A Performance-Driven Benchmark for Feature Selection in Tabular Deep Learning
연구 배경
- 머신러닝에서 테이블 데이터는 과학 및 산업 분야에서 매우 흔히 사용됨.
- 일반적으로 데이터 과학자들은 가능한 모든 특성(features) 을 포함하고, 기존 특성에서 새로운 특성을 엔지니어링하여 데이터셋을 구성함.
- 하지만 너무 많은 특성을 포함하면 모델이 과적합(overfitting) 될 위험이 큼.
- 따라서 유용한 특성만을 선택하는 방법(feature selection) 이 필요함.
기존 연구 한계점
기존의 테이블 데이터 특성 선택 벤치마크는 다음과 같은 문제점이 있음:
- 대부분 전통적인 머신러닝 모델(예: 랜덤 포레스트, XGBoost)만을 평가 대상으로 삼음.
- 단순한 합성 데이터 또는 랜덤 노이즈를 추가한 데이터만을 사용하여 현실적인 문제와 괴리가 있음.
- 선택된 특성이 실제 딥러닝 모델의 성능에 미치는 영향을 충분히 평가하지 않음.
기여점
이 연구에서는 테이블 데이터를 처리하는 딥러닝 모델(특히 Transformer 기반 모델)에 대한 새로운 특성 선택 벤치마크를 만들고, 여러 특성 선택 기법을 비교함.
연구의 주요 기여는 다음과 같음:
- 실제(real-world) 데이터셋을 기반으로, 다양한 불필요한 특성(extraneous features)이 포함된 데이터셋을 구성하여 특성 선택 방법을 평가함.
- 기존 방법들뿐만 아니라, 딥러닝 모델에서 특성 선택을 수행하는 새로운 방법(Deep Lasso) 을 제안함.
- 여러 특성 선택 기법을 비교하고, 특히 딥러닝 모델(MLP, Transformer) 이 전통적인 모델(XGBoost 등)에 비해 노이즈에 얼마나 민감한지 분석함.
딥러닝 기반 Tabular 모델은 GBDT(Gradient Boosted Decision Trees)보다 노이즈에 더 취약한가?
기존 연구에서 딥러닝 모델(MLP, Transformer 등)은 테이블 데이터에 적합한가? 라는 질문이 꾸준히 제기됨.
특히, 딥러닝 모델이 노이즈가 많은 데이터에서 Gradient Boosted Decision Trees (GBDT)보다 더 취약한가? 에 대한 검증이 필요함.
최근 연구에 따르면, 작은 규모의 데이터셋(10,000개 샘플 이하) 에서 딥러닝 모델(MLP, Transformer 등)은 GBDT보다 노이즈에 취약하다고 보고됨.
이 논문에서는 더 큰 데이터셋을 사용하여 이 가설을 검증하고, 실험적으로 특성 선택(feature selection)의 필요성을 강조하려 함.
비교모델
-
Multi-Layer Perceptron (MLP)
- 전형적인 다층 퍼셉트론 기반 딥러닝 모델.
- 테이블 데이터를 처리하는데 사용됨.
-
FT-Transformer (Feature Tokenizer Transformer)
- 테이블 데이터를 처리하도록 설계된 Transformer 기반 딥러닝 모델.
- 어텐션(attention) 메커니즘을 통해 주요 특성을 학습하는 것이 특징.
-
GBDT (XGBoost)
- 결정 트리(Decision Tree)를 기반으로 한 부스팅(boosting) 모델.
- 테이블 데이터에서는 일반적으로 딥러닝보다 성능이 우수하다고 알려져 있음.
실험 방법
-
원본 데이터에 랜덤 노이즈 특성(random noise features) 을 추가하여, 모델들이 불필요한 특성을 얼마나 잘 무시하는지 평가함.
-
MLP, FT-Transformer, XGBoost 모델을 학습시키고, 특성 중 노이즈 비율을 조절하면서 성능을 비교함.
-
성능 평가는 다음과 같이 진행됨:
분류(Classification): 정확도(Accuracy)
회귀(Regression): RMSE (Root Mean Squared Error, 낮을수록 좋음)
실험 결과
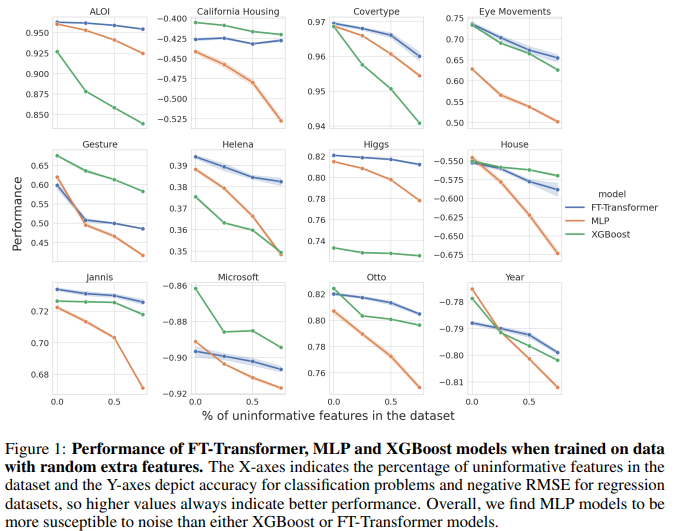
노이즈 비율에 따른 성능 변화
논문에서 제시한 Figure 1(실험 결과 그래프)을 요약하면:
- X축: 노이즈 특성이 전체 데이터에서 차지하는 비율.
- Y축: 모델의 성능 (분류: 정확도, 회귀: -RMSE)
- 결과 요약:
MLP 모델: 노이즈가 증가할수록 성능이 가장 빠르게 저하됨 (노이즈에 매우 취약).
GBDT (XGBoost): 노이즈가 증가해도 상대적으로 안정적인 성능을 유지함.
FT-Transformer: MLP보다는 덜 민감하지만, GBDT보다는 더 취약함.
-
MLP 모델은 노이즈에 매우 취약
- 랜덤 노이즈 특성이 많아질수록 모델 성능이 급격히 감소.
- 이는 MLP가 노이즈를 쉽게 학습(overfitting)하는 경향이 있음을 시사함.
-
GBDT (XGBoost)는 가장 안정적
- 랜덤 노이즈가 많아져도 성능이 크게 변하지 않음.
- 이는 GBDT가 특성을 선택하는 과정에서 불필요한 특성을 효과적으로 무시하기 때문.
-
FT-Transformer는 비교적 강건하지만 완벽하지 않음
- Transformer 모델이 MLP보다는 강건한 성능을 보임.
- Transformer의 어텐션(attention) 메커니즘이 불필요한 특성을 걸러내는 역할을 수행하는 것으로 보임.
- 하지만 GBDT만큼 강건하지는 않음.
특성 선택(Feature Selection) 벤치마크 구축
- 기존 연구들은 랜덤 노이즈를 추가하는 단순한 방식으로 특성 선택(feature selection) 기법을 평가함.
- 하지만 실제(real-world) 데이터에서는 불필요한 특성이 단순한 노이즈가 아니라, 기존 특성을 변형한 형태로 존재하는 경우가 많음.
- 따라서, 이 연구에서는 더 현실적인 특성 선택 문제를 해결할 수 있는 새로운 벤치마크를 구축함.
이 연구에서는 기존 연구와 차별화하여, 단순한 랜덤 노이즈가 아니라 더 현실적인 방법으로 불필요한 특성을 추가함.
-
랜덤 노이즈 특성(Random Features)
기존 연구들과 동일하게, 가우시안 노이즈(Gaussian Noise)를 추가하여 모델이 불필요한 특성을 얼마나 잘 제거하는지 평가.
가장 기본적인 특성 선택 평가 방법. -
손상된 특성(Corrupted Features)
기존 특성 중 일부를 복사한 후, 랜덤 노이즈를 추가하여 변형한 특성을 만듦.
예: 원본 특성이 X라고 하면, X + 노이즈 형태의 특성을 추가.
실제 데이터에서 흔히 발생하는 문제(센서 오류, 데이터 전처리 오류 등)를 반영함. -
2차 특성(Second-Order Features)
기존 특성들 간의 곱(product) 을 새로운 특성으로 추가함.
예: X1, X2 → X1 * X2 형태의 새로운 특성을 생성.
이 방식은 데이터 과학자들이 직접 새로운 특성을 만들 때 흔히 사용하는 기법(feature engineering) 을 모사함.
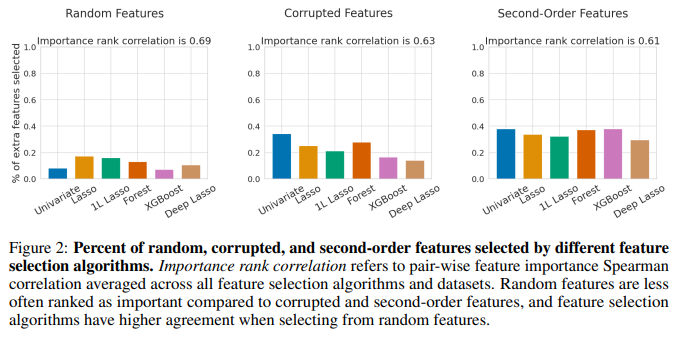
- 각 특성 선택 알고리즘이 불필요한 특성을 얼마나 잘 제거하는지 평가함.
- 실험 결과, 완전히 랜덤한 노이즈는 대부분의 알고리즘이 쉽게 제거 가능하지만, 손상된 특성(Corrupted Features)과 2차 특성(Second-Order Features)은 제거하기가 훨씬 어려움.
실험 결과
-
랜덤 노이즈 특성이 포함된 경우
XGBoost와 Random Forest가 가장 좋은 성능을 보임.
랜덤 노이즈는 대부분의 알고리즘이 효과적으로 제거 가능함. -
손상된 특성이 포함된 경우
XGBoost와 Deep Lasso가 우수한 성능을 보임.
전통적인 Lasso 기반 방법들은 손상된 특성을 잘 걸러내지 못함. -
2차 특성이 포함된 경우
Deep Lasso가 가장 우수한 성능을 보임.
기존 방법들은 2차 특성을 걸러내지 못하고, 오히려 원본보다 더 높은 중요도를 부여하는 경향이 있음.
이는 기존 특성 선택 기법들이 비선형 관계를 반영하지 못하는 한계 때문임.
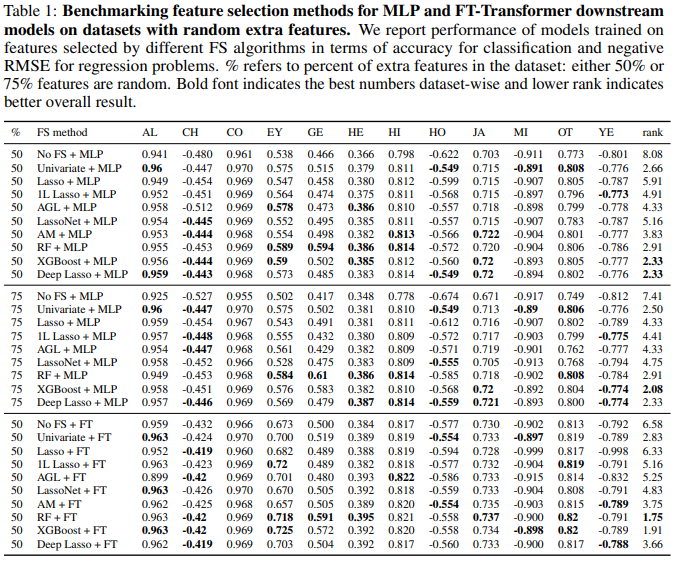
요약
- 기존 특성 선택 방법들은 단순한 랜덤 노이즈 제거에는 효과적이지만, 복잡한 문제(손상된 특성, 2차 특성)에서는 한계를 보임.
- Deep Lasso는 딥러닝 모델에서 가장 강력한 특성 선택 방법으로 확인됨.
- 결과적으로, 테이블 데이터를 위한 딥러닝 모델을 사용할 때 특성 선택은 필수적이며, Deep Lasso가 가장 효과적인 방법임.
Discussion
이 연구는 딥러닝 기반 테이블 모델에서 특성 선택(feature selection)이 얼마나 중요한지를 실험적으로 분석하고, 기존 방법들의 한계를 극복하는 새로운 기법(Deep Lasso)을 제안했다. 연구의 핵심 기여는 다음과 같다:
-
현실적인 특성 선택 벤치마크 구축
- 기존 연구와 달리, 실제(real-world) 데이터셋을 기반으로 다양한 불필요한 특성(랜덤 노이즈, 손상된 특성, 2차 특성 등)이 포함된 벤치마크를 구축.
- 이를 통해 기존 방법들이 단순한 노이즈는 잘 처리하지만, 더 복잡한 특성 선택 문제에서는 성능이 저하됨을 보임.
-
딥러닝 모델에서 특성 선택의 중요성 검증
- 딥러닝 모델(MLP, FT-Transformer)은 GBDT(XGBoost)보다 노이즈에 취약함을 확인.
- 특히 손상된 특성과 2차 특성이 포함된 데이터에서는 기존 특성 선택 기법이 효과적이지 않음.
-
새로운 특성 선택 기법(Deep Lasso) 제안
- Deep Lasso는 입력 특성의 기울기(gradient)를 기반으로 특성을 선택하는 새로운 기법.
- 실험 결과, 특히 2차 특성이 포함된 어려운 문제에서 기존 방법보다 훨씬 우수한 성능을 보임.
실험 결과 분석
- 기존 특성 선택 방법의 한계
-
Lasso 기반 방법(Lasso, Adaptive Group Lasso, LassoNet 등)
- 기존 선형 모델에서는 효과적이지만, 딥러닝 모델에서는 충분히 효과적이지 않음.
- 특히 손상된 특성(Corrupted Features)과 2차 특성(Second-Order Features)을 효과적으로 제거하지 못함. -
트리 기반 방법(Random Forest, XGBoost)
- 랜덤 노이즈가 포함된 데이터에서는 강력한 성능을 보임.
- 하지만 손상된 특성과 2차 특성에는 여전히 한계가 있음.
- 딥러닝 기반 방법의 강점과 약점
-
FT-Transformer의 Attention Map 기반 방법(AM)
- 랜덤 노이즈를 걸러내는 데는 효과적이지만, 손상된 특성과 2차 특성에 대해서는 한계를 보임.
- Transformer의 어텐션(attention) 메커니즘이 일부 특성 선택 역할을 하지만 완벽하지 않음. -
Deep Lasso의 뛰어난 성능
- 모든 실험에서 안정적인 성능을 보였으며, 특히 2차 특성이 포함된 환경에서 가장 좋은 성능을 기록.
- 기존 특성 선택 기법들이 비선형 관계를 제대로 반영하지 못하는 문제를 해결함.
특성 선택 알고리즘 간 유사성 분석
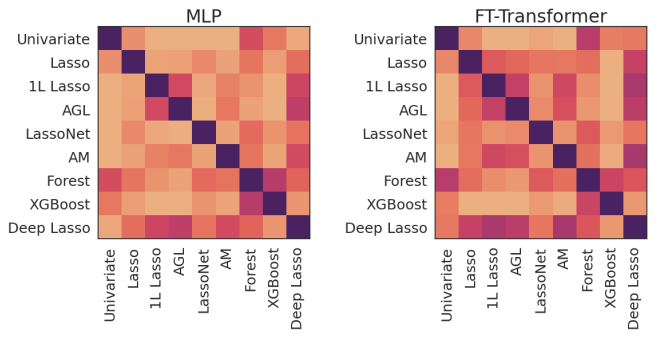
각 특성 선택 방법이 어떤 방식으로 특성을 선택하는지 비교하기 위해 상관관계 분석을 수행했다.
-
Random Forest와 XGBoost는 매우 유사한 특성을 선택
- 두 방법 모두 트리 기반 알고리즘으로, 선택하는 특성의 패턴이 유사함.
-
Lasso 기반 방법들(Lasso, 1L Lasso, Adaptive Group Lasso)은 서로 높은 상관관계를 보임
- 하지만 트리 기반 방법과는 다른 특성을 선택하는 경향이 있음.
-
Deep Lasso는 기존 Lasso 기반 방법과 비슷한 특성을 선택하지만, 성능이 훨씬 우수함
- 기존 Lasso 방법보다 비선형 관계를 더 효과적으로 반영하여, 2차 특성을 포함한 데이터에서도 높은 성능을 유지함.
