Python Syntax 3 for A.I.
Python Data Structure
primitive type이 아닌, 어떤 특징이 있는 data는 어떻게 저장하면 좋을까?
예를들면) 전화번호부, 은행번호표, 서적정보, 택배 상하차 data 등
Stack
- 스택이란? 나중에 넣은 data를 먼저 반환하도록 설계된 memory 구조
- Last In First Out (LIFO)
- Data의 입력을 Push, 출력을 Pop 이라고 한다.
- 리스트를 이용하여 스택 구조를 구현할 수 있다.
- push를 append(), pop을 pop()를 사용.
a = [1, 2, 3, 4, 5]
a.append(10)
a.append(20)
a.pop()
#20
a.pop()
#10- pop()은 return 값이 존재하면서도, 동시에 리스트를 변화시키기도 한다.
Queue
- 큐 란? 먼저 넣은 data를 먼저 반환하도록 설계된 memory 구조
- First In First Out(FIFO)
- Stack과 반대되는 개념
- 파이썬은 리스트를 활용하여 큐 구조를 활용한다.
- put은 append(), get은 pop(0)을 사용한다.
주로 리스트의 마지막값 또는 첫번째 값을 없애기 위해서는 pop()을 많이 사용한다.
a = [1, 2, 3, 4, 5]
a.append(10)
a.append(20)
a.pop(0)
#1
a.pop(0)
#2Tuple
- 튜플은? 값의 변경이 불가능한 리스트
- 선언 시, []가 아닌 ()를 사용해 튜플을 선언한다.
- 리스트의 연산, 인덱싱, 슬라이싱 등을 동일하게 사용할 수 있다.
- 한 가지 불가능 한 것은 값 자체는 변환이 불가능하다.
- 왜 쓸까?
프로그램을 작동하는 동안 변경되지 않은 data의 저장할 때,
함수의 반환 값 등 사용자의 실수에 의한 에러를 사전에 방지.
t = (1, 2, 3)
print(t + t, t * 2)
#(1, 2, 3, 1, 2, 3) (1, 2, 3, 1, 2, 3)
len(t)
#3
t[1] = 5 # -> Error 발생
t = (1)
#1
t = (1, )
#(1, )- (1)은 일반 정수로 인식한다.
- 값이 하나인 Tuple은 반드시 ","를 붙여주어야 한다.
Set
- Set 자료형은, 값을 순서없이 저장, 중복을 불허하는 자료형이다.
- set() 으로 set 객체를 생성한다.- s.add(1) -> 하나의 원소 추가(중복이면 추가 안됨)
- s.remove(1) -> 원소 중, 1 삭제
- s.update([1, 4, 5, 6, 7]) -> [1, 4, 5, 6, 7] 추가
- s.discard(3) -> 원소 중, 3 삭제
- s.clear() -> 모든 원소 삭제
s1 = set([1, 2, 3, 4, 5])
s2 = set([3, 4, 5, 6, 7])
s1.union(s2)
#{1, 2, 3, 4, 5, 6, 7}
s1 | s2
#{1, 2, 3, 4, 5, 6, 7}
s1.intersection(s2)
#{3, 4, 5}
s1 & s2
#{3, 4, 5}
s1.difference(s2)
#{1, 2}
s1 - s2
#{1, 2}- 수학에서 활용하는 다양한 집합연산이 가능하다.
합집합, 교집합, 차집합 등
dictionary
- 딕셔너리 자료형은 데이터를 저장할 때 구분 지을 수 있는 값을 함께 저장.
예) 주민등록번호, 제품 모델 정보
- 구분을 하기 위한 데이터의 고유 값을 Identifier 또는 Key라고 함.
- Key 값을 활용하여, data 값 (value)를 관리함.
- Key와 Value를 매칭하여 Key로 Value를 검색.
- Dictionary를 Hash Table 이라고도 한다.
- {Key1 : Value1, Key2 : Value2, Key3 : Value3 ...} 형태
country_code = {}
country_code = {"America" : 1, "Korea" : 82, "China" : 86, "Japan" : 81}
country_code.items() #키랑 값 둘 다
#Dict_items([("America", 1), ("China", 86), ("Korea", 82), ("Japan", 81)])
#country_code.keys() #키 값만
#Dict_keys(["America", "China", "Korea", "Japan"])
country_code["German"] = 49 #dict에 추가
country_code.values() # value값들
#dict_values([1, 49, 86, 82, 81])Collections
- Collections란? List, Tuple, Dict 등 에 대한 Python Built-in 확장 자료 구조 모듈.
- 편의성, 실행 효율 등에서 사용자에게 이점이 있다.
- 모듈 예시)
from collections import deque
from collections import Counter
from collections import OrderedDict
from collections import defaultdict
from collections import namedtuple
Deque
- 한마디로 Stack & Queue를 지원하는 모듈
- List에 비해 효율적인, 빠른 자료 저장 방식을 지원함.
- rotate(), reverse(), appendleft(), extendleft() 메서드 등을 지원.
- Linked List의 특성을 지원하고, 기존 list 형태의 함수를 모두 지원.
- deque는 기존 list보다 효율적인 자료구조 제공.
- 효율적 메모리 구조로 처리 속도 향상.
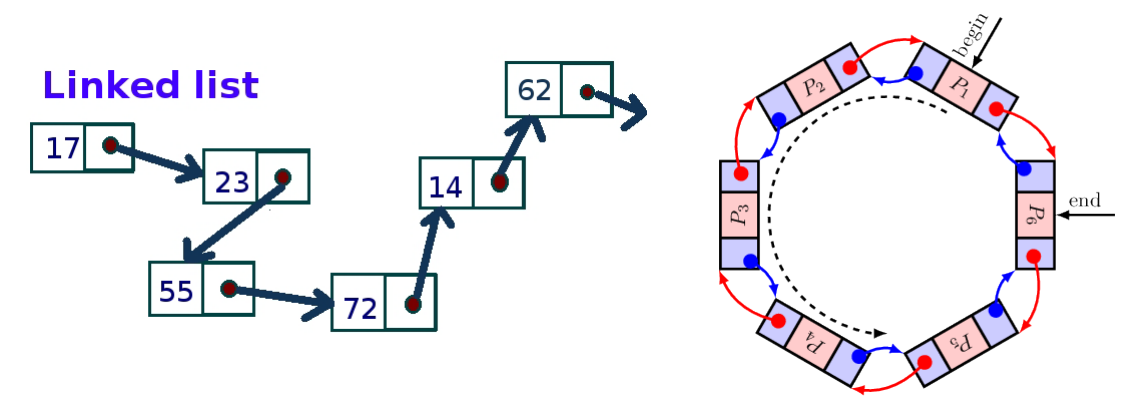
>>> from collections import deque
>>> deque_list = deque()
>>> for i in range(5) :
... deque_list.append(i)
...
>>> deque_list.append(10)
>>> deque_list.appendleft(20)
>>> deque_list
deque([20, 0, 1, 2, 3, 4, 10])
>>> deque_list.rotate(2)
>>> deque_list
deque([4, 10, 20, 0, 1, 2, 3])
>>> deque_list = deque(reversed(deque_list))
>>> deque_list
deque([3, 2, 1, 0, 20, 10, 4])
>>> deque_list.extend([5, 6, 7])
>>> deque_list
deque([3, 2, 1, 0, 20, 10, 4, 5, 6, 7])
>>> deque_list.extendleft([5, 6, 7])
>>> deque_list
deque([7, 6, 5, 3, 2, 1, 0, 20, 10, 4, 5, 6, 7])deque vs general list
from collections import deque
import time
start_time = time.clock()
deque_list = deque()
# Stack
for i in range(10000):
for i in range(10000):
deque_list.append(i)
deque_list.pop()
print(time.clock() - start_time, "seconds")import time
start_time = time.clock()
just_list = []
for i in range(10000):
for i in range(10000):
just_list.append(i)
just_list.pop()
print(time.clock() - start_time, "seconds")OrderedDict
- OrderedDict란, Dict와 달리 데이터를 입력한 순서대로 dict를 반환하는 dict를 말한다.
- 하지만 그냥 dict 또한 python 3.6 version부터 입력한 order를 보장하여 출력한다.- Dict type의 값을, value 또는 key값으로 정렬할 때 사용가능하다.
from collections import OrderedDict
d = OrderedDict()
d['x'] = 100
d['y'] = 200
d['z'] = 300
d['l'] = 500
for k, v in OrderedDict(sorted(d.items(), key = lambda t: t[0])).items() :
print(k, v)
for k, v in OrederedDict(sortedd.items(), key = lambda t: t[1])).items() :
print(k, v)defaultdict
- Dict type의 값에 기본 값을 지정, 신규 값 생성 시 사용하는 방법
- 신규값을 따로 넣지 않아도 되는 dictionary- 기존 dictionary는 key값이 존재하지 않으면, error가 발생한다.
from collections import defaultdict
from collections import OrderedDict
word_count = defaultdict(lambda : 0)
for word in text :
word_count[word] += 1
for i, v in OrderedDict(sorted(word_count.items(), key = lambda t: t[1], reverse = True)).items() :
print(i, v)
- OrderedDict를 활용해서 값을 기준으로 정렬하였음.
Counter
- Counter는 Sequence type의 data element들의 개수를 dict형태로 반환함.
- Dict type, keyword parameter 등 모두 처리 가능.
- Set의 연산을 지원함.
from collections import Counter
c = Counter()
c = Counter('gallahad')
print(c) #Counter({'a' : 3, 'l' : 2, 'g' : 1, 'd' : 1, 'h' : 1})
c = Counter({'red' : 4, 'blue' : 2})
print(list(c.elements())) #['blue', 'blue', 'red', 'red', 'red', 'red']
c = Counter(cats = 4, dogs = 8)
print(list(c.elements())) #['dogs', 'dogs', 'dogs' ,,, 'cats', 'cats', cats']
c = Counter(a = 4, b = 2, c = 0, d = -2)
d = Counter(a = 1, b = 2, c = 3, d = 4)
print(c + d) #Counter({'a' : 5, 'b' : 4, 'c' : 3, 'd' : 2})
print(c & d) #Counter({'b' : 2, 'a' : 1})
print(c | d) #Counter({'a' : 4, 'd' : 4, 'c' : 3, 'b' : 2})- c + d : 더하기, c & d : 교집합, c | d : 합집합
#wordcounter
text = """A press release is the quickest and easiest way to get free publicity. If well written, a press release can result in multiple published articles about your firm and its products. And that can mean new prospects contacting you asking you to sell to them. ….""".lower().split()
print(Counter(text))
#Counter({'a' : 12, 'to' : 10, 'the' : 9, 'and' : 9,,,})
print(Counter(text)["a"])
#12namedtuple
- Tuple 형태의 Data 구조체를 저장하는 방법
- namedtuple은 이름이 있는 tuple 이다, tuple처럼 불변성을 갖고,
인덱스가 아닌 이름으로 각 요소에 접근이 가능하다는 특징이 있다.
(물론, 인덱스로도 요소에 접근할 수 있다.) - 저장되는 data의 variable을 사전에 지정하여 저장한다.
- data를 어떤식으로 저장할 지, 하나로 묶어서 처리할 수 있다.
>>> from collections import namedtuple
>>> Point = namedtuple("Point", ['x', 'y'])
>>> p = Point(11, y = 22)
>>> print(p[0] + p[1])
33
>>> x, y = p
>>> print(x, y)
11 22
>>> print(p.x + p.y)
33
>>> print(Point(x = 11, y = 22))
Point(x=11, y=22)- 'Point' : 생성할 이름 (마치 클래스 이름처럼 사용)
- ['x', 'y'] : 필드명
- p.x 또는 p[0]으로 값에 접근 가능
Pythonic code
-
Python Style coding 기법 (파이썬에서 주로 많이 쓰는)
-
파이썬 특유의 문법을 활용하여 효율적으로 코드를 표현함.
-
그러나 더 이상 파이썬 특유는 아님, 많은 언어들이 서로의 장점을 채용
-
고급 코드를 작성할 수록 더 많이 필요함.
예시)colors = ['red', 'blue', 'green', 'yellow'] result = '' for s in colors : result = result + s colors = ['red', 'blue', 'green', 'yellow'] result = ''.join(colors) result #'redbluegreenyellow'
