PointAD: Comprehending 3D Anomalies from Points and Pixels for Zero-shot 3D Anomaly Detection
3D 이상 탐지는 공간적 특징을 활용하여 이상을 탐지하는데 유용하지만, 기존 방법론들은 훈련 데이터가 필요하다는 제약이 있었음.
특히, zero-shot 3D 이상 탐지는 이전에 탐구되지 않았던 분야이므로 PointAD는 이러한 한계를 극복하고자 한 논문임.
Introduction
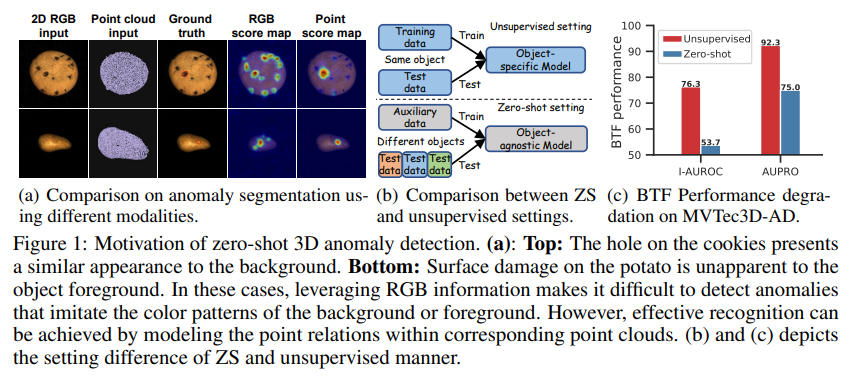
- 현실적 필요성
-
기존의 2D 이상 탐지 방법론은 RGB 정보에 의존하며, 이는 배경과 이상이 유사한 경우에 탐지하기 어렵다는 한계가 있음.
예를 들어, 배경과 비슷한 색상이나 텍스처를 가진 이상은 2D 정보만으로는 탐지하기 어려움. -
3D 이상 탐지는 공간적 관계를 이용하여 결함을 탐지할 수 있는 장점이 있지만, 기존 방법들은 정상 데이터에 의존하여 이상 탐지를 수행하는 방식으로, 훈련 데이터에 대한 접근이 제한되는 경우(개인정보 보호, 제품 출시 전 테스트 등)에는 적용하기가 어려움.
- 제로샷 탐지의 중요성
-
제로샷 3D 이상 탐지는 훈련 데이터 없이 새로운 물체에 대한 이상 탐지를 수행해야 하므로, 모델의 강력한 일반화 성능을 요구함.
-
Vision-Language Model(VLM), 특히 CLIP은 2D 이미지에서 뛰어난 제로샷 탐지 성능을 보였으며, 이를 3D 영역으로 확장하는 연구가 필요함.
- PointAD
-
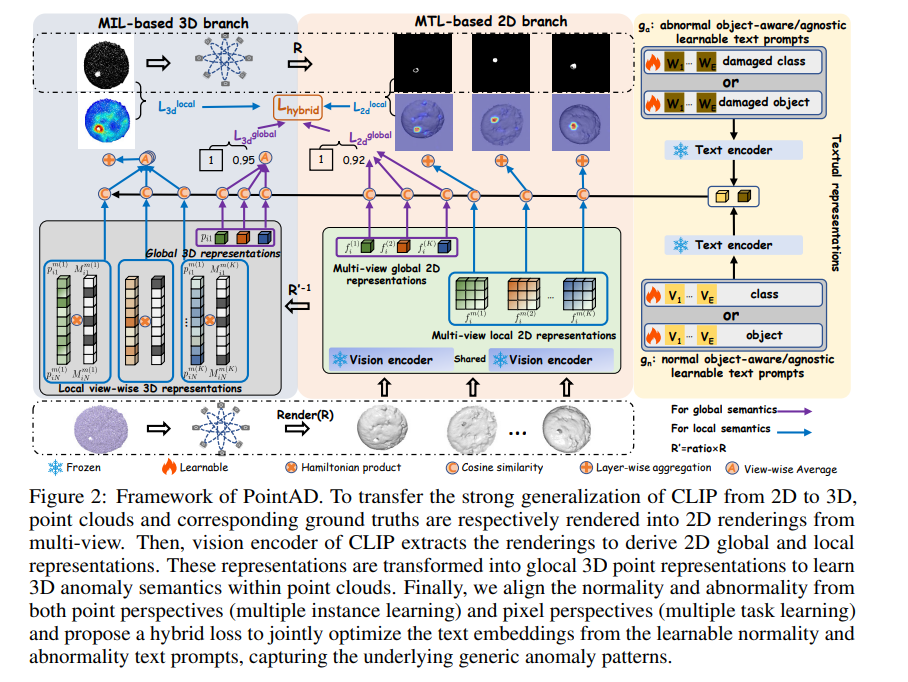
PointAD 프레임워크는 CLIP의 강력한 일반화 성능을 3D 영역으로 확장함.
-
PointAD는 포인트 클라우드와 렌더링된 2D 이미지를 모두 활용하여 이상 탐지를 수행하며, 이를 통해 2D와 3D의 통합을 가능하게 함.
-
PointAD는 하이브리드 표현 학습을 통해 이상 패턴을 학습하고, 텍스트 기반 프롬프트를 최적화하여 제로샷 환경에서 뛰어난 성능을 달성해냄.
Related work
- 3D 이상 탐지
기존의 3D 이상 탐지 방법론은 주로 포인트 클라우드의 정상 특징을 저장한 후, 테스트 데이터와 비교하여 이상을 탐지하는 방식으로 설계됨.
- MVTec3D-AD, Eyecandies, Real3D-AD와 같은 데이터셋을 활용하여 포인트 클라우드와 RGB 정보를 결합한 방법들
- BTF, M3DM, CPFM, SDM과 같은 방법론들은 RGB 및 포인트 클라우드 데이터를 결합하여 이상 탐지를 수행하지만, 이들은 특정 데이터셋에 대한 의존성이 강해 새로운 데이터에 대한 일반화가 어렵다는 단점이 존재함.
-
3D 특징 추출
기존의 3D 특징 추출 기법은 PointNet이나 PointNet++ 와 같은 포인트 기반 네트워크를 사용하거나, 3D 데이터를 2D 형식으로 변환하여 특징을 추출함.
예를 들어, PointCLIP은 포인트 클라우드를 이미지 평면에 투영하여, 효율적으로 특징을 추출하는 방법을 제안했음. 그러나 기하학적 정보를 일부 손실한다는 한계가 존재함.
PointAD는 multi-view 렌더링을 통해 포인트 클라우드의 2D 렌더링 이미지를 생성하고,이를 통해 기하학적 정보를 보존하며 특징을 추출함. -
프롬프트 학습
프롬프트 학습은 네트워크 전체를 재학습하는게 아니라, 학습 가능한 텍스트 프롬프트를 최적화 하는 방식임
- CoOp은 전역 컨텍스트 최적화를 통해 프롬프트를 업데이트하고, DenseCLIP은 밀집 예측 작업에 이를 확장한 사례임.
- 최근에는 AnomalyCLIP이 이상 탐지를 위해 객체 비의존 프롬프트 학습 방식을 도입했음.
- PointAD는 2D 및 3D 관점에서 하이브리드 표현 학습을 통해 제로샷 환경에서도 이상 패턴을 효과적으로 학습할 수 있도록 설계함.
PointAD Method
Experiments
Conclusion
