
4차 미니프로젝트의 두번째 주제는 '쿨루프 시공 여부 분류'로 했습니다.
여기서 쿨루프는 건물 옥상에 햇빛을 반사하고 열 흡수를 줄이는 목적으로 특수한 색상 또는 재료를 사용하는 것으로 햇빛을 반사하는 색과 아닌 것을 구분하는 모델을 만들었습니다.
이미지 데이터를 YOLO v8을 활용하여 분류하는 시간을 가졌습니다.
- 제공하는 이미지 데이터를 활용하여 쿨루프 시공 여부를 분류하는 모델을 생성
- 이미지 데이터를 직접 수집하여 roboflow를 사용해 쿨루프 시공 여부를 분류하는 모델을 생성
3일차
데이터 전처리
- zip파일 이미지를 제공받아 파일 압축해제
# 압축풀기
def dataset_extract(file_name):
with zipfile.ZipFile(file_name, 'r') as zip_ref:
file_list = zip_ref.namelist()
if os.path.exists(f'/content/{file_name[-14:-4]}/'):
print(f'데이터셋 폴더가 이미 존재합니다.')
return
else:
for f in tqdm(file_list, desc='Extracting', unit='files') :
zip_ref.extract(member=f, path=f'/content/{file_name[-14:-4]}/')- 압축을 해제한 데이터를 내 드라이브와 연결
# 구글드라이브 연결
from google.colab import drive
drive.mount('/content/drive')- 압축 해제
# 파일 압축 해제
dataset_extract('압축해제할 파일 경로')
압축 해제시 폴더가 사진처럼 생성됩니다.
YOLO모델은 이미지 폴더와 라벨 폴더 형식을 요구하여 폴더를 생성해야 합니다.
- YOLO 모델이 요구하는 형식의 폴더 생성
# 구조에 맞는 디렉토리 생성
import os
os.makedirs('/content/Dataset/images/train')
os.makedirs('/content/Dataset/images/val')
os.makedirs('/content/Dataset/labels/train')
os.makedirs('/content/Dataset/labels/val')
- 이미지와 라벨 데이터를 각각 train, val으로 이동 시켜야 합니다.
- 리스트 형태로 변수 이미지 파일과 라벨링 데이터를 저장
- 정렬하여 데이터와 라벨 데이터 맞춰줌
# Dataset metadata 입력
won_list1 = ['/content/oof_images']
won_list2 = ['/content/olo_labels/obj_train_data']
# 파일 담아오기
image_files = ''
for won in won_list1:
image_files = (glob.glob(won+'/*.jpg'))
label_files = ''
for won in won_list2:
label_files = (glob.glob(won+'/*.txt'))
# 정렬
image_files.sort()
label_files.sort()- 각각의 이미지, 라벨 데이터를 train_test_split으로 나눠 줌
from sklearn.model_selection import train_test_split
train_x, val_x, train_y, val_y = train_test_split( image_files, label_files, test_size=0.2, random_state=2024 )- 생성한 train_x, val_x, train_y, val_y 데이터를 각각의 폴더로 이동
# train_x의 이미지 파일을 '/content/Dataset/images/train' 폴더로 이동
for image_file in train_x:
shutil.move(image_file, '/content/Dataset/images/train')
# val_x의 이미지 파일을 '/content/Dataset/images/val' 폴더로 이동
for image_file in val_x:
shutil.move(image_file, '/content/Dataset/images/val')
# train_y의 라벨 파일을 '/content/Dataset/labels/train' 폴더로 이동
for label_file in train_y:
shutil.move(label_file, '/content/Dataset/labels/train')
# val_y의 라벨 파일을 '/content/Dataset/labels/val' 폴더로 이동
for label_file in val_y:
shutil.move(label_file, '/content/Dataset/labels/val')모델 생성
- YOLO 모델에 적용할 yaml파일을 생성
import yaml
classes = { 'path' : '../Dataset/images/', # 이미지 파일 경로
'train' : './train', # 생성한 train 경로
'val' : './val', # 생성한 val 경로
'nc' : 2,
'name' : ['cool roof', 'generic roof']
}- 생성한 yaml 데이터 파일 생성
with open('./Dataset/data.yaml', 'w') as file:
yaml.dump(classes, file)- yaml 파일의 경로 설정 settings
!pip install ultralytics
from ultralytics import YOLO, settings
settings['datasets_dir'] = '/Dataset/'
settings.update()- YOLO 모델 사용
# YOLO 모델 불러오기
model = YOLO(model='yolov8n.yaml', task='detect')
# 모델 학습
model.train(data='/content/Dataset/data.yaml',
epochs=100,
patience=7)
# 성능 평가
model.val()- 새로운 사진 데이터를 가져와 모델이 잘 예측하는지 predict 해봄
# 예측
# image 폴더 생성 후, 따로 저장한 이미지 데이터를 predict
model.predict(source = '../content/Dataset/image/',
save=True,
save_txt=True,
line_width=2
)
- 예측 결과1

- 예측결과 2

cool roof와 generic roof를 높은 정확도로 분류하는 수준까지는 아니지만 어느정도 구분하는 모델을 생성하였습니다.
4일차
4일차에는 직접 네이버지도, 구글지도의 위성사진을 수집하여 roboflow를 사용하여 bounding box를 생성했고, 그 이미지를 이용하여 YOLO모델에 돌려보았다
- roboflow에서 bounding box 생성
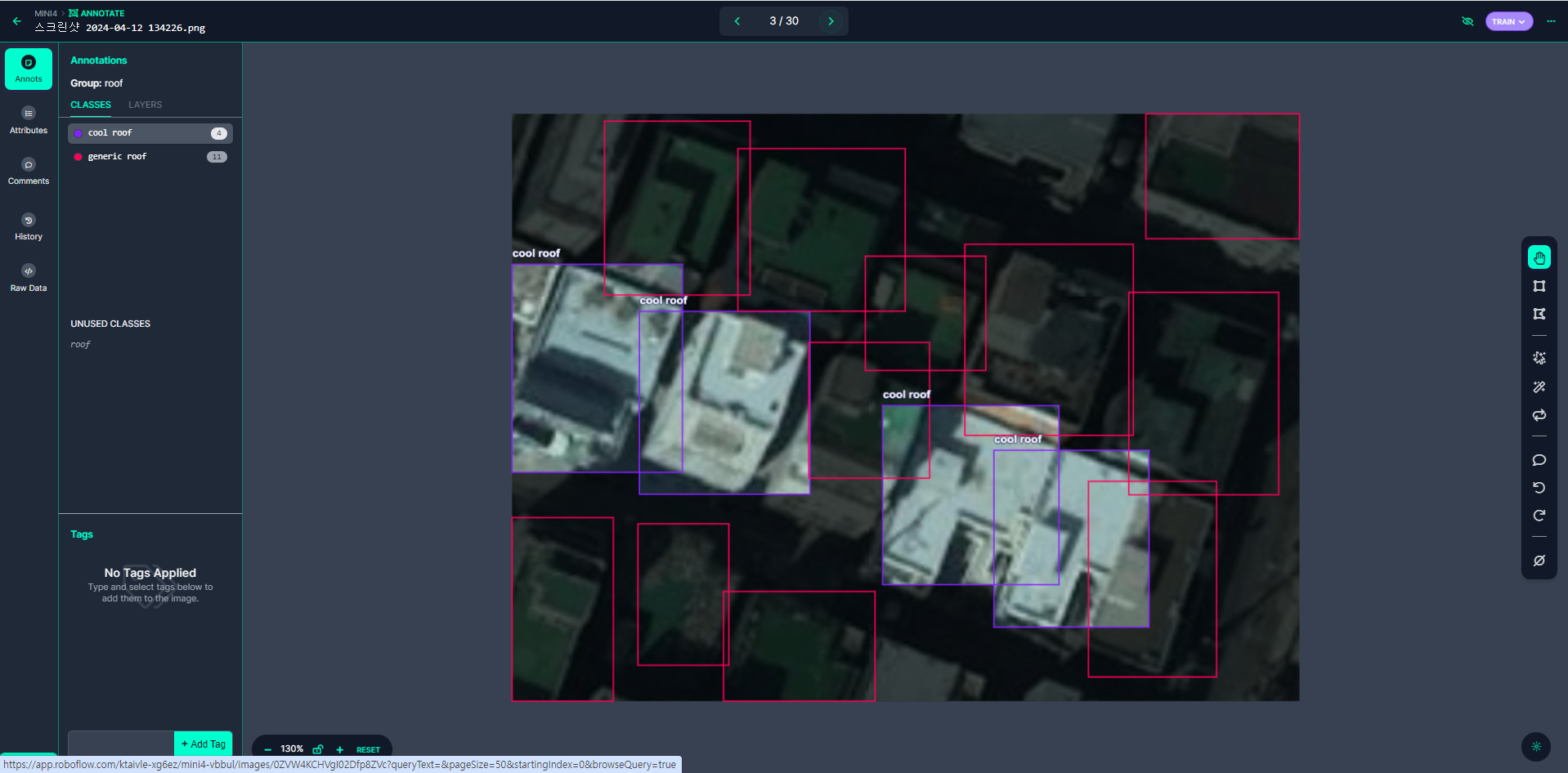
이처럼 바운딩 박스를 하나하나 생성해 준다.
- 전처리 설정 및 Augmentation 설정
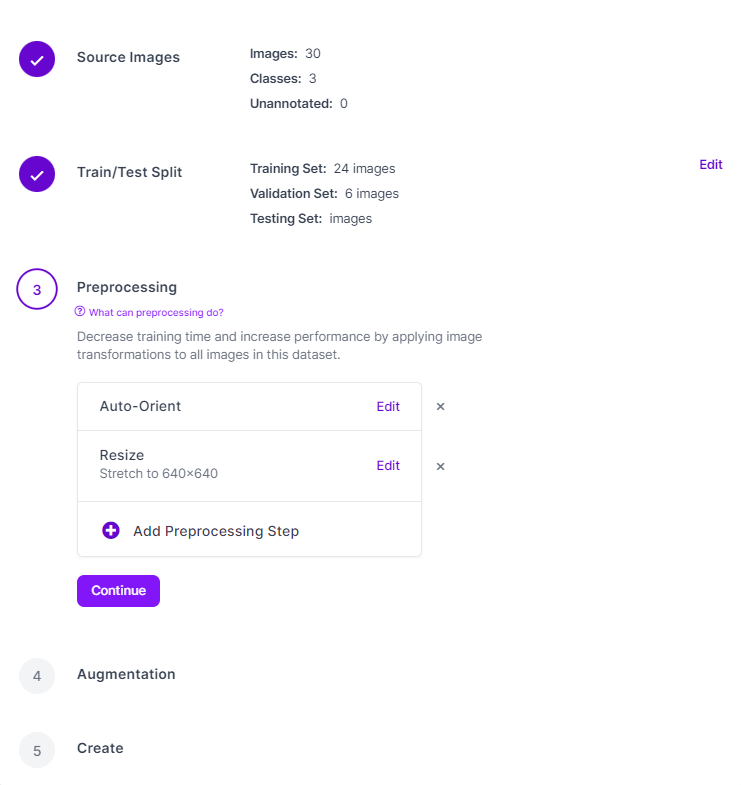
-
생성한 train, valid 데이터를 YOLOv8모델로 가져옴
-
YOLO 모델을 사용하기 위한 yaml파일 생성
# yaml 파일 생성
import yaml
yaml_data = {
'path' : '../drive/MyDrive/KT_deep_visualize/mini4',
'train': './train',
'val': './valid',
'names' : ['cool roof', 'generic roof'],
'nc' : 2
}
with open ('/content/drive/MyDrive/KT_deep_visualize/mini4/yaml_data.yaml', 'w') as f:
yaml.dump(yaml_data, f)- YOLO v8모델 생성 및 settings 경로 설정
# 라이브러리 불러오기
from ultralytics import YOLO, settings
# 경로설정
settings['datasets_dir'] = '/content'
settings.update()
# YOLO 모델 선언
model = YOLO(model='yolov8n.yaml', task='detect')- YOLO 모델 학습하기
model.train(data='../content/drive/MyDrive/KT_deep_visualize/mini4/yaml_data.yaml',
epochs=150,
patience=7,
pretrained=False,
verbose=True,
seed=2023,
)수집한 이미지 데이터는 30장씩 모아서 사진을 합쳐서 YOLO v8 모델에 적용해봤습니다.
처음엔 30장으로 개별적으로 수행해 봤을땐 정확도가 낮게 나왔지만,
팀원들과 수집한 이미지 데이터를 합하여 train데이터 수를 늘려본 결과 이 전보다 정확한 결과를 얻을 수 있었습니다.

뒤늦게 프로그래밍을 시작한 응애