Python Syntax 4 for A.I.
Python Syntax 4 for A.I.
Pythonic Code
- 파이썬 스타일의 코딩 기법
- 파이썬 특유의 문법을 활용하여 효율적인 코드로 표현
- 고급 코드를 작성할 수 록 더 많이 필요
- 현재는, 파이썬 특유는 아니고 많은 언어들이 서로의 장점을 채용
Why Pythonic Code?
- 다른 개발자들의 python style code를 이해하기 위해서
(open source library 많이 사용되고 있다.) - 단순 for loop append 보다 list comprehension이 조금 더 빠르다(효율적)
또, 익숙해지면 코드도 더 짧아진다. - 쓰면 왠지 코드를 잘 짜는 것 처럼 보인다.
Split & Join
Split
- string type 자료를 어떻게 자를 것인가?
- Split은 "기준값"으로 나누어 List 형태로 변환해줌.
- packing/unpacking에 활용하기도 함.
>>> items = 'zero one two three'.split() # 빈칸을 기준으로 문자열 나누기
>>> print (items)
['zero', 'one', 'two', 'three']
>>> example = 'python,java,javascript' # ","을 기준으로 문자열 나누기
>>> example.split(",")
['python', ‘java', 'javascript']
>>> a, b, c = example.split(",")
# 리스트에 있는 각 값을 a,b,c 변수로 unpacking
>>> example = ‘teamlab.technology.io'
>>> subdomain, domain, tld = example.split('.')
# "."을 기준으로 문자열 나누기 → UnpackingJoin
- String으로 구성된 list를 합쳐서 하나의 string으로 반환함.
- 문법은 ' ' 안에 연결할 때 더할 표식을 넣어주고 + .join(객체) 로 씀.
>>> colors = ['red', 'blue', 'green', 'yellow']
>>> result = ''.join(colors)
>>> result
'redbluegreenyellow'
>>> result = ' '.join(colors) # 연결 시 빈칸 1칸으로 연결
>>> result
'red blue green yellow'
>>> result = ', '.join(colors) # 연결 시 ", "으로 연결
>>> result
'red, blue, green, yellow'
>>> result = '-'.join(colors) # 연결 시 "-"으로 연결
>>> result
'red-blue-green-yellow'List Comprehension
- 기존 List를 사용하여 간단히 다른 List를 생성하는 기법
- 포괄적인 List, 포함되는 List, 지능형 List 등 의미로 해석됨
- 파이썬에서 가장 많이 사용되는 기법 중 하나(다른 사람의 코드 이해 하는데 필수적)
- 일반적으로 for + append로 List를 생성하는 것 보다 빠름.

#2 nested For loop
>>> word_1 = "Hello"
>>> word_2 = "World"
>>> result = [i+j for i in word_1 for j in word_2]
# Nested For loop
>>> result
['HW', 'Ho', 'Hr', 'Hl', 'Hd', 'eW', 'eo', 'er',
'el', 'ed', 'lW', 'lo', 'lr', 'll', 'ld', 'lW',
'lo', 'lr', 'll', 'ld', 'oW', 'oo', 'or', 'ol', 'od']#3 if not 구문 마지막에 넣음으로써 filter함
>>> case_1 = ["A","B","C"]
>>> case_2 = ["D","E","A"]
>>> result = [i+j for i in case_1 for j in case_2]
>>> result
['AD', 'AE', 'AA', 'BD', 'BE', 'BA', 'CD', 'CE', 'CA']
>>> result = [i+j for i in case_1 for j in case_2 if not(i==j)]
# Filter: i랑 j과 같다면 List에 추가하지 않음
# [i+j if not(i==j) else i for i in case_1 for j in case_2]
>>> result
['AD', 'AE', 'BD', 'BE', 'BA', 'CD', 'CE', 'CA']
>>> result.sort()
>>> result
['AD', 'AE', 'BA', 'BD', 'BE', 'CA', 'CD', 'CE']#4 2d array
>>> words = 'The quick brown fox jumps over
the lazy dog'.split()
# 문장을 빈칸 기준으로 나눠 list로 변환
>>> print (words)
['The', 'quick', 'brown', 'fox', 'jumps',
'over', 'the', 'lazy', 'dog']
>>>
>>> stuff = [[w.upper(), w.lower(), len(w)]
for w in words]
# list의 각 elemente들을 대문자, 소문자, 길이로 변
환하여 two dimensional list로 변환
>>> for i in stuff:
... print (i)
...
['THE', 'the', 3]
['QUICK', 'quick', 5]
['BROWN', 'brown', 5]
['FOX', 'fox', 3]
['JUMPS', 'jumps', 5]
['OVER', 'over', 4]
['THE', 'the', 3]
['LAZY', 'lazy', 4]
['DOG', 'dog', 3]#5 1d vs 2d
>>> case_1 = ["A","B","C"]
>>> case_2 = ["D","E","A"]
['AD', 'AE', 'AA', 'BD', 'BE', 'BA', 'CD', 'CE', 'CA']
>>> result = [i+j for i in case_1 for j in case_2]
>>> result
['AD', 'AE', 'AA', 'BD', 'BE', 'BA', 'CD', 'CE', 'CA']
>>> result = [ [i+j for i in case_1] for j in case_2]
>>> result
[['AD', 'BD', 'CD'], ['AE', 'BE', 'CE'], ['AA', 'BA', 'CA']]- 2d 의 case에서는, j가 먼저 먼저 for loop이 돌고 그 안에 i 가 도는 형태가 됨.
Enumerate & Zip
Enumerate
- enumerate 함수를 사용하면 list의 element를 추출할 때, 번호를 붙여 추출할 수 있다.
>>> for i, v in enumerate(['tic', 'tac', 'toe']):
# list의 있는 index와 값을 unpacking
... print (i, v)
...
0 tic
1 tac
2 toe- dict type에서 데이터를 추출할 때와 같은 방식.
>>> text = 'Artificial intelligence (AI), is intelligence demonstrated by machines, unlike the natural intelligence displayed by humans and animals.'
>>> {i:j for i,j in enumerate(text.split())}
# 문장을 list로 만들고 list의 index와 값을 unpacking하여 dict로 저장
{0: 'Artificial', 1: 'intelligence', 2: '(AI),', 3: 'is', 4: 'intelligence', 5: 'demonstrated', 6: 'by',
7: 'machines,', 8: 'unlike', 9: 'the', 10: 'natural', 11: 'intelligence', 12: 'displayed', 13: 'by', 14:
'humans', 15: 'and', 16: 'animals.'}Zip
- Zip 함수를 이용하여 두 개의 list 값을 병렬적으로 추출할 수 있다.
>>> alist = ['a1', 'a2', 'a3']
>>> blist = ['b1', 'b2', 'b3']
>>> for a, b in zip(alist, blist): # 병렬적으로 값을 추출
... print (a,b)
...
a1 b1
a2 b2
a3 b3example
>>> alist = ['a1', 'a2', 'a3']
>>> blist = ['b1', 'b2', 'b3']
>>>
>>> for i, (a, b) in enumerate(zip(alist, blist)):
... print (i, a, b) # index alist[index] blist[index] 표시
...
0 a1 b1
1 a2 b2
2 a3 b3Lambda & Map & Reduce
- Lambda, map, reduce는 간단한 코드로 다양한 기능을 제공해줄 수 있다.
- 그러나 코드의 직관성이 떨어지기 때문에, lambda나 reduce는 python3에서 사용을 권장하지 않는다.
- 하지만 문제는 여전히 Legacy Library나 다양한 머신러닝 코드에서 사용중이기 때문에 알아놓을 필요가 분명히 있다.
Lambda
- Lamda는 함수 정의 없이, 함수처럼 쓸 수 있는 익명함수를 뜻한다.
- 수학의 람다 대수에서 유래했다.

- Lambda Problems
- 어려운 문법
- 테스트의 어려움
- docstring 지원 미비
- 코드 해석의 어려움
- 이름이 존재하지 않는 함수의 출현 - 그렇지만 아직도 많이 쓴다...
Map
- Map 함수는 Sequence 형 데이터가 있을 때, 함수를 매핑해줄 수 있다.
ex = [1, 2, 3, 4, 5]
f = lambda x: x ** 2
list(map(f, ex))
#[1, 4, 9 , 16, 25]
[f(value) for value in ex]
#[1, 4, 9 , 16, 25]
ex = [1,2,3,4,5]
f = lambda x, y: x + y
print(list(map(f, ex, ex)))
#[2, 4, 6, 8, 10]- python3 는 iteration을 생성하기 때문에, list를 붙여줘야 list 사용가능.
Reduce
- map function과 달리 list에 똑같은 함수를 적용하여 통합해줄 때 사용.
- 대용량의 데이터를 다룰 때, reduce 함수를 많이 사용한다.
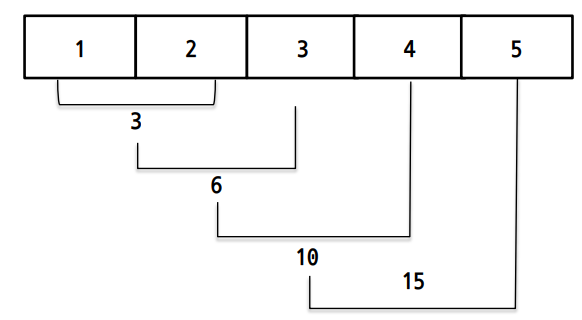
from functools import reduce
print(reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]))
#15Iterable Object
- data를 순서대로 추출할 수 있는 object를 iterable object라고 부른다.
- iterable object는 내부적으로 iter 와 next function이 구현되어 있다.
cities = ['Seoul', 'Busan', 'Jeju']
memory_address_cities = iter(cities)
print(memory_address_cities)
#<list_iterator at 0x160ace724f0>
next(memory_address_cities)
#'Seoul'
next(memory_address_cities)
#'Busan'
next(memory_address_cities)
#'Jeju'Generator
- iterable object의 특수한 형태인 Generator
- element가 사용되는 시점에 메모리의 값을 반환한다, 그 전에는 주소값만 가지고 있다.(마치 iterable 객체에서 next함수로 부르는 것처럼)

def generator_list(value) :
result = []
for i in range(value) :
yield i
for a in generator_list(50) :
print(a)generator comprehension
- list comprehension과 유사한 형태로 genaerator 형태의 list 생성
- generator expression 이라는 이름으로도 부름
- [] 대신 ()를 사용하여 표현
gen_ex = (n*n for n in range(500)) print(type(gen_ex)) <class 'generator'>
from sys import getsizeof
gen_ex = (n*n for n in range(500))
print(getsizeof(gen_ex))
print(getsizeof(list(gen_ex)))
list_ex = [n*n for n in range(500)]
print(getsizeof(list_ex))- 일반적인 iterator는 generator에 반해, 훨씬 큰 메모리 용량을 사용한다.
when generator?
- list type의 데이터를 반환하는 함수는 generator로 만들어라!
- 읽기 쉬운 장점, 중간 과정에서 loop이 중단될 수 있을 때 - 큰 데이터를 처리할 때는 generator expression을 고려하라
- 데이터가 커도 처리의 어려움이 없다.- 딥러닝 모델 데이터 처리 시, 유용할 수 있다.
- 파일 데이터를 처리할 때에도 generator를 사용하라.
Function Passing Arguments
- 함수에 입력되는 arguments는 다양한 형태가 있을 수 있다.
- Keyword arguments
- Default arguments
- Variable-length arguments
Keyword Arguments
- 함수에 입력되는 parameter의 변수명을 사용하여, arguments를 받음.

Default Arguments
- parameter의 기본값을 사용, 입력하지 않을 경우 입력한 기본값을 받음.

Variable-length Arguments
- 함수의 parameter가 정해지지 않았다면, asterisk를 사용하여 가변인자를 받을 수 있다.
- 가변인자란?
- 개수가 정해지지 않은 변수를 함수의 parameter로 사용하는 방법이다.
- Keyword Arguments와 함께, argument 추가 가능
- Asterisk(*)기호를 사용하여 함수의 parameter를 표시함.
- 입력한 값은 tuple type으로 사용할 수 있다.
- 가변인자는 오직 한 개만 맨 마지막 parameter 위치에 사용가능
- 가변인자는 일반적으로, *args 변수명을 사용
- 기존 parameter 이후에 나오는 값을 tuple로 저장함
keyword variable-length(키워드 가변인자)
- parameter의 이름을 따로 지정하지 않고 입력하는 방법
- asterisk(*) 두개를 사용하여 함수의 parameter를 표시함.
- 입력된 값은 dict type으로 사용할 수 있다.
- 가변인자는 오직 한개만 기존 가변인자 다음에 사용한다.
>>> def kwargs_test_3(one, two, *args, **kwargs) :
... print(one + two + sum(args))
... print(kwargs)
...
>>> kwargs_test_3(3, 4, 5, 6, 7, 8, 9, first = 3, second = 4, third = 5)
42
{'first': 3, 'second': 4, 'third': 5}asterisk - unpacking a container
- tuple, dict 등 자료형에 들어가 있는 값을 unpacking 하는 용도로 사용될 수 있다.
- 함수의 입력값, zip등과 같이 유용하게 사용가능
#1
def asterisk_test(a, *args):
print(a, args)
print(type(args))
asterisk_test(1, *(2,3,4,5,6))
1 (2, 3, 4, 5, 6)
<class 'tuple'>#2 * as unpacking
>>> def asterisk_test(a, args):
... print(a, *args)
... print(type(args))
... asterisk_test(1, (2,3,4,5,6))
...
1 2 3 4 5 6
<class 'tuple'>#3 **
>>> def asterisk_test(a, b, c, d,):
... print(a, b, c, d)
... data = {"b":1 , "c":2, "d":3}
... asterisk_test(10, **data)
...
10 1 2 3#4 * with zip
>>> for data in zip(*([1, 2], [3, 4], [5, 6])):
... print(data)
...
(1, 3, 5)
(2, 4, 6)