Conv 실행 시 Pooling과 FC Layer는 무엇일까?
- Pooling Layer란?
- 정의:
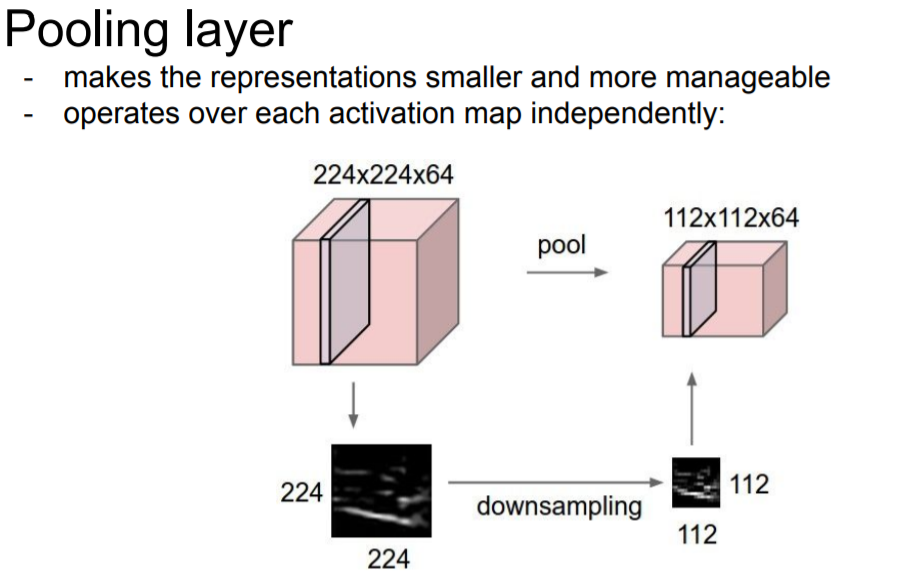
Pooling layer는 Representation(표현, Feature)들을 더 작고 관리하기 쉽게 해주기 위해 downsampling하는 것!
ex> 224x224x64가 입력이 된다면 112x112x64로 줄여줌💡 **왜 Representation을 작게 만드는 것인가?** representation이 작아지면 파라미터수가 줄게 되면 연산량이 줄어들기 때문에 처리 속도를 높일 수 있는 장점이 있다.
Pooling에도 Filter size를 정할 수 있으며 얼마만큼 영역을 한번에 묶을지를 정할 수 있다.
Pooling layer는 Depth에는 영향이 없다??!!
“Depth”에는 아무 짓도 하지 않는다는 것으로 Pooling Layer를 거쳐도 Depth에는 영향을 주지 않는다.
Pooling은 width, height 방향의 공간을 줄이는 연산을 하기 때문에 depth에는 영향을 주지 않는다.Pooling Layer Type
- Max Pooling Layer
대상 영역에서 최댓값을 취하는 연산, 일반적으로 많이 사용
- Average Pooling Layer
대상 영역의 평균을 계산
가장 많이 사용되는 MAX Pooling이 사용되는 방식!
- 방식
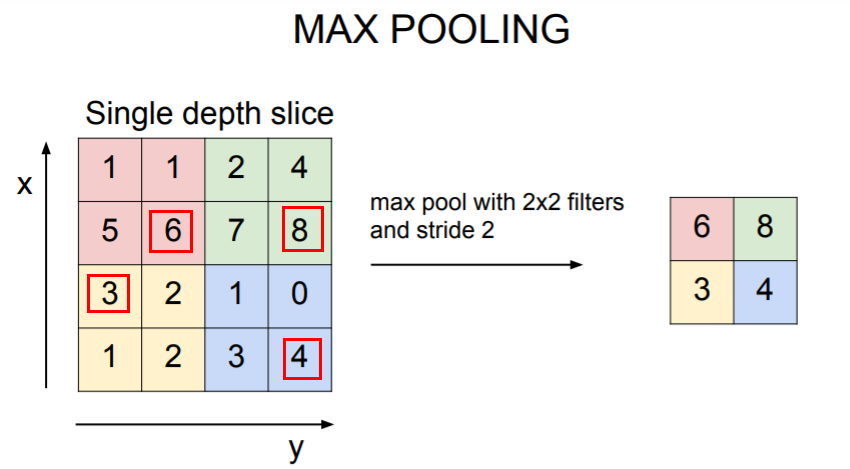
**Filter size = 2x2 / stride=2 로 지정**
Max pooling 또한 Conv Layer가 했던 것처럼 슬라이딩하면서 연산을 수행하며 Filter안에 가장 큰 값 중에 하나를 고르는 방식이다.
빨갠색 영역에서는 6, 초록색 영역에서는 8, 노란색은 3, 파란색에 4가 선택되어 최종적으로 [[6,8],[3,4]]로 DownSample 된것을 볼 수 있다.
질문
- **Q1. Pooling 할 때 겹치지 않게 하는 것이 일반적인가?**
YES! 보통은 겹치지 않는 것이 일반적이다. 기본적으로 Pooling Layer에서는 DownSample을 하는 것이 목적이기 때문에 한 지역을 선택하고 값을 하나로 뽑고, 또 다른 지역 선택하고 값을 하나 뽑는 형식으로 진행한다.
- **Q2. MAX Pooling이 average pooling 보다 많이 사용하는 이유는?**
Conv Layer을 통해 나온 activation map은 얼마나 해당 뉴런이 활성되었는지를 나타내는 값들이다. ( Filter가 각 위치에서 얼마나 활성되었는지)
“인식”에 대해 생각하면 그 값이 어디에 있었다는 것보다 그 값이 얼마나 큰지가 중요하다.
Max pooling은 해당 지역이 어디든 어떤 신호에 대해 “얼마나” 그 filter가 활성화 되었는지를 알려주기 때문에 MAX Pooling을 더 많이 사용한다.
- **Q3. Pooling이나 Conv Layer의 stride나 같은 결과가 나오는 것인지?**
Yes!! 요즘은 Downsample할 때 pooling을 하기보다 stride를 많이 사용하고 있는 추세이다. (교수님 생각: Pooling도 일종의 stride기법이라고 볼 수 있다.)
요즘은 stride가 Pooling보다 더 좋은 성능을 보이기도 하기 때문에 Pooling 대신 Conv Layer의 stride를 사용해도 무방하다.
- 강의에서는 Pooling 적용 시 Overlap 되지 않게 적용하라고 했는데 그 이유가 무엇인가요?
overlap을 하면 조금 더 촘촘히(?) 계산하여 특징을 더 많이 뽑아낼 수 있다.
해당 알고리즘 모델?에 따라 overlap 하기도 한다
Pooling Layer Design Choice

input: W(width),H(Height),D(depth)이면 이를 통해 Filter size를 정해줄 수 있다.
stride까지 정해지면 Conv Layer에 사용했던 수식을 그대로 이용하여 Design Choice를 할 수 있다.
<Conv Layer에 사용했던 수식>
- Pooling Layer의 특징으로는??
pooling layer를 하는 목적이 downsampling 이기 때문에 pooling layer에서는 보통 padding을 하지 않는다.
💡 Padding을 하는 이유로는? 1. downsampling을 막기 위해 : 초반부터 해당 데이터의 크기가 너무 작으면 깊게 학습시킹 데이터가 부족해지는 현상이 생김 , 이는 neural network의 성능에 악영향을 미침! (overfitting을 방지하는 것 중 하나!) 2. Edge pixel data(corner값)를 충분히 활용하기 위해 : corner에 있는 값이 상대값이 상대적으로 적게 사용되기 때문에 padding을 통해 corner, edge에 있는 값을 사용할 수 있도록 해줌 (중요한 정보가 corner에 있으면 모델의 성능이 떨어짐!!)
가장 많이 사용하는 Filter size

filter size로는 2x2, 3x3이고 stride는 2로 하는 것을 많이 사용한다.
(3x3보다 2x2가 조금 더 자주 사용된다.)
- FC Layer (Fully Connected Layer)란? “Fully connected” 완전 연결 되었다는 뜻은 한 층(layer)의 모든 뉴런이 그 다음 층(layer)의 모든 뉴런과 연결된 상태를 말한다. 1차원 배열의 형태로 평탄화된 행렬을 통해 이미지를 분류하는데 사용되는 계층이다.
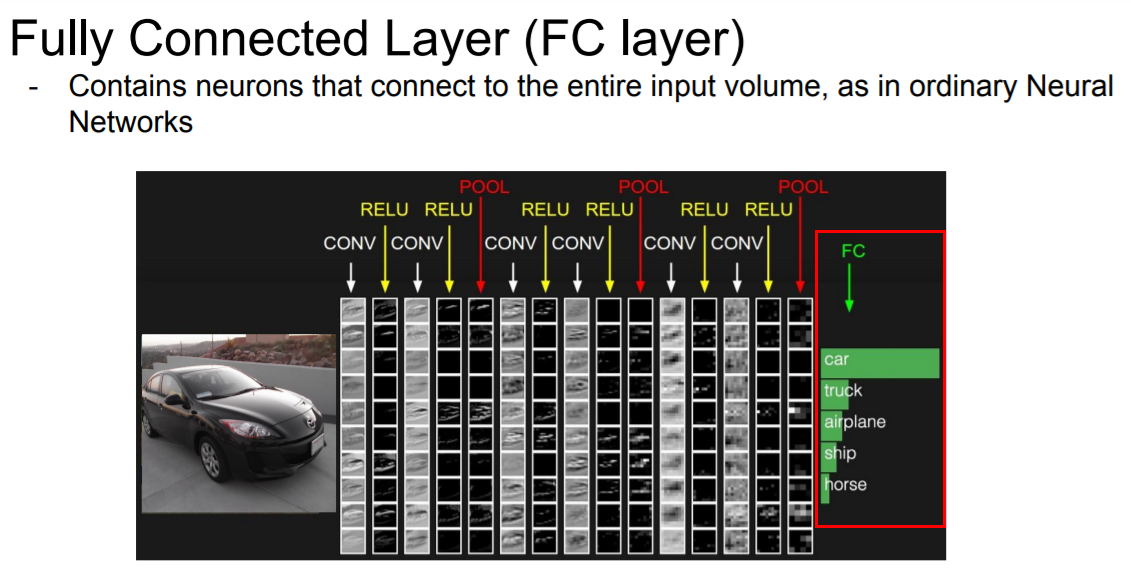
FC Layer 과정
마지막 Conv Layer의 출력은 3차원 volume로 이루어져 있다. 이 값들을 전부 펼쳐(stretch) 1차원 벡터로 만든 후 FC Layer의 입력으로 사용된다. 1차원 벡터로 stretch한 후 softmax함수를 이용하여 최종 score를 산출한다.
1차원 벡터로 만들면 ConvNet의 모든 출력(각 층의 노드)을 서로 연결하게 된다.
FC Layer는 Conv layer와 Pooling layer로 부터 나온 결과를 최종 score값으로 산출하는데 사용하기 때문에 공간적 구조(spatial structure)를 신경쓰지 않아도 된다.질문
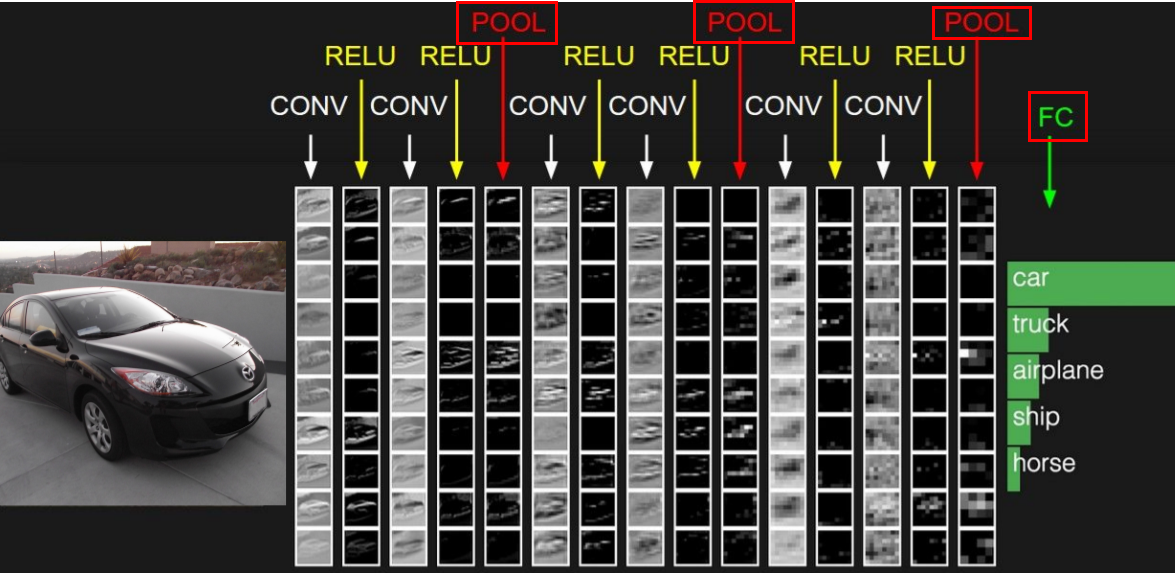
- **열(col)들은 각 어떻게 해석하는가? (= 위의 이미지 사진 해석 관련 질문)**
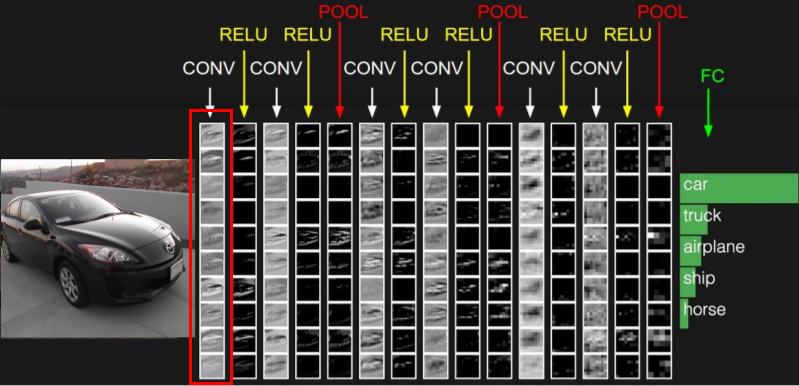
위의 이미지에 보이는 것들은 출력 Activation map이다. 각 출력들은 하나의 Layer의 결과 값을 의미한다.
- **(위 이미지)결과만 보면 정보 자체는 엄청 적을 것 같은데 저 정보만 가지고 어떻게 분류를 할 수 있는가?**
.png)
오른쪽 맨 끝에 있는 Pooling Layer의 출력 값은 전체 네트워크를 통과한 집약체라고 할 수 있다. 즉, Conv → Relu→ Pooling 단계로 가는 계층구조의 취상위라고 할 수 있다. 실제로는 higher level concept을 표현한 것이다.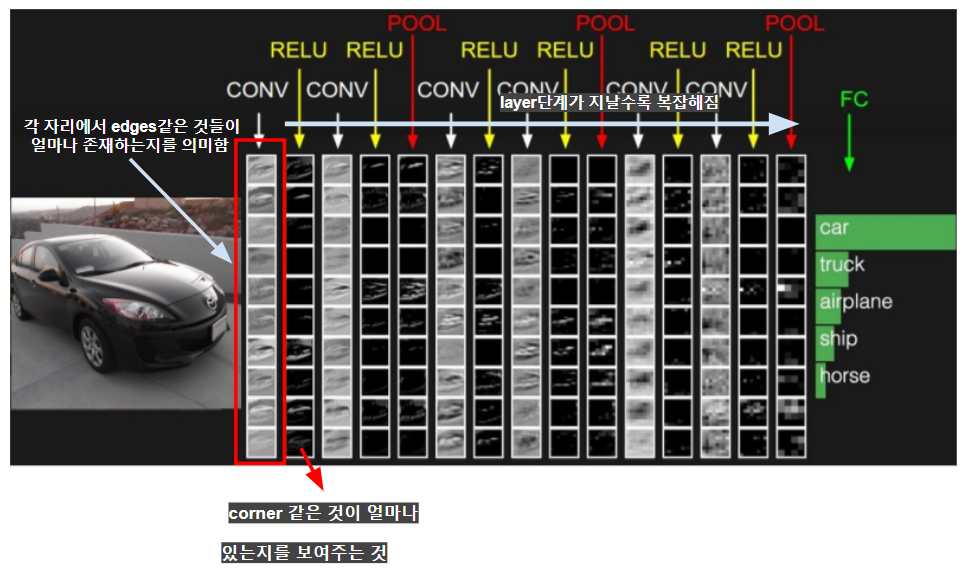
첫번째 열(col)의 map들이 의미하는 것은 각 자리에서 edges같은 것들이 얼마나 존재하는지를 의미한다. layer단계가 지날수록 복잡해진다. 두번째 레이어에서는 corner 같은 것이 얼마나 있는지를 보여준다.
또한 ,각 Conv의 입력이 원본 이미지가 아닌 이전 layer에서 나온 edge maps과 같은 것들이다. 이런 edge map을 가지고 더 복잡한 것들을 추론을 하는 것이다.
그리고 이런 정보를 가지고 FC Layer를 거치게 되며 class score를 계산한다.
classification문제를 풀 때 Pooling 은 얼마나 해야 하는가?
여러번 시도해봐야 한다. Pooling을 너무 많이하면 값이 너무 작아질 것이고 전체 이미지를 잘 표현하지 못하게 되는 것을 주의해며 설정하는 것이 좋다.
다양한 pooling size, filter size, 레이어 수 등을 시도해보는 등 Crossvalidation을 해야한다.
어떤 하이퍼파라미터가 좋은지는 어떤 문제이냐에 따라 달라진다.
Demo
CS231N강의를 만든 Andre Kapathy의 작품
CIFAR-10을 학습(class 10개), 실제로 Filter가 어떻게 생겼고 Activation Map이 어떻게 생겼는지를 볼 수 있음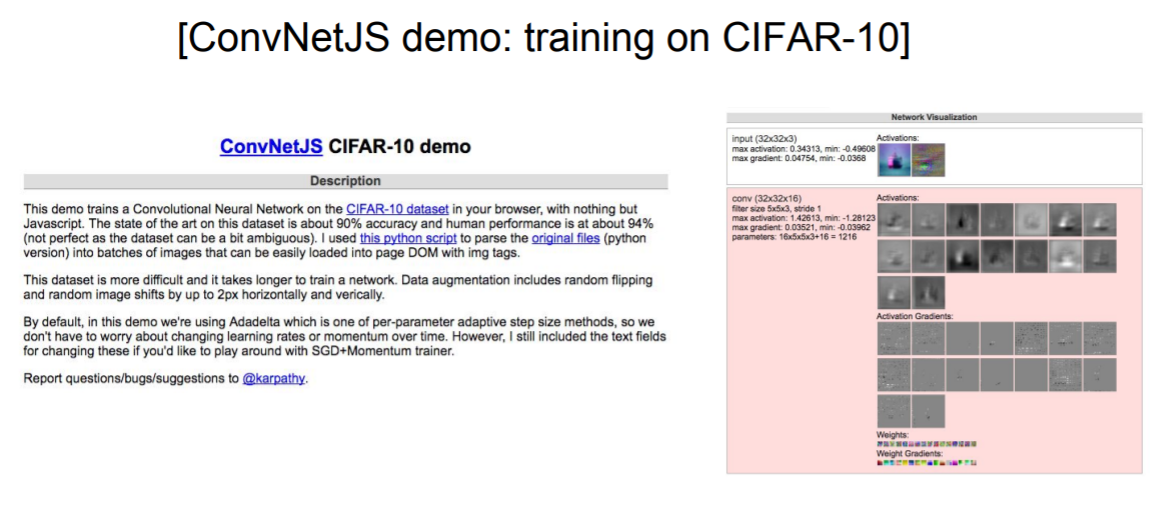
참고
누구나 이해할 수 있는 딥러닝 - cs231n 5강 (Convolutional Neural Networks, CNN)
호다닥 공부해보는 CNN(Convolutional Neural Networks)
CNN 기초 - Convolution, Pooling, Fully-connected Layer
