Minkowski distance
- 민코프스키 거리는 유클리드 거리와 맨해튼 거리를 일반화한 개념이다.
- 두 점 사이의 거리를 측정하는 방법 중 하나이다.
- p는 거리의 차수를 나타낸다.
- 맨해튼 거리
- p = 1 인 경우
- 각 축에 대해 거리를 구한 후 합산하기 때문에, 이동 거리가 각 축에 대해 직선으로만 이루어진다고 가정할 때 유용
- 유클리드 거리
- p = 2 인 경우
- 선 거리로 두 점 사이의 가장 짧은 거리를 측정하며, 데이터 간의 관계를 고려할 때 유용
Major Clustering Approaches
K-means
- 가장 비슷한 특징을 가진 것끼리 묶는 것 (거리 특징 등)
- 가장 많이 사용하는 방법
- 단점은 k의 수를 미리 정해줘야한다.
KNN
-
k의 개수를 정하여 내부에 가장 많은 것을 선택하는 것
-
단점
-
k 값이 너무 크면 주변 이웃의 수가 많아지므로 모델이 단순해져 과소적합 발생
-
k 값이 너무 작으면 주변 이웃의 수가 적어지므로 모델이 너무 복잡해져 과대적합이 발생하고, 노이즈에 민감하게 반응한다.
-
k 값이 작으면 이상치가 주변 이웃에 큰 영향을 미칠 수 있음
-
hierarchical approach
- 계층적 접근 방식으로 단계적으로 분해하고 구조화한다.
- 문제를 작은 부분으로 나누어 해결한다 (의사결정 트리)
density-based approach
- 밀도 기반 접근 방식은 클러스터링 및 이상치 탐지와 같은 데이터 마이닝에 사용되는 방법 중 하나이다.
- 연속적인 클러스터 형성, 이상치 탐지에 사용한다.
Spectral Clustering Approach
- 스펙트럴 클러스터링 접근 방식
- 데이터를 임베딩된 고차원 공간에서 클러스터링하는 방법
- 데이터 포인트들 간의 유사성을 파악하고, 그래프 이론(graph theory)을 기반으로 클러스터를 형성
Clustering Ensemble Approach
-
클러스터 앙상블 접근 방식
-
다양한 클러스터링 알고리즘을 결합하여 보다 견고하고 정확한 클러스터링을 수행하는 방법으로 여러가지 클러스터를 결합하여 단일 클러스터링 결과를 생성하는 것이 목표이다.
-
대표적인 클러스터링 알고리즘으로는 k-means, DBSCAN, 스펙트럴 클러스터링
-
k-means의 k 값을 여러가지로 변경해 가며 결과를 취합하고 최종적으로 가장 좋은 것을 추출하는 것
-
클러스터링 결과의 안정성과 일반화 성능을 향상시킬 수 있으며, 다양한 클러스터링 알고리즘 간의 상호 보완적인 특성을 활용할 수 있음
지도학습
- 지도 학습은 입력과 정답(label 또는 target)을 모두 포함하는 데이터를 사용하여 모델을 학습시키는 방법이다.
- 모델은 입력과 정답 간의 관계를 학습하고, 새로운 입력에 대한 정확한 출력을 예측할 수 있다.
- 대표적인 예로는 분류(Classification)와 회귀(Regression)가 있다.
- 분류는 입력을 여러 클래스 중 하나로 분류하는 작업
- 회귀는 입력과 출력 간의 관계를 모델링하는 작업
강화학습
- 강화 학습은 에이전트(agent)가 환경과 상호작용하며 특정 작업을 수행하는 방법을 학습하는 방법이다.
- 에이전트는 환경으로부터 상태를 관찰하고, 이를 기반으로 행동을 선택하고, 선택한 행동에 대한 보상(reward) 또는 벌점(penalty)을 받습니다.
- 목표는 보상을 최대화하는 정책(policy)을 학습하여 최적의 행동을 선택하는 것이다.
- chatGPT, 알파고 등이 있다.
RSS_IR
# 파이썬에 없는 라이브러리 설치
!pip install feedparser
!pip install newspaper3k
!pip install konlpy- 라이브러리 불러오기
# URL을 입력받으면 페이지에 있는 <item> </item>을 가져오는 것
import feedparser
# 기사를 가져오기 위해 사용
from newspaper import Article
# 한국어 사용하기 위한 라이브러리
from konlpy.tag import Okt
# 반복 가능한 객체(예: 리스트 또는 문자열)의 요소들의 개수를 셀 때 유용하게 사용
from collections import Counter
# 웹 스크레이핑(scraping) 작업을 수행하여 웹 페이지에서 원하는 정보를 추출
from bs4 import BeautifulSoup - [단계1] 모든 RSS파일을 돌아다니며 기사의 제목/link를 추출함
urls = ["http://rss.etnews.com/Section901.xml",
"http://rss.etnews.com/Section902.xml",
"http://rss.etnews.com/Section903.xml",
"http://rss.etnews.com/Section904.xml"]
# 아래 함수는 RSS목록의 list안에 존재하는 모든 기사의 title, link를 list로 구성
def crawl_rss(urls):
# 함수 시작하는 시점에 빈 리스트를 만듦. 여기에 모든 기사를 채울 것임
array_rss = []
# [중복기사제거] 기사제목들의 집합을 구성(집합은 중복을 불허하기 때문임)
titles_rss = set()
# 주어진 4개의 RSS파일을 하나씩 방문(총 4번 돌 것이고, 901, 902, 903, 904)
for url in urls:
# 현재 어디에 있는지 출력
print("[Crawl URL]", url)
# 현재 url을 파싱한 후에 결과를 parse_rss에 저장
parse_rss = feedparser.parse(url)
# parse_rss에 있는 모든 entries/기사를 검색
for p in parse_rss.entries:
# [중복기사제거] 만약에 titles_rss라는 집합에 방금 찾으 제목이 없으면 추가
if p.title not in titles_rss:
# 기사에서 제목/link 추출 후 리스트에 추가
array_rss.append({'title': p.title, 'link': p.link})
# [중복기사제거] 집합에 현재 기사 제목이 없을 때만 추가
titles_rss.add(p.title)
else:
# [중복기사제거] 중복된다고 판단된 기사 제목 출력
print("Duplicated Article:", p.title)
return array_rss
# 실제 crawl_rss 실행
list_articles = crawl_rss(urls)
print(list_articles)- [단계 2] list에 존재하는 모든 링크를 돌아다니면서 본문 text를 긁어오기
# [단계 #2] list에 존재하는 모든 링크를 돌아다니면서 본문 text를 긁어오기
# 아래의 함수는 하나의 url을 입력받아서, 링크를 타고 들어가, 그 안에서 title과 text를 추출
# 언어는 한글로 기본 지정
def crawl_article(url, language='ko'):
# 현재 title과 text를 추출할 url을 프린트해줌
print("[Crawl Article]", url)
# Article을 사용하여 그 URL을 입력하고, 언어옵션지정(한글어 기본), 결과를 a에 저장
a = Article(url, language = language)
a.download()
a.parse()
# a에 해당하는 title과 본문(text)을 출력한다. / 불용어를 제거 함
return a.title, preprocessing(a.text)
# html 태그 제거
def preprocessing(text):
text_article = BeautifulSoup(text, 'html5lib').get_text()
return text_article
# list에 있는 모든 기사를 하나씩 방문
for article in list_articles:
# 그 기사의 link를 crawl_article 함수에 넣어 본문(text) 추출
_, text = crawl_article(article['link'])
# 추출된 본문을 'text'라는 속성으로 새로 만들어서 저장
article['text'] = text
# 첫 번째 기사를 출력하여 title, link, text가 모두 있는지 확인
print(list_articles[0])
추천시스템
추천시스템의 배경과 목적
- 파레토 법칙: 상위 20%가 80%가치를 창출한다.
- 롱테일 법칙: 하위 80%의 다수가 상위 20%보다 뛰어난 가치를 창출한다.
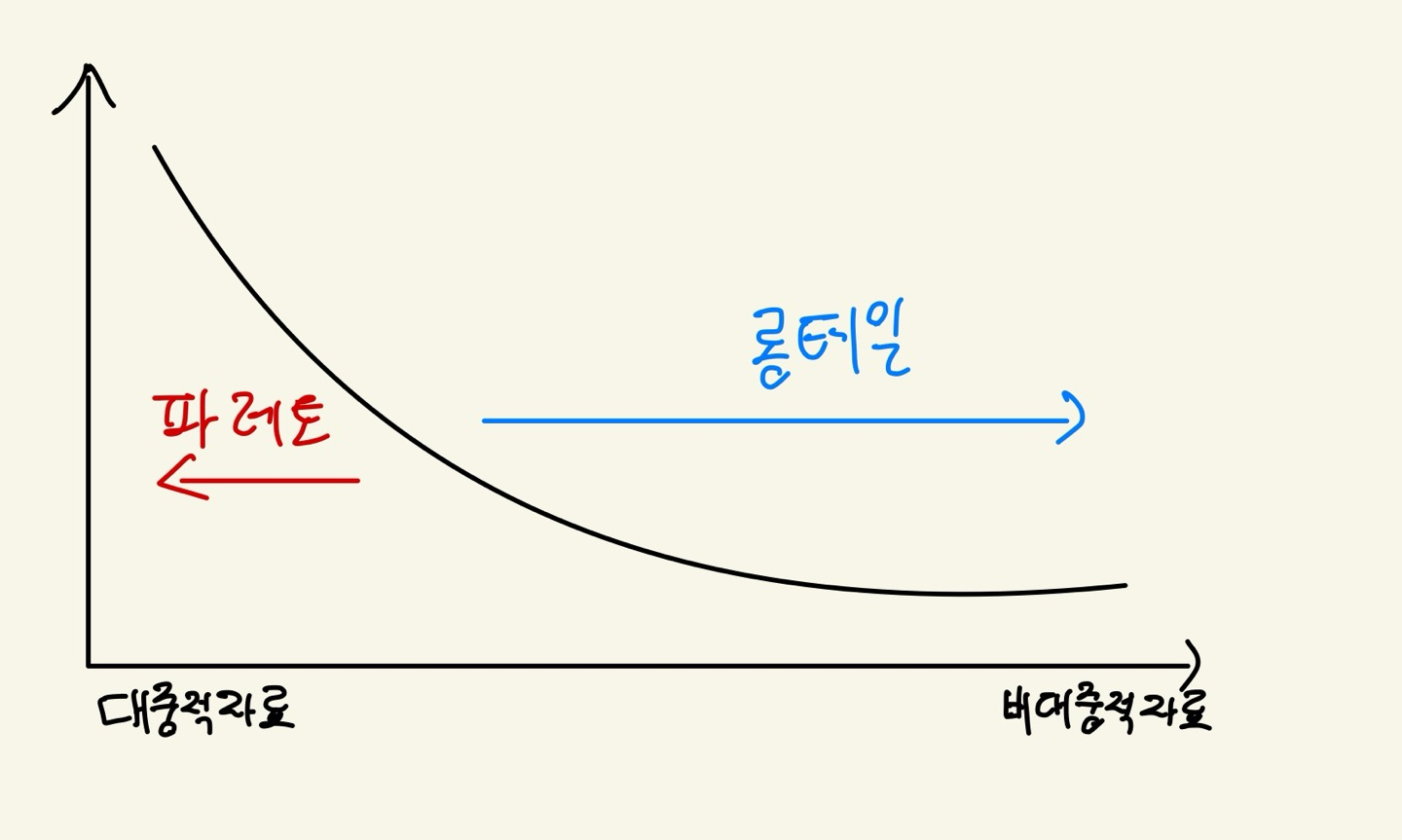
추천시스템: 사용자의 행동 이력, 사용자 간 관계, 상품 유사도, 사용자 컨텍스트에 기반하여 사용자의 관심 상품을 자동으로 예측하고 제공하는 시스템
=> 벡터화하여 코사인 유사도를 확인함
추천 알고리즘
Collaborative Filtering (CF)
-
컨텐츠를 벡터로 만들어 유사도 판단 (코사인 유사도)
-
Cosine Similarity 기반 방식 (내적 기반의 유사도 연산 필수)
-
전체 User-item Matrix를 사용하여 추천 Item을 예측함
-
장점
- 최소한의 기본 정보만으로도 구현 가능
- 다양한 적용사례에서 적절한 정확도 보장
-
단점
- 아이템의 존재유무에 따라 메트릭이 바뀐다.
- 고차원 저밀도 벡터 이슈
- 새로운 사용자나 아이템이 추가되는데 따르는 확장성이 떨어짐
Content-based Filtering (CBF)
- 내용 자체의 키워드가 중요 (TF-IDF)
- TF-IDF 방식 (원하는 키워드가 존재하는지에 대한 카운팅 필수)
- 데이터 안에 내재한 패턴을 이용하는 기법
- 아이템의 속성에 기반하여 유사 속성 아이템을 추천
- Collaborative Filtering이 사용자의 행동이력을 이용하는 반면, 콘텐츠기반 필터링은 아이템 자체를 분석하여 추천을 구현함
- 장점
- 새로 추가된 아이템에 대해서도 추천 가능
- 단점
- 사용자의 선호도/취향을 특정 단어로 표현하기 어려움
- 추천하는 항목이 비슷한 장르에 머무르는 한계가 있음
