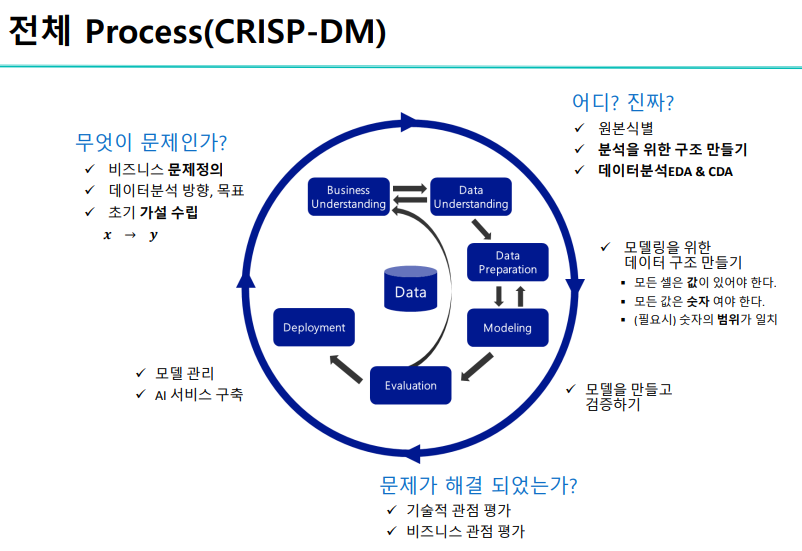
1.딥러닝 기초 복습
- 모델링의 목표는?
학습할 때 사용하지 않을 data을 잘 맞추는 것이다.
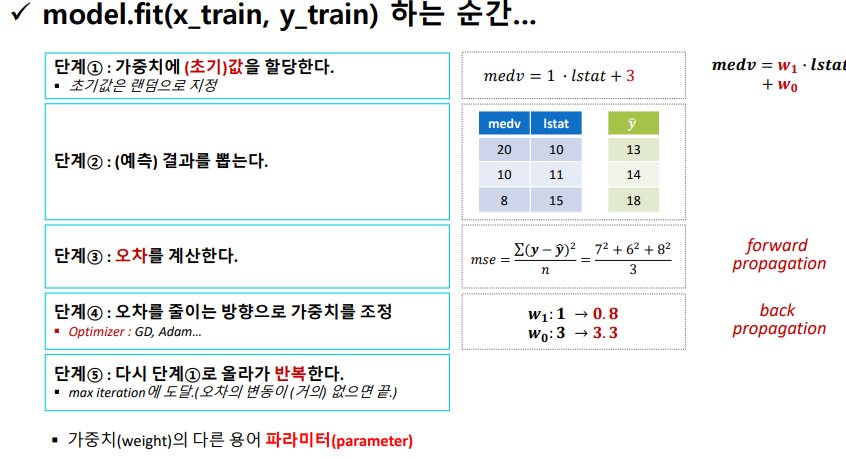
loss function은 학습하는 '도중'에 오차를 계산하는 함수이다.
오차를 줄이고 싶다면, 가중치를 조정해서 단계를 반복해야한다.
-
순전파란?
입력층에서 출력층으로 신호가 전달되는 과정
가중치와 활성화 함수를 통해 입력값을 변환하고 다음 뉴런으로 신호 전달
단순히 입력값을 네트워크에 출력시켜서 출력값을 계산하는과정이다. -
역전파란?
신경망의 가중치를 조정해서 학습하는 과정이다.
오차를 계산하고 역방향으로 가중치를 조정해서 오차를 최소화하는 과정이다.
오차를 거꾸로 전파해서 가중치를 조정하며, 경사하강법을 사용해서 오차를 최소화하는 방향으로 가중치를 업데이트한다.
(순전파와 역전파는 상호 의존적인 관계이다)
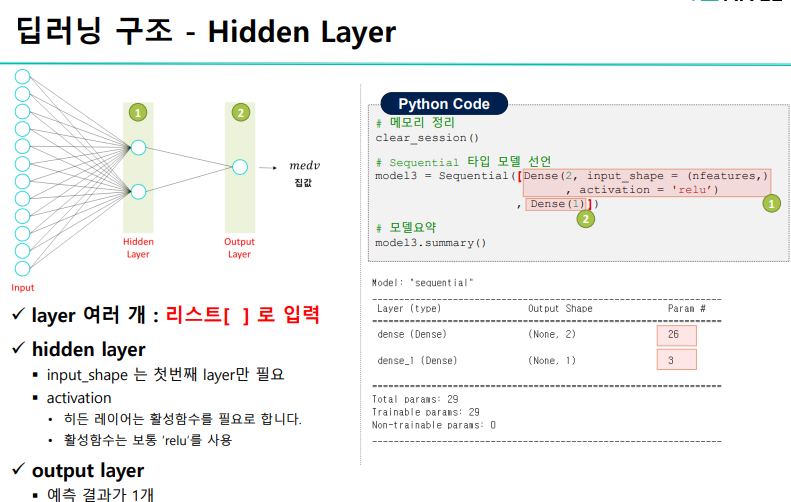
히든 레이어의 수가 많다고 무조건 깊은 모델은 아니다.
input과 output 사이에 있는 layer= 모두 hidden layer
히든 레이어는 활성화함수가 필요하며 대체적으로 relu 함수를 이용한다.
(옛날에 hidden layer에서 시그모이드함수를 썼는데 문제가 발생했었음)
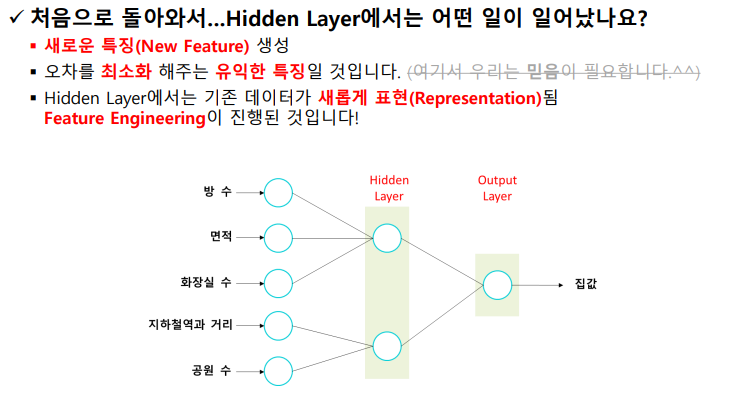
1번째 hidden layer : (5,)
2번째 hidden layer : (2,)
-> 기존 데이터가 추상화 과정을 통해서 새롭게 표현되었음
-> feature engineering이 진행되었다는의미
의미있는 data : 어떻게 만들어지는가?
-> 오차를 최소화하기 위해서 가중치를 조정한다.
-> 어떤 과정을 통해서 최종 target을 예측하며, 오차를 최소화하기 위해 중간 hidden layer은
최선을 다하므로, 의미가 있다고 본다.
-> 이때 머신러닝은 feature engineering을 하지만, 딥러닝은 hidden layer가 알아서 오차를 최소화하는 방향을 만들면서 가중치를 조정한다.
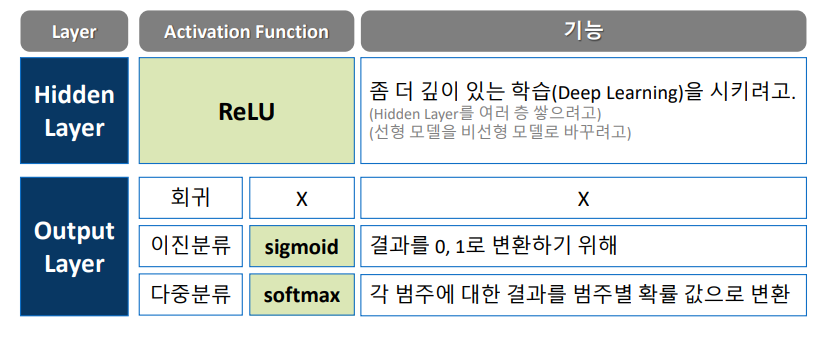
학습을 비선형 모델로 바꾸려고 relu를 쓴다.
회귀는 숫자 그 자체를 출력하면 되므로, 특정 활성화 함수 필요가 없다.
이진분류는 y값을 0 또는 1로 변환하는 시그모이드를 쓴다.
다중분류는 y값을 '묶어서' 총합이 1이 되는 소프트맥스를 쓴다.
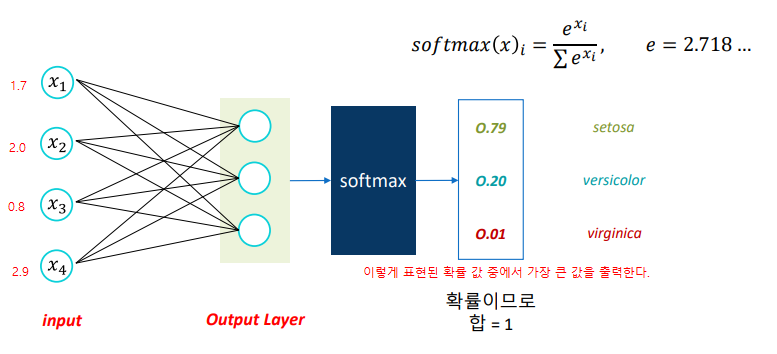
이때 확률의 값이 가장 큰 인덱스를 출력해야한다.
argmax 함수를 활용해야한다.
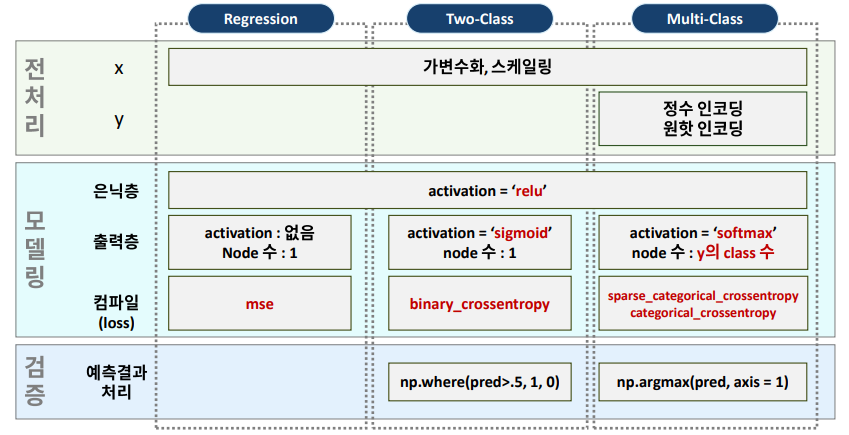
- 코딩할 때 주의할 점
: 사이킷런 라이브러리와 다르게 딥러닝 keras 라이브러리는 처리를 따로 하여야함
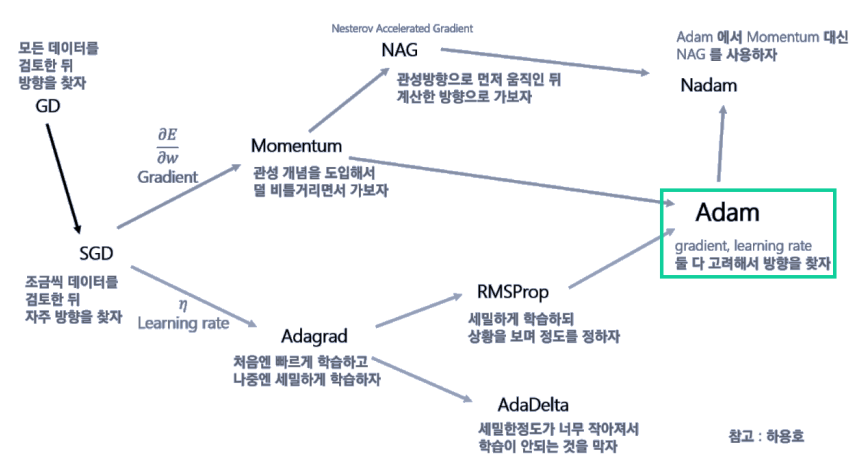
최적화함수에서 'adam'을 사용했을 때 local minimizer 문제를 대부분 해결할 수 있기 때문에,
adam으로 사용하는 것을 추천
적절한 은닉유닛수 및 hidden layer의 개수는 절대적으로 옳은 케이스가 없으며
튜닝 작업을 통해서 검증 set으로 성능을 비교하면서, 가장 좋은 파라미터를 찾는게 좋다.

-> 이때 다 해보는 작업은? grid search
-> 무작위로 해보는 작업은? random search
(논문을 보면서 어떤 도메인 및 작업단계에서 어떤 작업이 유리한지 확인하면 good)
요즘 트렌드는?
설계 자체를 일부러 복잡하게 만든다.
(예: 에폭수를 20이 아닌 2000으로...)
규제(ex: early stopping) 를 하면서 모델을 일반화시킨다.
(예: 은닉층과 노드의 수를 크게 주고서 가중치를 규제하여 과적합을 회피한다)
2.실습 : MNIST

이미지 데이터는 2차원데이터, 1차원데이터로 변환하여 딥러닝을 실행할 수 있다.
'픽셀'을 생각하면 된다.
이미지는 픽셀이며, array(배열)형태이다.
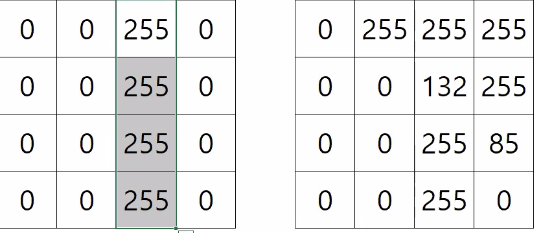
이때 예측단위는? 이미지 1장 (2차원 단위)
이미지는 여러개이므로, 3차원이다.
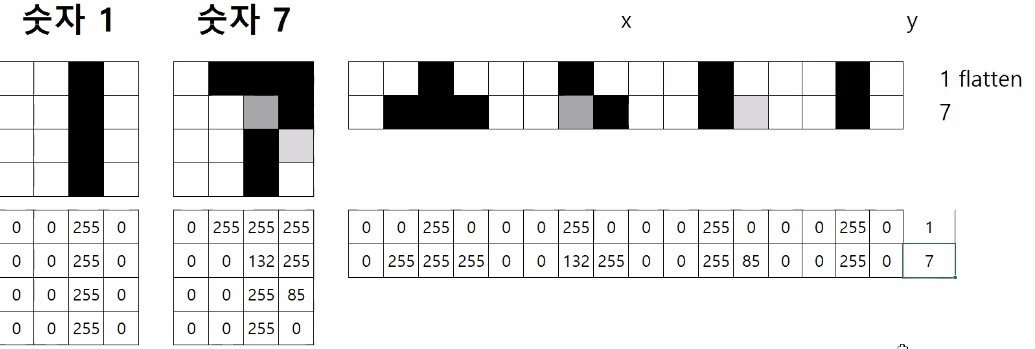
2차원데이터(이미지 1장)을 1차원데이터로 변환해본다.
그 이후 1차원으로 변환된 값을 가지고 숫자를 예측해본다.
- 실습 예시
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.metrics import *
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense, Flatten
from keras.backend import clear_session
from keras.optimizers import Adam
from keras.datasets import mnist, fashion_mnist
# 학습곡선 함수
def dl_history_plot(history):
plt.figure(figsize=(10,6))
plt.plot(history['loss'], label='train_err')
plt.plot(history['val_loss'], label='val_err')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend()
plt.grid()
plt.show()
# 케라스 데이터셋으로 부터 mnist 불러오기
(x_train, y_train), (x_val, y_val) = mnist.load_data()
x_train.shape, y_train.shape
#x_train: 3차원 : 28 * 28 짜리 2차원 데이터가 60000개
#y_train: 1차원 : 60000
#앞에 있는 1번째는? 데이터의 건수를 의미한다.
class_names = ['0','1','2','3','4','5','6','7','8','9']
## 데이터 살펴보기
# 아래 숫자를 바꿔가며 화면에 그려 봅시다.
n = 120
plt.figure()
#인덱스가 n인 28*28 데이터 출력
plt.imshow(x_train[n], cmap=plt.cm.binary)
plt.colorbar()
plt.show()
#옵션 추가
np.set_printoptions(linewidth= np.inf)
x_train[n]
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.imshow(x_train[i], cmap=plt.cm.binary)
plt.xlabel(class_names[y_train[i]])
plt.tight_layout()
plt.show()
#2차원인 데이터를 1차원으로 펼쳐보기
#기존 데이터
x_train.shape, y_train.shape, x_val.shape, y_val.shape
#reshape활용하여 1차원 변환
#행은 유지하고 , 열을 알아서 계산
# = 60000건은 동일 , 그 외 알아서 계싼
x_train = x_train.reshape(60000, -1)
x_val = x_val.reshape(10000, -1)
#결과
x_train.shape, x_val.shape
#스케일링
#최댓값이 255여서 다음과 같이 나눔
x_train = x_train / 255.
x_val = x_val / 255.
##모델링
nfeatures = x_train.shape[1]
nfeatures
clear_session()
#layer은 1개, 해당 10이 output layer
model = Sequential(Dense(10, input_shape = (nfeatures,), activation = 'softmax'))
model.summary()
model.compile(optimizer=Adam(learning_rate=0.001), loss= 'sparse_categorical_crossentropy' )
history = model.fit(x_train, y_train, epochs = 20, validation_split=0.2).history
#학습성능으로 에폭수에 따른 오차 확인
dl_history_plot(history)
#예측및평가
pred = model.predict(x_val)
pred[:5]
#argmax: 확률 최대인 값의 인덱스를 출력 (변환 작업 필요)
pred_1 = pred.argmax(axis=1)
pred_1[:5]
#결과확인
# f1 score을 보고 어떤 인덱스가 분류가 잘 되었는지, 잘못되었는지 확인하면 된다.
print(confusion_matrix(y_val, pred_1))
print(classification_report(y_val, pred_1))
- 후속 분석
: f1 score을 통해 어떤 숫자가 예측이 잘되었고 예측이 안되었는지 확인가능
: 해당 결과로는 숫자 5의 f1 score이 0.88로 가장 저조한 숫자 = 예측이 가장 안된 숫자
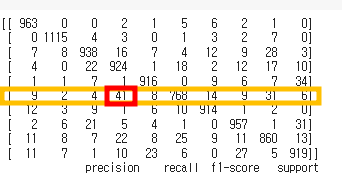
확인해본 결과, 숫자 5가 3으로 잘못 예측되어 결과가 나옴
3.CNN
1. CNN 컨셉
CNN이란?

- 예시: 고양이
- 귀/코/입/눈 등 각 부위를 잘 예측해야한다.
- 고양이의 특정 부분을 잘 캐치해내는 필터를 만들어야한다.
: 귀 부분을 찾으면 숫자가 커지며, 없으면 0에 가까워짐
-> CNN은 지역적인 부분 (특징)을 찾아낸다는 점에서 특이점이 있다.
CNN 모델 설계 구조
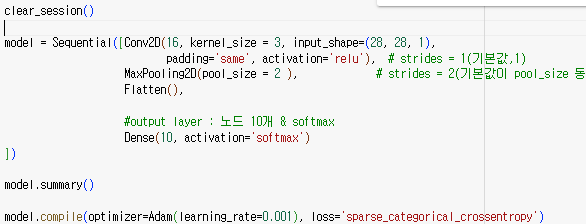
- CNN은 '3차원 데이터'를 입력해야한다.
(3차원 input_shape을 요구)
(RGB : 색의 삼원색을 표현해야하므로 3차원) - 4차원일 경우, 3차원으로 변환해야한다.
- 흑백은 보통 2차원, 컬러는 3차원으로 만들어진다.
-
3*3 형태인 필터를 가지고 진행
-
input_shape은 3차원 형태여야하므로 (28,28,1)
-
Flatten(): 데이터를 1차원으로 변환
-
CNN 이어도 Dense로 연결해야한다
: Dense layer로 연결 -
Conv2D:
-
MaxPooling2D
2. 딥러닝 구조 - CNN
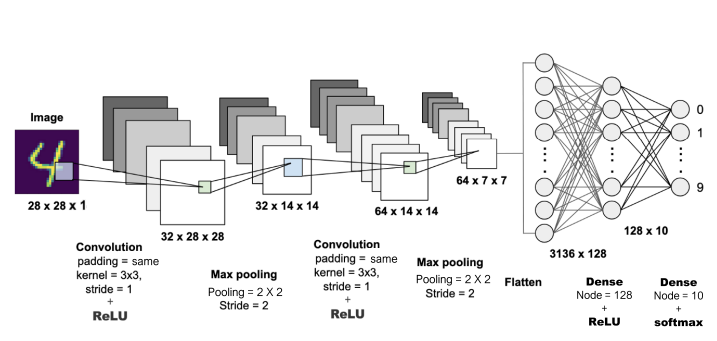
딥러닝 구조 - 기억해야할 단계 4가지
-
- input_shape
: 3차원 데이터 (세로,가로,채널)
: 흑백이면? 채널 = 1 (28,28,1)
: 컬러면? 채널 = 3 (28,28,3)
-> 컬러는 빛의 삼원색 (R, G, B) 로 이루어져 있어 채널이 3개이다.
- input_shape
-
- Conv2d
: 중요한 정보를 위해서, 필터를 학습하는 과정
: 오차를 최소화해주기 위해 필터를 통해 학습하고 찾는 과정이다.
: convolution
: kernel = 필터의 사이즈 (3,3)
: stride : 1
- Conv2d
해당 사진 예시) 322828
: 현재 사진에서는 32배로 데이터가 커졌음을 확인하였다.
- MaxPooling
: 데이터를 압축하는 과정
: 너무 커서
: 중요한 것만 뽑아내기 (덜 중요한건 버리기)
- MaxPooling
- flatten
: 데이터를 1차원으로 압축하기
: 이후 dense layer 및 활성화함수로 연결, 데이터 예측
- flatten
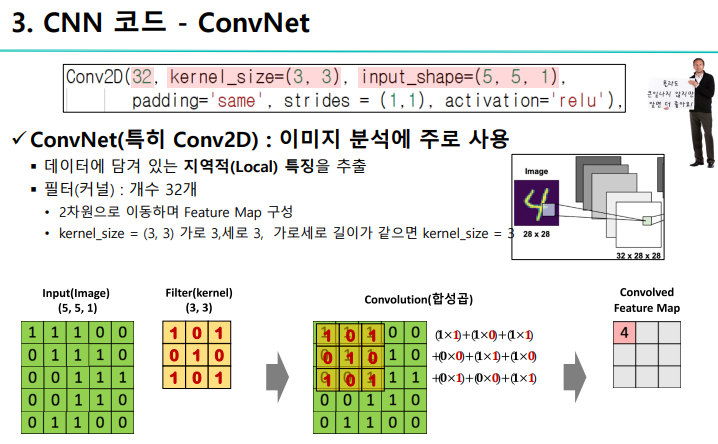
ConvNet 이란?
- 지역적인 특징을 추출하는 것
- 이때 32 = 커널 수 = 필터 수
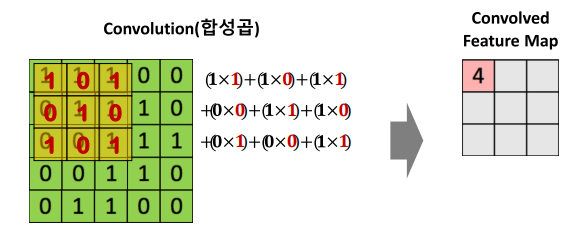
합성곱 연산이란?

- 기존 input 데이터 & 필터(kernal_size) 하나씩 이동하면서 계산을 하는 과정
- convolutional layer
- 55 -> 33 로 변환하였음
- 만약 같은 사이즈로 변환되기를 원한다면?
(ex: 55 -> 55)
: padding = 'same'
Q. 필터 사이즈를 줄이는 이유는? 크기가 방대해서 중요한 정보만 가져가 줄이려고 그러는것인가?
Q. 반대로 padding = 'same' 과 같이 필터 사이즈가 동일한 경우, 왜 사이즈를 줄이지 않는것인가?
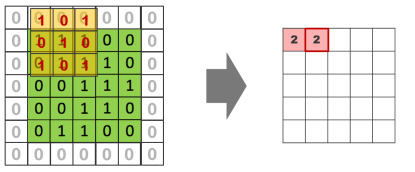
MaxPooling
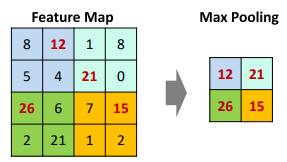
: 중요한 정보만 가져오기 위해서 최대 크기만 출력
(중요하지 않은것은 버린다)
: 특정 데이터를 강조하거나, 중요한 정보만 가져오고 싶을 때 사용한다.
- 오차를 줄이는 방향으로 최적의 가중치를 찾아야한다.
- 필터 안에 있는 값들은 가중치의 값이다.
- 필터 안에 있는 값을 업데이트하면서 학습을 한다
-> 학습을 한다 = CNN 업데이트한다.
flatten
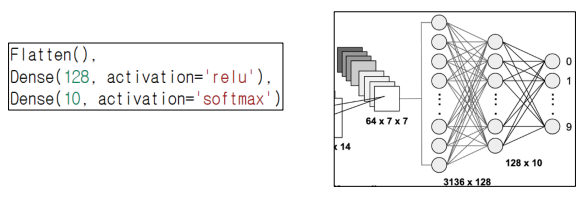
- Dense layer로 연결해야한다.
conv2d & maxpooling 실습
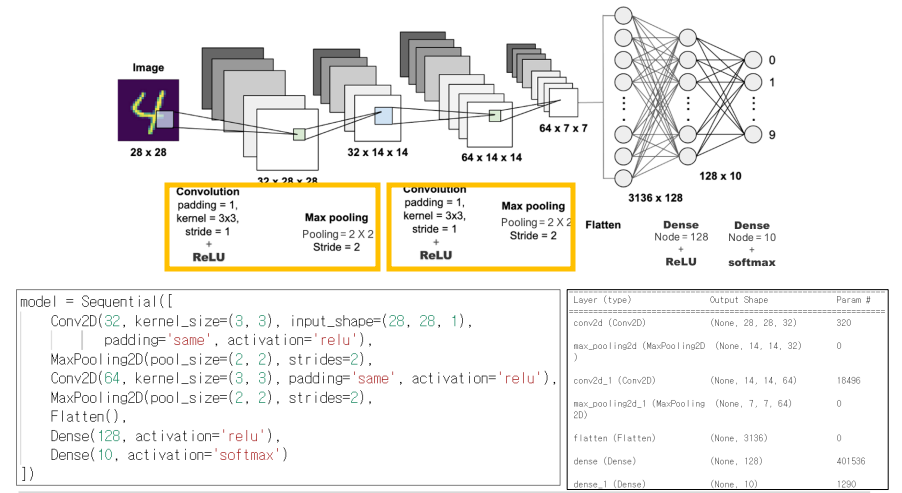
다음과 같은 예시는, conv2d와 maxpooling을 2번 반복하여 학습한 것이다.
실습 결과 확인해보기
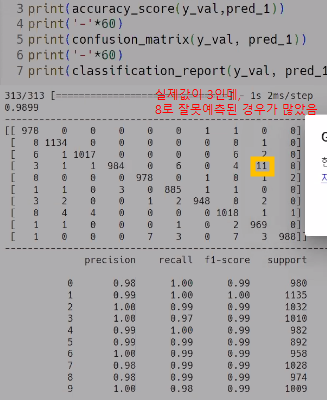
- MNIST 데이터
- 실제값이 3인데 8로 잘못 예측 되었다.
- CNN 역시 earlystopping이나 L1,L2 규제 등 후속 작업이 가능하므로 해당 작업을 진행하여 일반화 성능을 높여야한다.(과적합을 줄여야한다)
참고자료
https://autonomous-vehicle.tistory.com/35
직접 손글씨를 하여 아까 만든 모델로 내가 쓴 글씨 잘 맞추는지 확인해보기
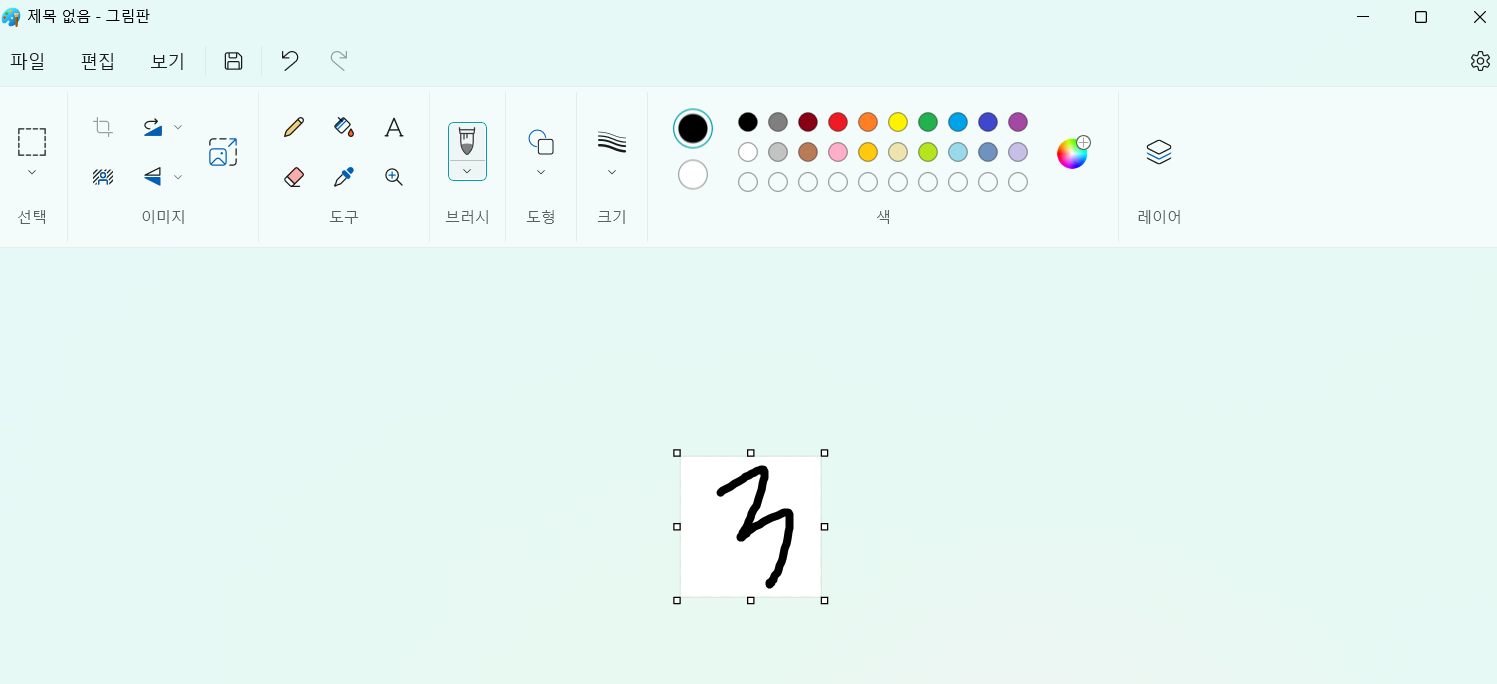
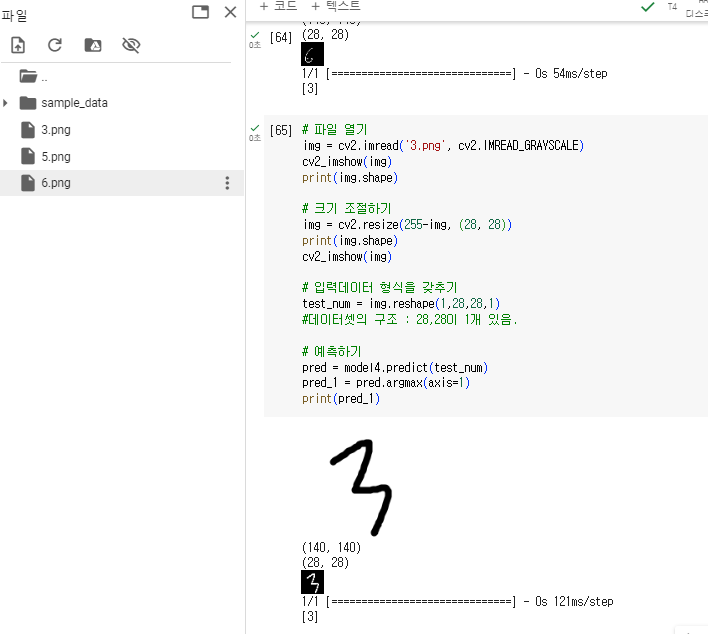
- 그림판에 크기를 28*28로 수정
- 저장한 이후, 코렙에 png 파일 드래그 앤 드롭하여 가져다 놓기
- cv2라이브러리 활용하여 결과 구현
확인사항
내가 아무리 글을 잘 써도, 실제 test 데이터에서는 값을 맞추지 못할 경우
: train 데이터에서만 적합이 잘되고, test 데이터에서 안되었다는 의미
: 과적합 진행되었다는 의미
CNN 진행시 과적합이라면?
: 데이터의 양을 늘린다.
: 모델의 복잡도를 축소하거나 규제한다
3.성능관리
early stopping
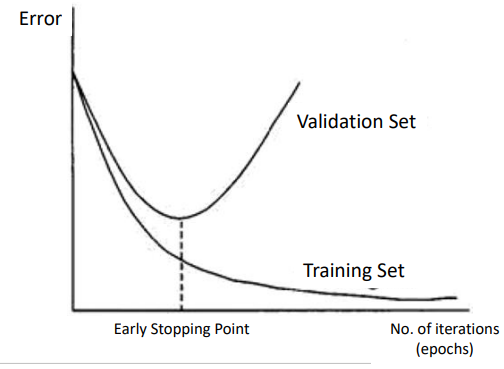
early stopping을 통해 과적합되기 이전 epochs 수를 조정할 수 있다.
반복횟수가 많으면 과적합이 될 수 있기 때문
오차가 더이상 줄어들지 않으면 멈추도록 설정
- min_delta : 0 (줄어든 정도에 대한 기준)
- patience : 0
가중치 규제

가중치가 높다면 다른 값들의 영향력이 줄어들어 과적합이 발생할 수 있다.
오차가 늘어나는 것을 멈출 수 있도록 규제를 하여 가중치의 영향력을 제어한다.
이때
절댓값으로 가중치를 규제하기 : L1
제곱으로 가중치를 규제하기 : L2
공통점
가중치를 줄인다는 점에서 의미 O
차이점
L1규제 : 가중치 작은 값들을 0으로 만든다
L2규제 : 가중치 작은 값들을 0에 수렴하도록 만든다.
Dropout

4.요약
- cnn은 무조건 4차원데이터로 입력이 되어야한다.
- 비선형을 하는 이유는, 층을 깊게 설정하기 위해 진행하며 활성화함수를 hidden layer에 추가한다.
- 다중분류에서 output layer의 노드 수는 클래스의 수이며 활성화 함수는 softmax이다.
- cnn 예시
100100짜리 흑백 이미지를 가지고 모델을 만든다고 가정하면?
: input shape = (100,100,1)
1414짜리 컬러 이미지를 가지고 모델을 만든다고 가정하면?
: input shape = (14,14,3)
