Abstract
본 논문은 시계열 예측에 대한 새로운 접근 방식인 PromptCast를 소개합니다. 기존의 시계열 예측 모델은 수치 데이터를 입력으로 받아 수치 데이터를 출력하지만, PromptCast는 입력과 출력을 자연어 프롬프트로 변환하여 언어 모델을 활용해 예측합니다. 이를 위해 세 가지 실제 예측 시나리오를 포함한 대규모 데이터셋(PISA)을 제공합니다. 다양한 최신 수치 기반 예측 방법과 언어 생성 모델을 평가한 결과, PromptCast는 제로샷 설정에서 특히 뛰어난 일반화 능력을 보여줍니다. PromptCast는 시계열 예측에서 유망한 연구 방향임을 시사합니다.
Introduction
시계열 예측은 LSTM(Long Short-Term Memory), TCN(Temporal Convolutional Network), 트랜스포머(Transformer)와 같은 다양한 딥러닝 프레임워크를 적용하여 활발히 연구되고 있습니다. 최근 자연어 처리(NLP) 분야에서는 BERT, CLIP, GLIP와 같은 대규모 사전 학습 모델이 빠르게 발전하여 다양한 하위 작업에서 우수한 성능을 발휘하고 있습니다. 그러나 이러한 진보는 주로 NLP와 컴퓨터 비전(CV) 분야에 국한되어 있으며, 시계열 예측에는 잘 적용되지 않고 있습니다.
이에 따라, 본 논문은 이러한 대규모 사전 학습된 기초 모델을 시계열 예측에 활용할 수 있는지에 대한 연구 질문을 제기하고, 새로운 시계열 예측 작업인 PromptCast를 소개합니다. PromptCast는 수치 입력과 출력을 자연어 프롬프트로 변환하여, 예측 작업을 문장 대 문장 형태로 구성합니다. 이를 통해 언어 생성 모델을 예측 모델로 직접 활용할 수 있습니다.
PromptCast의 도입은 여러 가지 이점을 제공합니다. 우선, 복잡한 딥러닝 모델을 설계하는 대신 코드 없이도 쉽게 시계열 예측을 수행할 수 있는 새로운 관점을 제공합니다. 또한, 비전문가 사용자에게도 접근하기 쉬운 방법을 제시하여, 새로운 예측 시나리오에서도 간편하게 사용할 수 있습니다. 예를 들어, 예측 기능을 갖춘 챗봇을 통해 특정 시계열 예측 질문에 답변할 수 있는 응용 프로그램이 가능해질 것입니다.
이 연구는 시계열 예측 문제를 언어 기반 관점에서 접근하는 첫 번째 시도입니다. 이를 위해, 세 가지 실제 예측 시나리오(날씨 예측, 에너지 소비 예측, 고객 유입 예측)를 포함하는 대규모 데이터셋인 PISA를 새롭게 구성했습니다. PISA 데이터셋은 다양한 시계열 예측 시나리오를 포함하고 있어, PromptCast 연구를 지원하고 관련 연구를 촉진할 잠재력을 가지고 있습니다.
PromptCast는 다양한 최신 수치 기반 예측 모델과 언어 생성 모델을 평가하여, 제로샷 설정에서도 뛰어난 일반화 능력을 보여주었습니다. 이는 PromptCast가 새로운 예측 시나리오에서 빠르게 적용될 수 있음을 시사합니다. 더 나아가, PromptCast는 기후 변화를 예측하거나 고객 트래픽을 예측하는 등 더 복잡한 예측 시나리오에서도 활용될 수 있는 잠재력을 가지고 있습니다.
결론적으로, PromptCast는 시계열 예측에 새로운 접근 방식을 제시하며, 사전 학습된 언어 모델의 강력한 성능을 시계열 예측에 활용하여 예측 정확도와 일반화 능력을 크게 향상시킬 수 있음을 보여줍니다. 이러한 접근 방식은 다양한 실제 응용 분야에서 유용할 수 있으며, 특히 데이터가 부족한 초기 상황에서도 높은 성능을 발휘할 수 있는 잠재력을 가지고 있습니다.
이러한 관점에서 이 논문은 3가지 기여점을 갖습니다.
-
새로운 예측 패러다임 제안:
본 논문은 시계열 예측 문제를 자연어 생성 방식으로 해결하는 새로운 패러다임인 PromptCast를 제안합니다. 이는 기존의 수치 기반 예측 방법과는 다른 접근 방식으로, 언어 모델을 활용하여 예측 작업을 수행할 수 있게 합니다. 이러한 접근 방식은 특히 비전문가 사용자에게도 쉽게 접근할 수 있는 예측 솔루션을 제공합니다. -
대규모 데이터셋 PISA 개발:
연구를 위해 세 가지 실제 예측 시나리오(날씨 예측, 에너지 소비 예측, 고객 유입 예측)를 포함하는 대규모 데이터셋인 PISA를 새롭게 구성했습니다. PISA 데이터셋은 다양한 시계열 예측 시나리오를 포함하고 있어, PromptCast 연구를 지원하고 관련 연구를 촉진할 잠재력을 가지고 있습니다. -
종합적인 벤치마크 제공:
PromptCast의 성능을 평가하기 위해 다양한 최신 수치 기반 예측 모델과 언어 생성 모델을 비교 평가했습니다. 이 벤치마크 결과는 PromptCast가 제로샷 설정에서도 뛰어난 일반화 능력을 보여주며, 새로운 예측 시나리오에서도 신속하게 적용될 수 있음을 입증합니다. 이를 통해 시계열 예측 연구 분야에 새로운 기준을 제시하고, 향후 연구 방향을 제시합니다.
Prompt-based Time Series Forecasting
본 논문에서 제안하는 prompt-based time series forecasting은 general한 time series task에 대해 동작하도록 설계됐습니다.
을 --라고 정의한다면, PromptCast는 총 M개의 서로 다른 forecasting task에 대해서 동작할 수 있습니다.
즉, 각 object에 대해서 연속형 time steps 만큼의 데이터를 수집하여 t 시점 이후 time steps 만큼 prediction 할 수 있습니다.
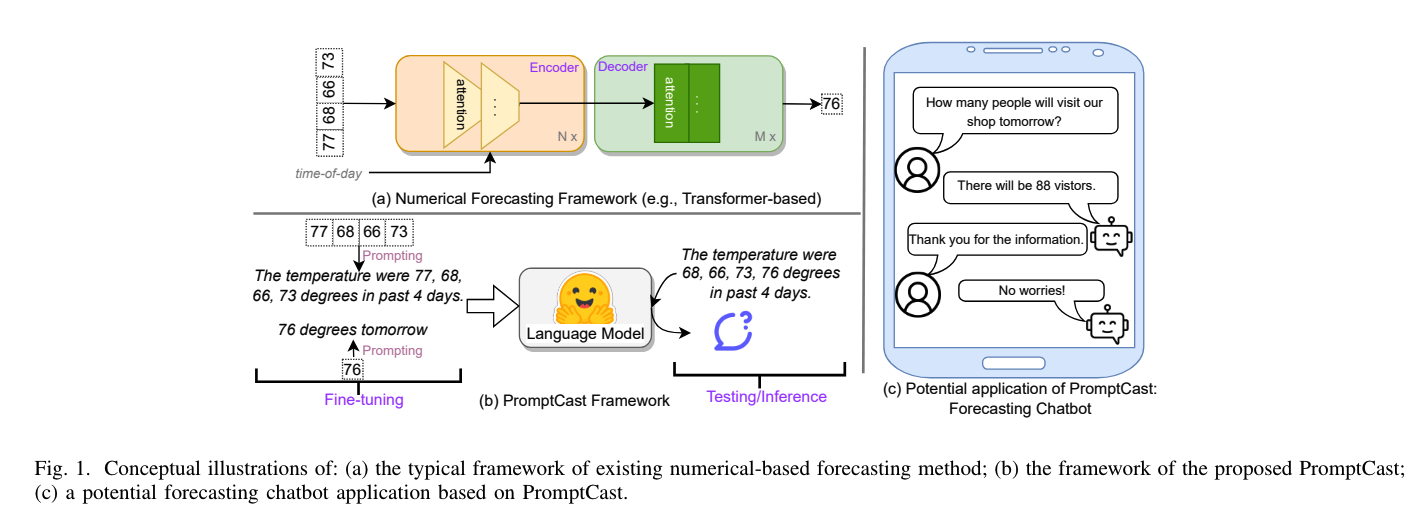
위 그림은 PromptCast의 전체적인 아키텍처와 이를 활용한 챗봇 형태의 어플리케이션을 나타냅니다.
이를 통해 예를 들면 다음과 같이 나타낼 수 있습니다.
- 입력과 출력의 변환: 기존의 수치 데이터를 자연어 문장으로 변환하여 모델에 입력합니다. 예를 들어, "지난 4일간 온도가 77도, 68도, 66도, 73도였습니다."라는 문장을 입력으로 주고, "내일 온도는 76도입니다."라는 예측 문장을 출력으로 받습니다.
- 언어 모델의 활용: 이러한 자연어 프롬프트를 통해 언어 모델을 시계열 예측에 직접 활용할 수 있게 합니다. 이를 통해 기존의 복잡한 수치 기반 모델 대신 언어 모델을 이용하여 예측 작업을 수행할 수 있습니다.
이와 같은 매커니즘을 단계 별로 보면 아래와 같은 과정을 거칩니다.
- 데이터 변환: 시계열 데이터를 자연어 문장으로 변환하는 과정입니다. 이 과정은 데이터의 각 시점을 문장으로 표현하고, 예측하려는 다음 시점을 질문 형식으로 변환합니다.
- 모델 학습: 자연어 처리 모델(예: BERT, T5 등)을 사용하여 이러한 문장 기반 예측 작업을 학습합니다. 이 모델은 문장을 입력으로 받아 예측 문장을 출력하는 방식으로 훈련됩니다.
- 예측 수행: 학습된 모델을 사용하여 새로운 데이터에 대한 예측을 수행합니다. 모델은 입력 문장을 받아 다음 시점에 대한 예측 문장을 생성합니다.
좀 더 직관적으로 나타내면 아래와 같은 예를 들 수 있습니다.
- 기존 방식: 수치 데이터를 직접 입력하고 출력하는 방식입니다. 예를 들어, 입력이 [77, 68, 66, 73]일 때 출력이 [76]이 됩니다.
- PromptCast 방식: 동일한 데이터를 "지난 4일간 온도가 77도, 68도, 66도, 73도였습니다."로 변환하여 입력하고, "내일 온도는 76도입니다."라는 예측 문장을 출력합니다.
Dataset Design and Description
PISA(Prompt-based tIme Series forecAsting) 데이터셋은 PromptCast 연구를 지원하기 위해 개발된 대규모 데이터셋으로, 세 가지 실제 예측 시나리오를 포함하고 있습니다.
A. 데이터 소스 및 처리
-
City Temperature (CT):
CT 데이터셋은 다수의 글로벌 도시에서 일일 평균 온도 데이터를 수집한 것입니다. 데이터 출처는 여러 도시의 일일 평균 온도 데이터를 제공하는 웹사이트로, 110개의 국제 도시를 무작위로 선택하여 데이터셋을 구성하였습니다. 각 도시의 일일 평균 온도 데이터를 수집하여, 특정 기간 동안의 온도 변화를 기록하였습니다. -
Electricity Consumption Load (ECL):
ECL 데이터셋은 321명의 사용자에 대한 전력 소비 데이터를 포함하고 있습니다. 원래 데이터는 시간 단위의 전력 소비를 기록하고 있었으나, 이 중 완전한 기록을 가진 50명의 사용자를 무작위로 선택하여 데이터셋을 구성하였습니다. 각 사용자의 시간당 사용량 데이터를 일일 사용량으로 통합하여 전력 소비 데이터를 생성하였습니다. -
SafeGraph Human Mobility Data (SG):
SG 데이터셋은 SafeGraph Weekly Patterns에서 제공하는 인간 이동 데이터를 포함하고 있습니다. 이 데이터셋은 특정 POI(Point of Interest)를 방문한 일일 방문자 수를 기록하고 있으며, 총 324개의 POI를 무작위로 선택하여 데이터셋을 구성하였습니다. 데이터 수집 기간은 약 15개월에 걸쳐 이루어졌습니다.
각 데이터셋은 학습(train), 검증(validation), 테스트(test) 세트로 나뉘며, 각 세트는 시간 순서에 따라 7:1:2 비율로 분할되었습니다. 슬라이딩 윈도우 기법을 사용하여 데이터 인스턴스를 생성하였으며, 관측 기간은 15일로 설정되었습니다.
B. 템플릿 기반 프롬프트 변환

PISA 데이터셋의 핵심은 수치 시계열 데이터를 자연어 문장으로 변환하는 것입니다. 이를 위해 Table 1과 같이 세 가지 데이터 시나리오에 대해 각각의 템플릿을 설계하였습니다. 템플릿은 입력 프롬프트와 출력 프롬프트로 구성됩니다.
- 입력 프롬프트: 관측 데이터의 기간과 값을 설명하는 문장으로 구성됩니다. 예를 들어, "2019년 8월 16일부터 2019년 8월 30일까지 지역 110의 평균 온도는 각각 78, 81, 83, 84, 84, 82, 83, 78, 77, 77, 74, 77, 78, 73, 76도였습니다."와 같은 형식입니다.
- 출력 프롬프트: 예측하려는 다음 시간 단계의 값을 질문 형식으로 제시합니다. 예를 들어, "2019년 8월 31일의 온도는 몇 도일까요?"와 같은 질문을 포함합니다.
이러한 템플릿 기반 변환을 통해 수치 데이터를 자연어 문장으로 변환하여, 언어 모델을 활용한 시계열 예측 작업을 수행할 수 있게 됩니다. 변환된 데이터는 자연어 생성 모델을 통해 학습 및 평가됩니다.
C. 데이터셋 통계 및 특징
PISA 데이터셋은 총 311,932개의 인스턴스를 포함하고 있으며, 각 시나리오별로 고유한 통계적 특성을 가지고 있습니다.
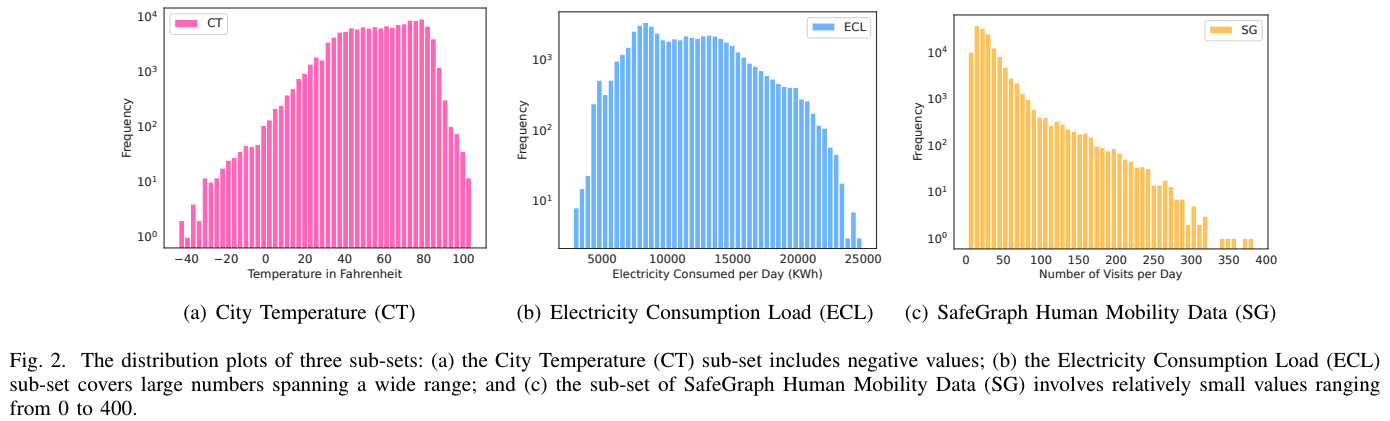
Figure 2는 각 데이터셋의 시계열 데이터 값이 어떻게 분포하는지를 시각화 한 결과입니다.
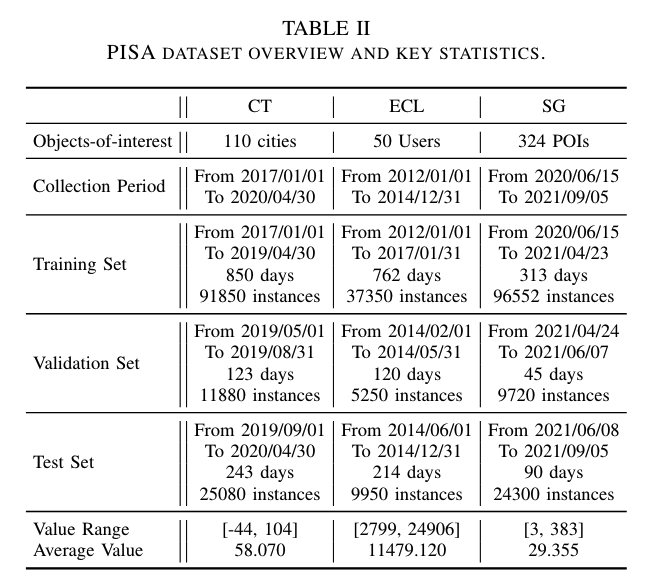
Table 2는 각 데이터셋에 대해서 더 자세한 지표들을 표 형태로 나타낸 결과 입니다.
- CT 데이터셋: 온도 데이터는 -44도에서 104도 사이의 범위를 가지며, 평균 값은 58.07도입니다. 음수 값을 포함하는 데이터셋입니다.
- ECL 데이터셋: 전력 소비 데이터는 2,799 kWh에서 24,906 kWh 사이의 범위를 가지며, 평균 값은 11,479.12 kWh입니다. 큰 값을 포함하는 데이터셋입니다.
- SG 데이터셋: 방문자 수 데이터는 3명에서 383명 사이의 범위를 가지며, 평균 값은 29.355명입니다. 비교적 작은 값을 포함하는 데이터셋입니다.
이러한 데이터의 다양성은 PISA 데이터셋이 다양한 예측 시나리오에서 모델의 성능을 평가하는 데 적합함을 보여줍니다. 데이터셋은 시계열 예측 모델의 성능을 비교하고 평가하는 데 중요한 역할을 하며, 다양한 예측 시나리오에서의 일반화 능력을 테스트할 수 있습니다.
Benchmark
PISA 데이터셋을 이용하여 다양한 실험을 통해 PromptCast의 성능을 평가하고, 두 가지 주요 연구 질문을 다룹니다.
1) 언어 생성 모델을 사용하여 시계열을 예측할 수 있는가?
2) 프롬프트를 사용하고 언어 생성 모델을 활용한 시계열 예측이 더 나은 일반화 능력을 가질 수 있는가?
A. Evaluation Metrics
PromptCast 작업은 언어 생성 작업으로, 목표는 타겟 출력 프롬프트를 생성하는 것입니다. 평가 프로토콜의 첫 단계는 생성된 문장에서 예측된 수치 값을 추출하는 것입니다. 이를 위해 간단한 문자열 파싱을 통해 예측 값을 추출하며, 각 테스트 인스턴스에 대해 예측 값을 성공적으로 디코딩할 수 없는 경우(즉, output 문자열에 수치 값이 없는 경우)도 반영하기 위해 Missing Rate를 도입하였습니다.
- Missing Rate:

Missing Rate는 전체 테스트 인스턴스 중 예측 값을 디코딩할 수 없는 인스턴스의 비율을 나타냅니다.
여기서 는 테스트 세트의 총 인스턴스 수, 는 예측 값을 성공적으로 디코딩한 인스턴스 수입니다.
또한, 예측 성능을 평가하기 위해 Root Mean Square Error (RMSE)와 Mean Absolute Error (MAE)를 사용합니다.

B. Baselines
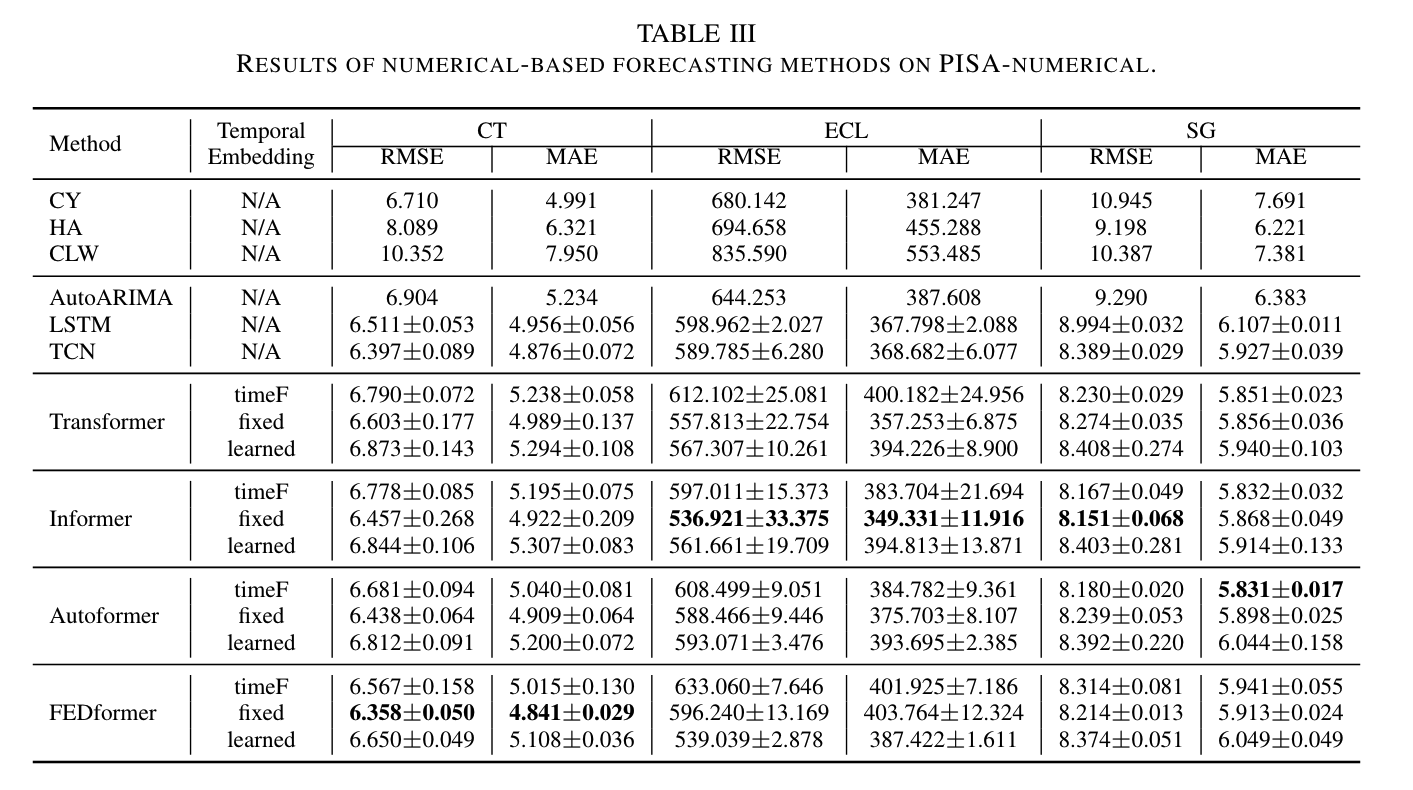
Table 3에서는 PromptCast 작업의 성능을 평가하기 위해 10개의 인기 있는 자연어 생성 모델(T5, Bart, BERT, RoBERTa, Electra, Bigbird, ProphetNet, LED, Blenderbot, Pegasus)을 테스트하였습니다. 또한, 비교를 위해 PISA-numerical을 사용하여 기존의 수치 기반 예측 방법도 평가하였습니다. 여기에는 3가지 나이브한 예측 방법(Copy Yesterday, Historical Average, Copy Last Week)과 3가지 기본 수치 예측 방법(AutoARIMA, LSTM, TCN), 그리고 최신 Transformer 기반 예측 방법들(Informer, Autoformer, FEDformer)이 포함됩니다.
C. 구현 세부 사항
수치 기반 예측 방법은 공식 FEDformer 리포지토리를 기반으로 구현되었으며, 언어 모델은 HuggingFace의 표준 Trainer를 사용하여 구현되었습니다. 각 언어 모델은 시계열 예측 작업에 맞추어 fine-tuning 되었으며, 특별한 하이퍼파라미터 튜닝 없이 기본 설정을 사용하여 공정한 비교를 보장하였습니다. 실험은 Nvidia V100 GPU를 사용하여 수행되었습니다.
-
Numerical Forecasting Methods:
- FEDformer, Informer, Autoformer의 공식 구현을 사용.
- 기본 하이퍼파라미터 설정을 사용하며, pred_len은 7로 설정.
- Temporal embedding 방법(timeF, fixed, learned)을 비교 평가.
-
Language Models:
- HuggingFace 라이브러리를 사용하여 언어 모델을 구현.
- BERT, RoBERTa, Electra는 EncoderDecoderModel을 사용.
- 나머지 모델은 ConditionalGeneration 프레임워크를 사용하여 구현.
- 학습 과정에서 특별한 손실 함수 변경 없이 표준 Trainer를 사용.
D. 실험 성능
1) Numerical-based methods
PISA 데이터셋을 사용하여 전형적인 수치 기반 예측 방법을 평가하였습니다. 일반적으로 Transformer 아키텍처(및 그 변형들)에서 사용되는 위치 임베딩은 제한된 위치 정보만을 포함합니다. 이는 모든 입력 데이터 인스턴스에 대해 동일한 위치 정보를 가지므로, 시계열 데이터에서 중요한 시간 정보를 반영하지 못합니다. 예를 들어, 인스턴스 A의 첫 번째 시간 단계는 월요일에 해당할 수 있지만, 인스턴스 B의 첫 번째 시간 단계(동일한 위치)는 금요일에 해당할 수 있습니다. 따라서 기본 위치 임베딩에 시간 임베딩을 추가하는 것이 Transformer 기반 시계열 예측 방법에서 인기를 끌고 있습니다. 이는 PromptCast의 입력 프롬프트에 시간 정보를 제공하는 것과 같습니다.
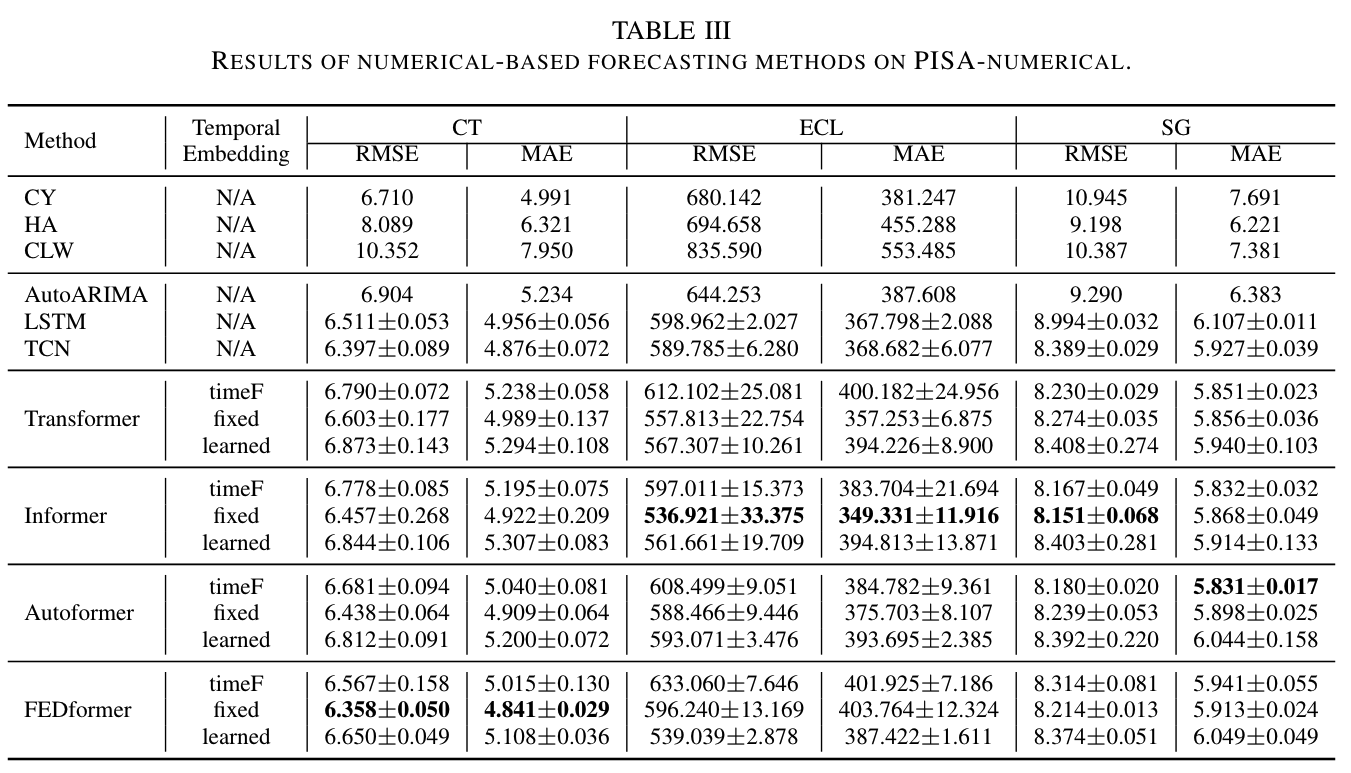
Informer와 Autoformer의 구현을 기반으로 세 가지 임베딩 접근 방식(timeF, fixed, learned)을 조사하고 벤치마킹했습니다. 세 가지 시간 임베딩 방법은 Autoformer의 구현을 따릅니다. 기본적으로 timeF 임베딩은 nn.Linear() 함수를 통해 이루어지며, fixed와 learned 임베딩은 nn.Embedding() 함수를 기반으로 합니다. fixed 임베딩은 비학습 가능한 매개변수를 가지며(기본 Transformer의 sin/cos 위치 임베딩과 유사), learned 임베딩의 매개변수는 학습 가능합니다. 이 방법을 통해 세 가지 임베딩 방법을 사용하여 입력 데이터의 시간 정보를 캡처하고, 예측 작업에 대한 종합적인 평가를 제공합니다.
FEDformer, Informer, Autoformer가 대부분의 경우에서 최고의 성능을 발휘했습니다. 대부분의 경우에서 이들 고급 시계열 예측 프레임워크는 기본 Transformer, 나이브 방법, non-Transformer 방법보다 우수한 성능을 보였습니다. 나이브 방법은 다른 방법에 비해 예측 성능이 떨어지는 것으로 나타났습니다. 임베딩을 비교할 때, fixed 임베딩이 전반적으로 좋은 성능을 보였습니다. 이 임베딩은 6개의 지표 중 5개에서 좋은 예측 결과를 나타냈고, timeF는 나머지 하나의 지표(SG의 MAE)에서 최고 성능을 보였습니다. learned 임베딩은 CT와 SG에서 가장 낮은 성능을 보였지만, ECL에서는 timeF를 능가했습니다. 이 결과는 fixed 임베딩이 시간 정보를 통합하는 데 유리한 접근 방식임을 시사합니다.
2) Pre-trained language models

벤치마크에서 조사된 언어 모델은 HuggingFace에서 제공하는 사전 학습된 가중치를 초기화에 사용했습니다. 모델 구성 세부 사항은 Table 6에 나와 있으며, 해당 모델 키를 통해 HuggingFace에서 사전 학습된 모델을 접근하고 다운로드할 수 있습니다. 사전 학습된 가중치는 BookCorpus, CC-News, OpenWebText와 같은 일반 영어 코퍼스 데이터셋으로 학습되었습니다. 이러한 일반적인 언어 데이터셋은 특정 시계열 데이터가 포함되지 않습니다. PISA의 세 가지 데이터 소스는 공개적으로 이용 가능하지만, 원본 수치 데이터는 CSV 형식으로만 온라인에서 얻을 수 있으며, 이는 데이터 누출을 방지합니다. 각 언어 모델은 PISA의 각 하위 세트의 학습 세트로 미세 조정되었습니다.
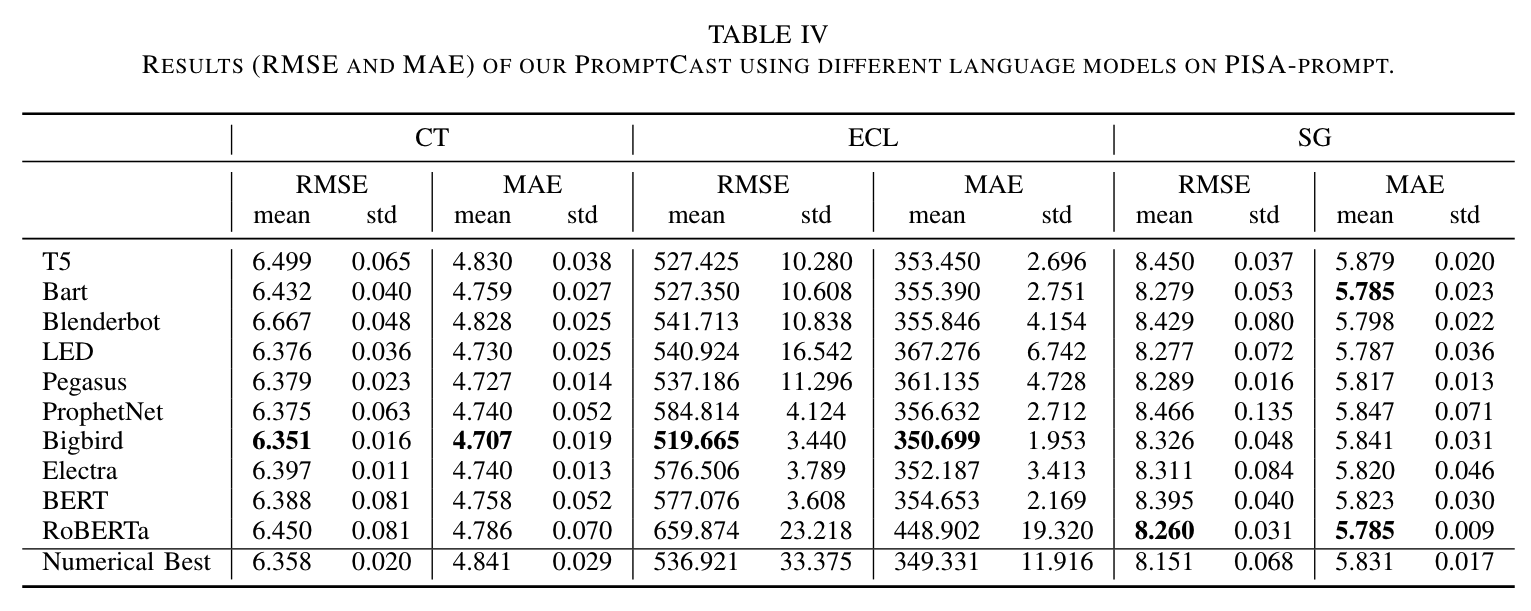
Table 4는 PISA 데이터셋에서 다양한 언어 생성 모델을 사용한 예측 결과(RMSE 및 MAE)를 나열하고 있습니다. 표에 따르면, 상위 성능 모델은 Bigbird, Bart, RoBERTa입니다. Bigbird는 6개의 지표 중 4개에서 최고의 성능을 보였습니다. Table 3과 Table 4를 함께 고려할 때, 언어 모델을 사용하는 것이 CT와 ECL 하위 세트에서 합리적인 성능을 발휘함을 알 수 있습니다. ECL에서는 언어 모델을 사용한 MAE가 Table 3의 최고 성능보다 약간 낮지만, RMSE는 상대적으로 큰 개선을 보였습니다. 수치 기반 방법과 비교했을 때, 언어 모델을 사용한 결과는 SG에서도 유사한 결과를 얻을 수 있었습니다. 이 벤치마크는 RQ1에 대한 답을 제공하며, 언어 모델을 사용한 프롬프트 기반 예측이 시계열 예측 연구의 유망한 방향임을 나타냅니다.
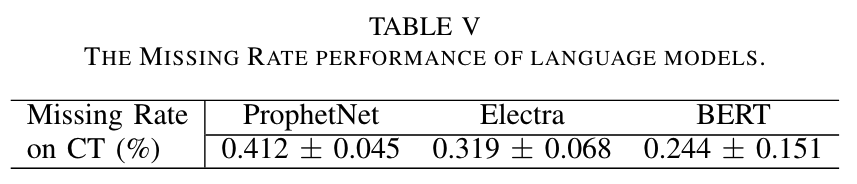
Table 5는 Missing Rate 메트릭을 보고합니다. ProphetNet, Electra, BERT의 경우 소량(0.5% 미만)의 누락 사례가 있으며, 모든 사례는 CT 하위 세트에서 발생합니다. Table 5에 나열되지 않은 다른 방법들의 Missing Rate는 모두 0입니다. 디코딩할 수 없는 출력 문장을 조사한 결과, 실패 사례는 음수 값과 관련이 있는 것으로 나타났습니다. 예를 들어, "temperature will be - - - -"와 같은 문장을 생성할 때 모델이 "-" 이후의 토큰을 생성하지 못하는 경우가 있습니다. PISA 데이터셋은 이 제한 사항을 해결하기 위한 연구 방향을 지원하는 데 가치가 있습니다.
3) Perfermance of ChatGPT
최신 GPT 모델의 시계열 예측 능력을 보여주기 위해 OpenAI API를 사용하여 GPT-3.5("gpt-3.5-turbo", 2023년 8월 접속) 성능을 평가했습니다. GPT-4와 GPT-3.5의 미세 조정 서비스는 비용이 매우 높아, 이번 실험은 미세 조정 없이 GPT-3.5를 사용했습니다. 평가 과정에서 PISA 테스트 세트의 입력 프롬프트를 쿼리로 사용하여 API의 응답을 수집했습니다.
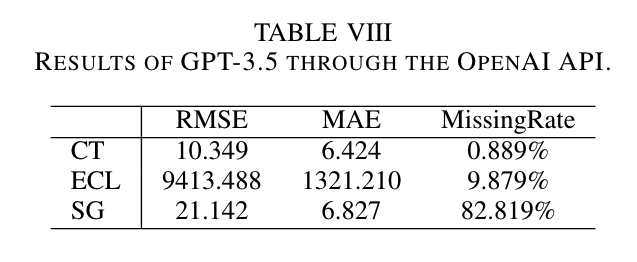
GPT-3.5의 성능 결과는 Table 8에 요약되어 있습니다. 수치 예측 방법과 PromptCast의 결과와 비교했을 때, GPT-3.5는 세 가지 하위 세트 모두에서 더 높은 RMSE와 MAE 값을 나타냈습니다. 특히 SG 하위 세트에서 GPT-3.5는 높은 Missing Rate를 보였습니다. ECL 하위 세트에서는 "소비를 예측하기 어렵습니다"와 같은 텍스트를, SG 하위 세트에서는 "사람 수를 결정할 수 없습니다"와 같은 텍스트를 자주 출력했습니다. 대부분의 경우 GPT-3.5는 관찰 기간의 입력 값을 단순히 평균하여 예측 값을 생성했습니다. 세 가지 하위 세트에 대한 전체 출력 결과는 논문 저자들의 GitHub 리포지토리에서 확인할 수 있습니다.
4) Computation Cost
원고를 더욱 풍부하게 하기 위해 Transformer 기반 수치 예측 방법, 다양한 언어 모델을 사용한 PromptCast, 그리고 GPT-3.5(ChatGPT 모델)의 파라미터 수, 인퍼런스 실행 시간(인스턴스당, 초 단위), 배포 비용(인스턴스당, USD ×10^-5 단위)을 비교했습니다. GPT-3.5의 비용 성능은 OpenAI API("gpt-3.5-turbo" 모델, 2023년 8월 접속)를 사용하여 평가했습니다. 나머지 방법들은 AWS의 Nvidia V100 GPU를 사용하여 배포 비용을 추정했습니다(p3.2xlarge 인스턴스의 Nvidia V100 사용 비용은 시간당 3.06 USD). 모델의 비용은 계산 시간과 관련이 있으며, GPT-3.5의 경우 입력 및 출력 토큰 수에 따라 비용이 산정되고, API 요청 및 응답 시간도 포함됩니다.
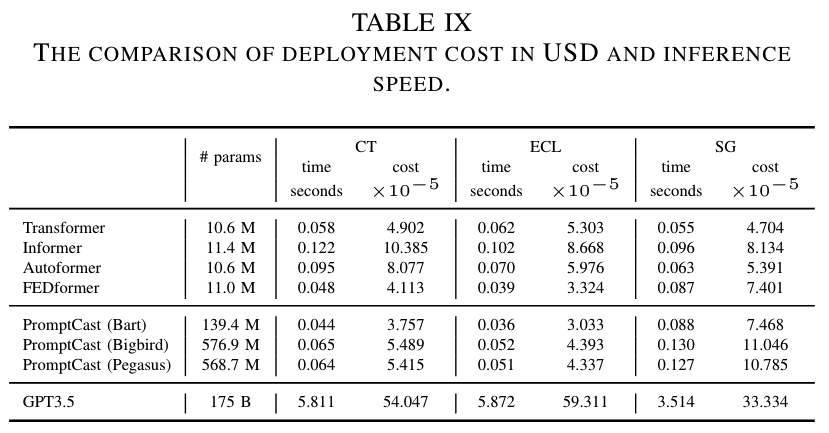
Table 9는 PISA의 세 가지 하위 세트에서 다양한 모델을 종합적으로 비교한 결과를 제공합니다. 표에서 알 수 있듯이, GPT-3.5(OpenAI API)는 매우 큰 자원 집약적 모델로, 다른 모델에 비해 계산 요구 사항과 관련 비용이 상당히 높아 비용 효율성이 낮습니다. 제안된 PromptCast의 경우, 언어 모델이 더 많은 파라미터를 가지고 있지만, Transformer 기반 수치 예측 모델과 비교했을 때 계산 시간과 관련 비용에서 큰 차이가 없습니다. 이 계산 비용 비교는 PromptCast가 예측 정확도뿐만 아니라 비용 면에서도 효율적임을 보여줍니다.
E. Training from scratch
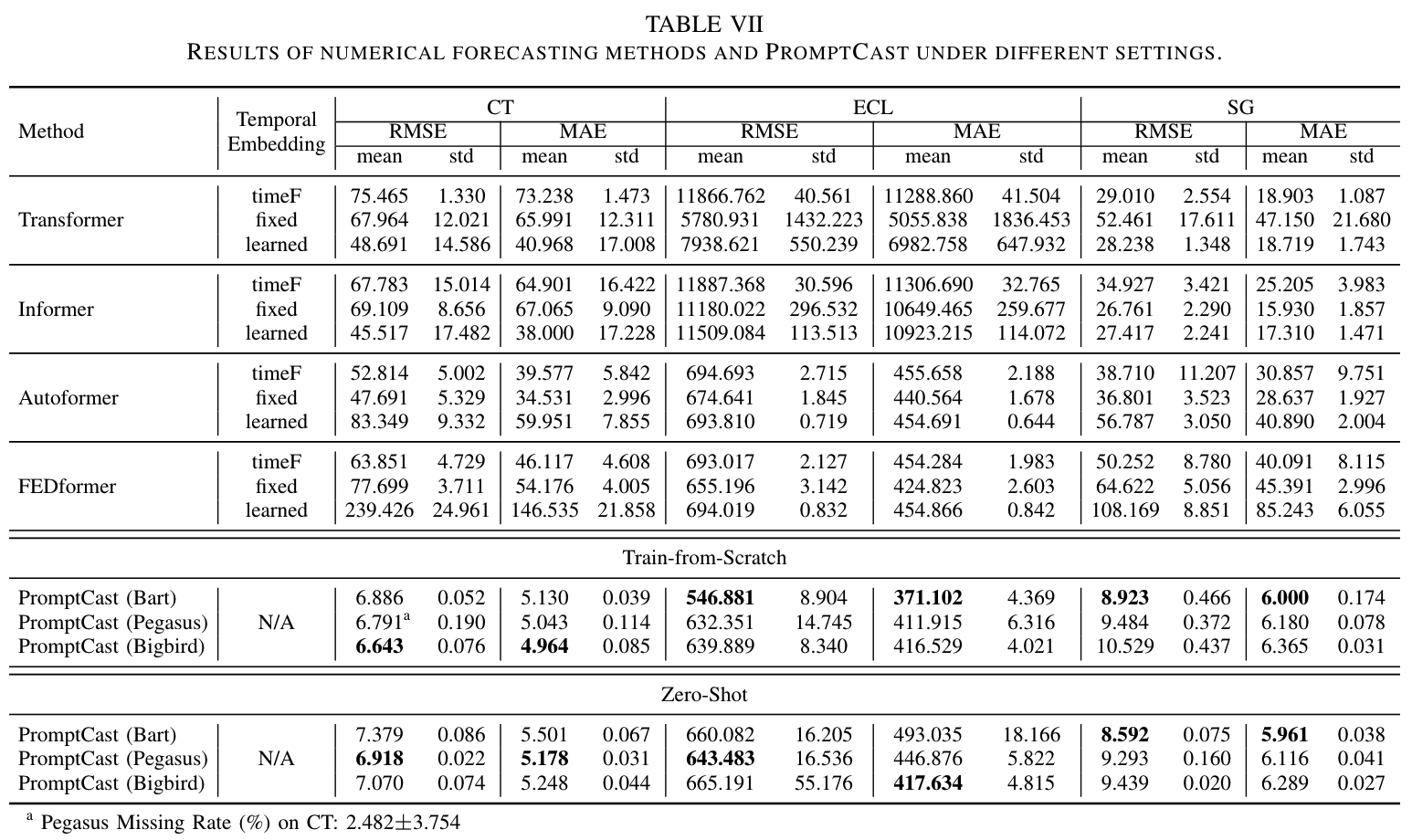
사전 학습된 가중치를 사용하지 않고도 언어 모델이 시계열 예측에 사용될 수 있는지를 평가하기 위해 Bart, Pegasus, Bigbird 모델을 초기 학습하여 실험을 수행하였습니다. 사전 학습된 가중치를 사용하지 않았을 때 성능이 저하되었지만, 여전히 수치 기반 방법과 비슷한 예측 성능을 보였습니다.
- Bart: RMSE 6.886, MAE 5.130 (CT 데이터셋)
- Pegasus: RMSE 6.791, MAE 5.043 (CT 데이터셋)
- Bigbird: RMSE 6.643, MAE 4.964 (CT 데이터셋)
F. Zero-shot Performance
언어 모델을 프롬프트 기반 예측에 활용하기 위해 제로샷 설정에서 실험을 수행했습니다(Table 7 참조). 각 모델은 두 개의 하위 세트에서 미세 조정하고, 미세 조정된 모델을 남은 하위 세트의 테스트 세트에서 테스트했습니다(ex. CT와 ECL로 미세 조정하고 SG에서 테스트). Transformer 기반 수치 방법도 동일한 제로샷 설정에서 평가했습니다. 결과적으로 fixed 임베딩이 다른 두 임베딩보다 더 나은 성능을 보였으며(6개 지표 중 5개에서), 이는 시간 정보를 잘 반영하기 때문입니다. Autoformer와 FEDformer를 제외하고 수치 기반 방법은 제로샷 설정에서 만족스러운 예측을 생성하지 못했습니다. 이는 세 하위 세트의 특성이 뚜렷하게 다르기 때문입니다. 반면, 언어 모델은 표준 설정과 초기 학습 설정보다 성능이 낮지만, 프롬프트 기반 예측은 여전히 합리적인 예측을 생성할 수 있었습니다. 이는 프롬프트를 사용한 시계열 예측에서 강력한 일반화 능력을 보여줍니다(RQ2). 이러한 제로샷 능력은 새로운 예측 시나리오에 대한 신속한 배포와 데이터가 없는 상황에서 초기 예측에 유리합니다. 향후 프롬프트 기반 예측은 더 복잡한 시나리오(ex. 날씨 기반 에너지 소비 예측, 온도 추세 기반 고객 트래픽 예측)를 탐구할 수 있습니다.
G. Prompts Ablation Study
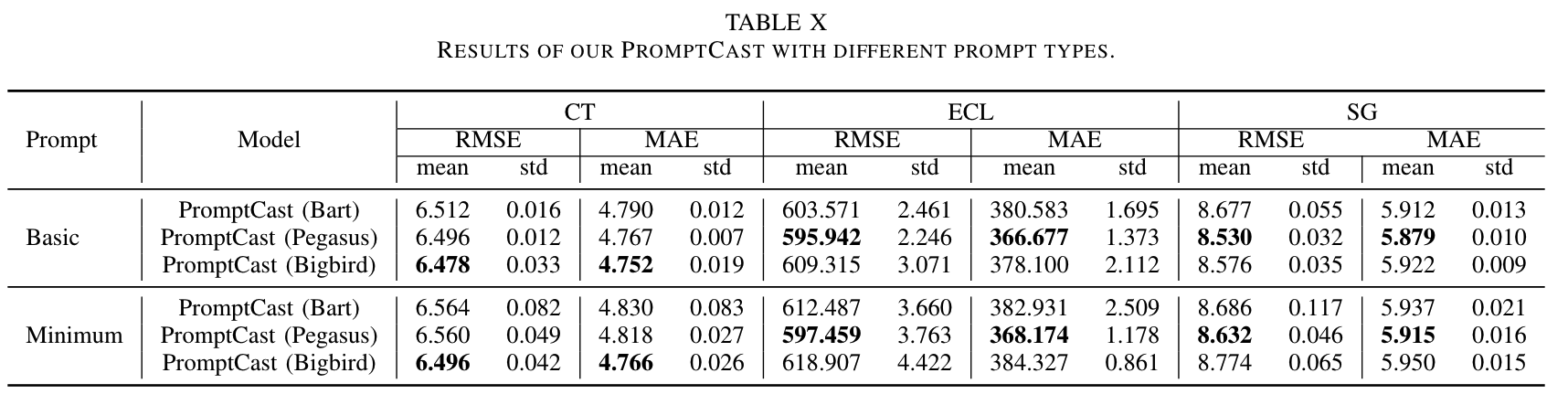
PromptCast 작업에서 프롬프트의 중요성을 평가하기 위해 두 가지 간소화된 프롬프트(기본 프롬프트와 최소 프롬프트)를 개발하고 소거 연구를 수행했습니다. 기본 프롬프트는 보조 정보를 제거하고(ex. 날짜 정보) 핵심 정보(ex. 과거 관찰 값)만 유지한 것입니다. 출력 프롬프트는 동일하게 유지됩니다. 최소 프롬프트는 프롬프트의 가장 간단하고 직관적인 버전으로, 수치 값을 콤마로 구분한 문자열(ex. “78, 81, 83, 84, 84, 82, 83, 78, 77, 77, 74, 77, 78, 73, 76”)로 변환합니다. 출력 프롬프트는 예측 대상 값을 단일 단어 문자열(ex. “78”)로 직접 사용합니다. Table 10에 따르면, 두 간소화된 프롬프트 모두 기본 템플릿(Table 1 참조)보다 성능이 떨어졌으며, 기본 프롬프트가 최소 프롬프트보다 더 나은 성능을 보였습니다. 이는 적절한 컨텍스트(추가 데이터가 없는 경우에도)가 예측 성능에 유익하며, 보조 정보가 더 나은 예측 성능을 위한 중요한 요소임을 시사합니다.
H. Multi-step Forecasting

PromptCast는 multi-step 예측 시나리오에도 적합합니다. multi-step 예측을 위해 입력 프롬프트 템플릿의 질문 부분을 "다음 Y일 동안 POI를 방문할 사람 수는 몇 명인가요?"로 업데이트하고, 출력 프롬프트도 multi-step 미래 데이터 값을 반영하도록 수정했습니다. 예를 들어, SG 하위 세트에서 다음 7개의 시간 단계를 예측하는 경우(n = 7), 입력 프롬프트는 "2021년 4월 24일 토요일부터 2021년 5월 8일 토요일까지 POI 1을 매일 방문한 사람 수는 6, 8, 6, 15, 12, 4, 13, 7, 8, 12, 16, 9, 11, 18, 10명이었습니다. 다음 7일 동안 POI 1을 방문할 사람 수는 몇 명인가요?"와 같으며, 출력 프롬프트는 "2021년 5월 9일 일요일부터 2021년 5월 15일 토요일까지 방문할 사람 수는 11, 11, 8, 13, 10, 18, 19명입니다."와 같이 작성됩니다.
이러한 수정된 프롬프트를 바탕으로, 다양한 관찰 길이(입력 길이)와 예측 horizon(출력 길이)을 사용하여 세 가지 언어 모델(Bart, Bigbird, Pegasus)의 성능을 평가했습니다. 구체적으로, 7일 및 15일의 관찰 길이 설정과 1일, 4일, 7일의 예측 수평선을 사용하여 총 6개의 길이 구성 조합을 테스트했습니다. 다양한 길이 설정 조합과 관련된 다수의 실험을 처리하기 위해 "fixed" 시간 임베딩을 사용하는 Transformer 기반 수치 예측 방법의 결과만 독점적으로 제시했습니다.
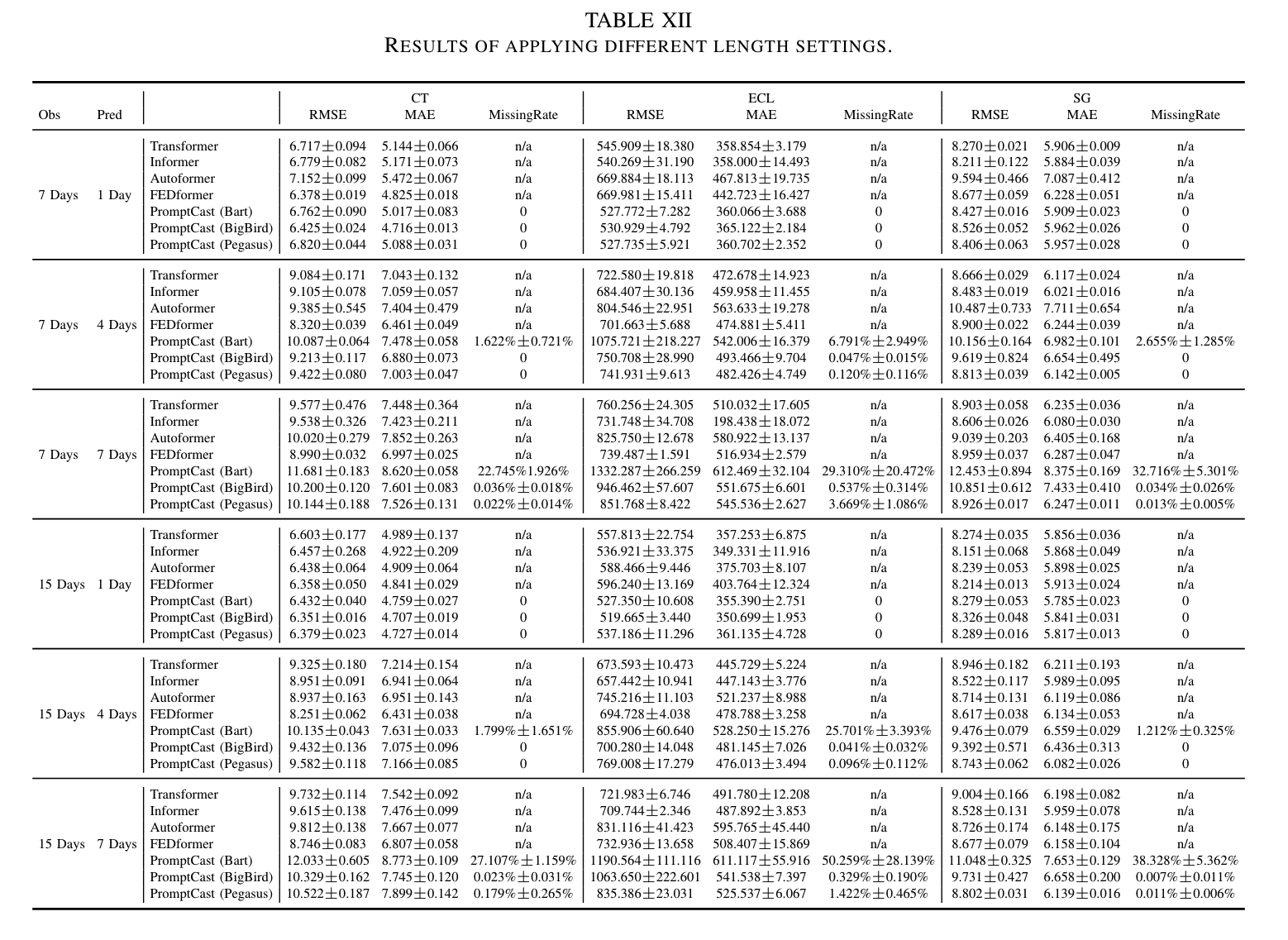
Table 12에 따르면, PromptCast는 동일한 예측 모델 아키텍처(즉, 언어 모델)를 사용하여 multi-step 예측에도 쉽게 적응할 수 있습니다. 일반적으로 단일 단계 예측 성능과 비교할 때, 예측 수평선이 길어지면 Missing Rate가 증가하는 경향이 있습니다. Transformer 기반 방법과 비교할 때, 언어 모델은 "7일을 관찰하여 7일을 예측"하고 "15일을 관찰하여 7일을 예측"하는 시나리오에서 덜 유리한 예측을 보입니다. 특히 Bart는 다양한 하위 세트에서 높은 Missing Rate를 보여 서브 최적 성능을 보였습니다. 그러나 Bigbird와 Pegasus는 이러한 어려운 설정에서도 매우 낮은 Missing Rate로 합리적으로 정확한 예측을 제공합니다. 특히 Pegasus의 성능은 이 두 설정에서 최첨단 Transformer 기반 방법에 매우 근접합니다. 15일 관찰 기간을 사용하면 동일한 미래 길이를 예측할 때 더 나은 성능을 보이는 경향이 있습니다. 이는 15일 기간이 관찰에서 주간 패턴을 포함하기 때문에 더 정확한 예측을 가능하게 하는 것으로 보입니다. multi-step 예측의 성능에 대한 추가적인 인사이트를 제공하기 위해 다음 7일 설정에 대한 추가 예제는 논문 저자들의 리포지토리에서 확인할 수 있습니다. PromptCast의 다양한 길이에 대한 탐구는 모델이 동적 관찰/예측 길이에 대해 견고하며 시계열 예측의 유망한 연구 방향을 제시함을 보여줍니다.
I. Multivariate Time Series Forecasting
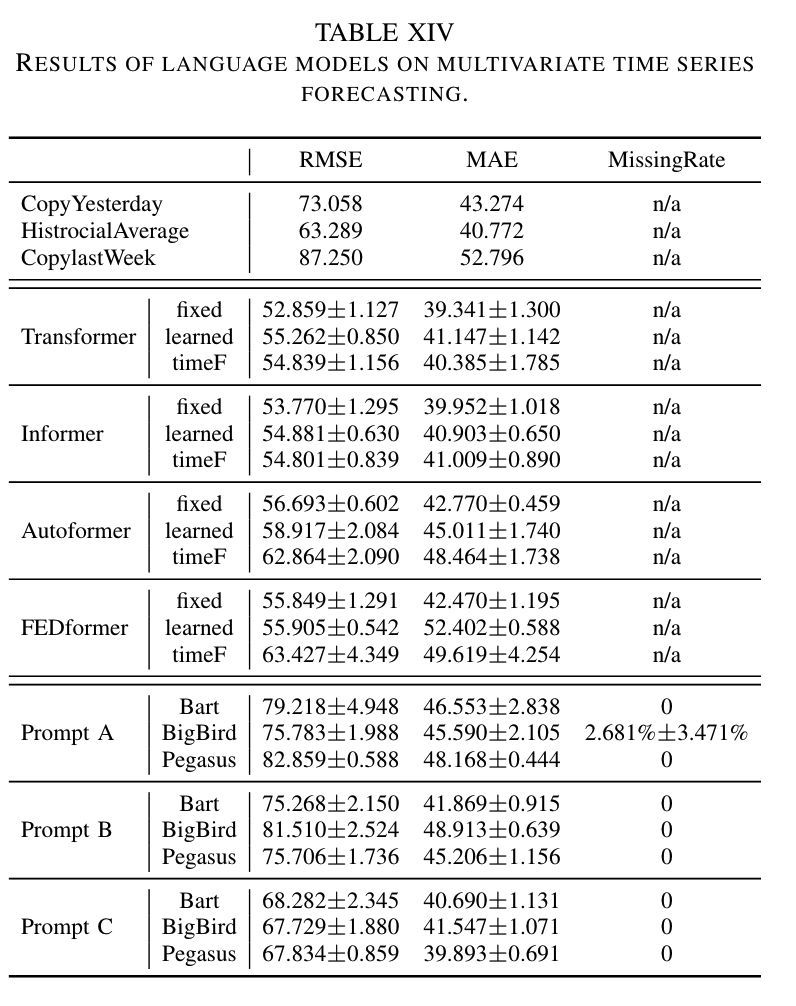
PromptCast를 처음 도입할 때는 기본 예측 설정에서 개념을 입증했지만, 이 패러다임은 다변량 시계열 예측과 같은 다른 설정에도 유연하게 적용될 수 있습니다. PromptCast를 다변량 예측에 적용하려면 프롬프트 템플릿만 업데이트하면 되며, 언어 모델과 사전 학습된 가중치는 동일하게 사용할 수 있습니다. 반면, 전통적인 수치 예측 방법은 예측 설정 변경 시 모델 구조와 하이퍼파라미터를 수정해야 합니다. 이는 PromptCast의 "codeless" 이점과 견고성을 반영합니다.
PromptCast의 다변량 예측 능력을 조사하기 위해, PISA 데이터셋 외에도 베이징 대기 질 데이터를 사용하여 파일럿 연구를 수행했습니다. 이 데이터셋은 2013년 3월 1일부터 2017년 2월 28일까지 수집되었으며, PM2.5, PM10, SO2 세 가지 대기 오염 물질에 초점을 맞추었습니다. 프롬프트 템플릿을 다변량 특성을 포함하도록 업데이트하여 Table 14에 세 가지 다른 프롬프트를 설계하고 검토했습니다. 프롬프트 A와 B는 세 특성을 함께 설명하거나 따로 설명하는 방식이며, 프롬프트 C는 단변량 특성으로 분해하는 방식입니다.
Table 15에 따르면, 세 언어 모델 모두 거의 0%의 Missing Rate를 기록하며 합리적인 예측을 생성했습니다. 프롬프트의 설계는 예측 성능에 영향을 미쳤으며, 프롬프트 C가 가장 우수한 성능을 보였습니다. PromptCast는 MAE 성능에서 더 나은 성과를 보였지만 RMSE 성능은 Transformer 기반 베이스라인보다 낮았습니다. 이는 프롬프트가 다양한 특성 간의 관계를 완전히 설명하지 못하기 때문입니다.
Open Question and Future Work
이 결과는 단변량 시계열에 사용된 모델 아키텍처가 다변량 시계열에도 적용될 수 있음을 보여주며, PromptCast가 다변량 시계열 예측에 유망한 방향임을 나타냅니다. 그러나 PromptCast를 사용한 다변량 시계열 예측의 동작을 완전히 이해하고 더 견고한 모델을 개발하기 위해 추가 연구가 필요합니다. 앞으로 다양한 시간 특성 간의 내부 상관 관계를 학습하고 이를 나타내는 프롬프트를 개발하는 방향으로 연구를 진행할 것이라고 합니다.
Case Studies
Why Language Model Works for Forecasting
이전 실험을 통해 PromptCast 작업이 시계열 예측을 위한 새로운 패러다임을 제시한다는 것을 보여주었습니다. 이 섹션에서는 언어 모델이 예측에 사용될 수 있는 이유를 면밀히 하고자 합니다.
언어 모델의 아키텍처는 시계열 데이터의 특성과 잘 맞아떨어집니다. 시계열 예측과 언어 생성은 모두 시퀀스-투-시퀀스 프로세스이기 때문에 언어 모델을 시계열 예측에 적용하는 것이 자연스럽습니다. 시계열 예측은 NLP에서 다음 문장을 예측하는 문제와 유사하게 볼 수 있으며, 이는 사전 학습된 기초 모델을 사용하여 효과적으로 해결할 수 있습니다.
또한, 시간 정보나 의미론적 정보와 같은 부가 정보를 사용하는 것은 예측 성능을 향상시키는 데 유용합니다. 전통적인 수치 기반 예측 방법에서는 이러한 의미론적 컨텍스트를 통합하기 위해 특별한 계층이나 모듈을 설계해야 하는 추가 작업이 필요합니다. 반면 PromptCast에서는 프롬프트 과정이 컨텍스트 정보와 시계열 데이터를 효과적으로 통합하여 의미론적 정보와 수치 값을 하나의 토큰으로 변환합니다. 언어 모델은 이러한 관계를 학습하여 우수한 예측 성능을 제공합니다.
위의 가설을 검증하기 위해 두 가지 사례 연구를 수행하고 언어 모델(Bart 모델 사용)의 학습된 attention weight를 시각화했습니다.
case study 1:
- Input: 2019년 9월 6일 금요일부터 2019년 9월 20일 금요일까지 지역 1의 평균 기온은 각각 65, 66, 70, 71, 71, 77, 78, 65, 70, 76, 74, 70, 64, 61, 64도였습니다. 2019년 9월 21일 토요일의 기온은 몇 도일까요?
- Prediction: 기온은 68도일 것입니다.
- Ground Truth: 기온은 71도일 것입니다.
case study 2:
- Input: 2021년 6월 8일 화요일부터 2021년 6월 22일 화요일까지 매일 POI 1을 방문한 사람 수는 각각 13, 16, 9, 11, 21, 9, 13, 15, 8, 24, 9, 10, 11, 10, 14명이었습니다. 2021년 6월 23일 수요일에 POI 1을 방문할 사람 수는 몇 명일까요?
- Prediction: 11명이 방문할 것입니다.
- Ground Truth: 12명이 방문할 것입니다.
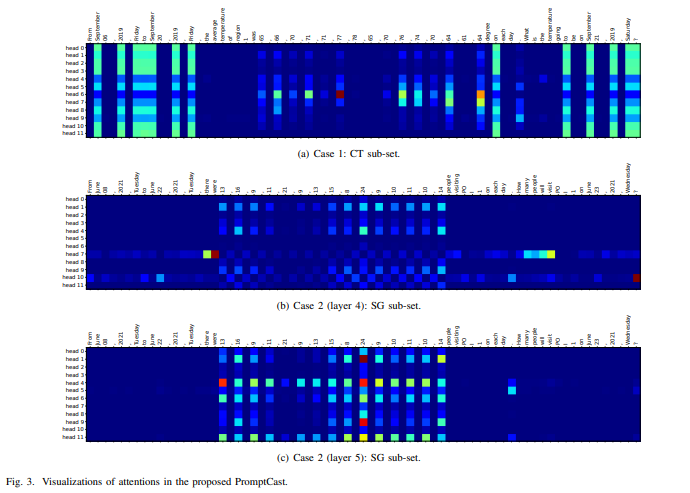
Figure 3에서 언어 모델이 입력 문장과 출력 문장 사이의 attention weight를 학습한 결과를 시각화했습니다. 각 heatmap plot에서 columns는 입력 프롬프트(토큰 형식)를 나타내고, rows은 다양한 attention head를 나타냅니다.
case 1 (Figure 3 (a)):
- 헤드 6은 입력 프롬프트의 수치 데이터에 주로 주의를 기울이며, 다른 헤드들은 'September'와 'Friday'와 같은 의미론적 부가 정보에 더 높은 attention weight를 가집니다.
- 헤드 7은 입력 수치 관찰 값(ex. 76, 74, 64)과 의미론적 토큰에 동시에 attention을 수행합니다.
case 2:
- 두 층의 주의 시각화 결과는 Figure 3 (b)와 Figure 3 (c)에 표시됩니다.
- Bart 모델의 5번째 층(Figure 3 (c))에서 예측 값과 입력 프롬프트의 수치 값 간의 attention이 주로 학습되었습니다.
- 4번째 층(Figure 3 (b))은 수치 토큰뿐만 아니라 컨텍스트 토큰에도 attention을 수행합니다. 예를 들어, 헤드 7은 'there were'와 'How many people will visit'와 같은 의미론적 토큰에, 헤드 10은 보조 날짜 토큰 '22'와 구두점 토큰 '?'에 attention합니다.
이 연구들은 언어 모델이 PromptCast 패러다임에서 수치 값 토큰(과거 값)과 부가 정보 토큰을 모두 고려하여 예측을 생성할 수 있음을 보여줍니다.
Discussion and Conclusion
이 논문에서는 언어 모델을 사용하여 언어 생성 방식으로 시계열을 예측하는 새로운 작업인 PromptCast를 소개했습니다. PromptCast 작업에 적합한 기존 데이터셋이 없기 때문에, 우리는 프롬프트 기반 예측을 조사하기 위해 최초의 데이터셋인 PISA를 구축했습니다. 이 대규모 데이터셋은 세 가지 실제 시계열 예측 시나리오를 포함하고 있습니다. 또한, PromptCast 연구를 진전시키기 위해 공개된 데이터셋에 대한 벤치마크를 설정하고, 최신 수치 예측 방법과 언어 생성 모델을 포함한 강력한 기준선을 제공했습니다. 실험 결과, PromptCast 설정에서 언어 모델을 사용하는 것이 좋은 예측 성능과 일반화 능력을 보임을 입증했습니다.
이 연구의 결과는 시계열 예측 분야의 연구자들에게 새로운 개념과 통찰력을 제공할 것입니다. 또한, 제안된 PromptCast 작업과 PISA 데이터셋은 아래 예시들과 같이 새로운 관련 연구 방향을 열고, 이 작업을 통해 가능해질 다운스트림 응용 프로그램에 대한 잠재력을 갖고 있습니다.
-
Automatic Prompting
이 논문에서는 템플릿을 사용하여 수치 데이터를 텍스트로 변환했습니다. 템플릿 기반 프롬프트는 효율적이지만 다양한 프롬프트를 생성하기 어렵고, 고정된 템플릿은 편향을 도입할 수 있습니다. 이를 해결하기 위해 자동 시계열 프롬프트 생성 또는 시계열 캡션 생성(이미지 캡션 생성과 유사)을 개발하는 것이 한 가지 연구 방향입니다. -
Explainable PromptCast
언어 모델링 작업을 위해 설계된 모델이 시계열을 예측할 수 있는 이유를 탐구하는 것도 중요한 연구 영역입니다. 우리는 사례 연구를 통해 왜 언어 모델이 시계열 예측에 효과적인지에 대한 초기 생각을 논의했지만, PromptCast 모델의 해석 가능성과 설명 가능성에 대한 추가 연구는 더 나은 모델을 설계하고 현재 모델의 한계를 이해하는 데 도움이 될 것입니다. -
PromptCast QA and Chatbot:
PromptCast 연구는 시계열 예측 질문 응답 작업과 예측 기능을 가진 챗봇 애플리케이션 개발을 촉진할 수 있습니다. PromptCast QA 작업은 주어진 연속적인 수치 값 컨텍스트를 기반으로 예측하는 질문 응답 능력이 핵심입니다.
Limitation and Future Work
PromptCast 작업을 위한 새로운 데이터셋을 처음으로 생성함에 따라, 이번 데이터셋 릴리스에서는 단변량 시계열 예측 설정에 주로 집중했습니다. 향후 연구 방향으로는 더 복잡한 시계열 예측 시나리오를 지원하는 다변량 시계열을 포함하도록 데이터셋을 확장하는 것입니다. 또한, 다단계 예측 설정에서 PromptCast 성능을 더욱 향상시키기 위해 자기 회귀 방법을 개발하는 것입니다. 예를 들어, 언어 모델을 다음 시간 단계의 값을 예측하도록 미세 조정할 수 있습니다. 생성된 문장은 더 긴 수평선을 예측하기 위해 입력 프롬프트에 반복적으로 추가될 것입니다. 또한, 여러 데이터 소스를 통합하는 더 도전적인 이질적인 데이터셋도 미래의 PromptCast 작업에 고려될 것입니다. 프롬프트 기반 패러다임은 시계열 분류 및 이상 탐지와 같은 다른 작업으로 확장될 수 있으며, 이는 제안된 패러다임을 더 넓은 범위의 실제 시나리오에 적용할 수 있게 할 것입니다.
