Abstract
Self-supervised 방법론은 time series anomaly detection에서 사용 가능한 annotation이 부족하기 때문에 두각을 나타낼 수 있었다. 그럼에도 불구하고, representation map을 일반화하기엔 샘플이 몇 개 없기 때문에 성능 상 한계가 존재한다. 이를 극복하기 위해서 논문에서는 knowledge distillation을 time series anomaly detection에 적용시킨 AnomalyLLM을 제안한다. 이 모델은 pre-trained LLM 기반의 teacher network와 이를 feature를 모방하여 학습한 student network 간의 discrepancy를 test phase에서 계산하여 그 차이가 크면 anomaly라고 예측한다.
하지만 anomaly detection에서 이상의 패턴을 학습하는 문제가 발생할 수 있는데, 이를 방지하기 위해서 논문에서는 두 가지 전략을 고안했다.
1) prototype 신호를 student network에 통합해서 normal feature extraction을 강화한다.
2) 두 네트워크의 차이를 극대화하기 위해서 합성 이상치를 사용한다.
이를 통해 AnomalyLLM은 15개의 데이터셋에서 SOTA를 달성했고, UCR 데이터셋에서 최소 14.5% 정확도 향상을 보였다.
Introduction
Time Series Anomaly Detection (TSAD)는 데이터의 대부분을 차지하는 정상 패턴을 학습해서 이상치를 탐지하는 기술이다. 이는 산업의 fault detection이나 network instrusion detection, health monitering 등에서 중요하게 사용된다.
TSAD의 주요한 과제는 데이터에 annotation이 부족하다는 것이다. 따라서 기존의 연구들은 데이터 대부분이 normal이라고 가정한 후에 unsupervised model을 구축했다. 이러한 방법론들로 one-class classification, density estimation, self-supervised 등에 기반한 모델이 다수 등장했다.
그리고 representation learning의 발전에 힘입어 self-supervised method가 주목받으며 이 분야를 지배했고, reconstruction, forecasting등 다양한 task에서 두각을 나타냈다. 따라서 anomaly detection 분야에서도 normal과 abnormal을 구별할 수 있는 representation map을 학습하는 것이 중요하게 여겨지고 있다.
하지만 representation을 일반화하려면 보통 굉장히 많은 학습 데이터가 필요한데, 이는 앞서 말했던 사용 가능한 데이터가 적다는 시나리오에 막히므로 time series에서의 self-supervised method의 성능에 한계가 있다.
이러한 한계를 극복하기 위해서 knowledge distillation과 LLM을 사용하는 AnomalyLLM이라는 새로운 접근법을 제시한다.
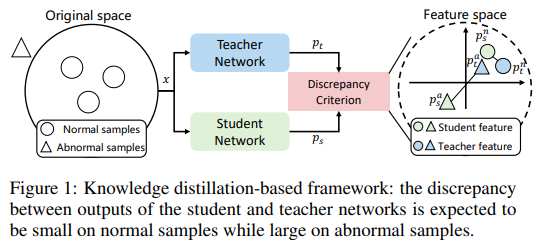
기반이 되는 아이디어는 다음과 같고, Figure 1을 참고하면 된다.
- 대용량 데이터셋으로 사전 학습된 teacher network의 output을 모방하여 student network를 학습
- test phase에서 student network와 teacher network의 output간에 유의미한 discrepancy가 있다면 해당 시점에 이상 발생
이러한 아이디어를 기반으로 모델을 구축하기 위해 논문에서는 2가지 과제에 초점을 맞춘다.
-
어떻게 대용량 데이터셋으로 teacher network를 학습시킬 것인가?
Computer Vision(CV)나 Natural Language Processing(NLP) 분야는 대용량 데이터셋을 통해 representation을 일반화하여 사전 학습한 모델이 이미 존재하며, 각종 task에서 중요한 역할을 한다.
하지만 time series에서는 대용량 데이터셋 구축조차 힘들다(가장 큰 데이터셋이 10GB 미만, CV나 NLP와 비교도 안되게 적음).
따라서 teacher network를 어떻게 사전 학습 시킬지가 관건이다. 최근 연구들은 자연어와 시계열 간의 유사한 특징(sequential 등)에 초점을 맞춰서 pre-trained LLM을 time series represention에 적용하는 시도를 하고 있다. 이렇게 시계열에 fine-tuned된 LLM은 few-shot과 zero-shot에서도 좋은 성능을 나타내며, 이 논문에서도 앞선 연구들에 영감을 받아 pre-trained LLM을 teacher network로 사용한다. -
teacher network에서 나온 'overlearning' representation을 student network가 피할 수 있는 방법이 무엇인가?
논문에서는 기본적으로 student와 teacher network의 output 간의 discrepancy가 normal sample에 대해서는 작고, abnormal sample에 대해서는 크다고 가정한다. 하지만 abnormal sample이 부족한 경우에는 'overlearning' 이라는 문제가 발생한다. 논문에는 자세히 나와있지 않지만 overfitting과 유사한 의미로 쓰이는 것 같다. abnormal sample이 부족하면 student network가 teacher network의 representation을 overlearning할 가능성이 높아지고, 이렇게 되면 discrepancy가 커져야 하는 abnormal에 대해서도 두 network의 representation 간의 차이가 거의 없게 된다. (Figure 1을 보면 이해에 도움됨)
이러한 문제를 방지하기 위해서 논문은 두 가지 해결 방안을 모색했다.
1) student network에 prototypical signal을 통합시켜서 보다 더 근본적인 normal pattern을 표현해낼 수 있도록 한다.
2) data augmentation을 통해 anomaly를 증강하여 network 간의 representation discrepancy를 더욱 크게 한다. 또한, teacher network의 representation은 오리지널과 증강 데이터가 하나의 positive pair로 취급되고, contrastive loss를 적용해서 이 둘을 더욱 가깝게 만든다. 즉, 보다 더 일반적인 패턴을 학습하도록 일종의 정규화 텀으로써의 역할을 한다.
논문에서 제안한 method의 포괄적인 실험 결과는 9개의 univariate dataset과 6개의 multivariate dataset에서 우수한 결과를 나타냈다.
이 논문의 main contribution은 다음과 같다. -
AnomalyLLM은 처음으로 knowledge distillation을 time series anomaly detection에 적용한 논문이다.
-
pre-trained LLM을 적용한 teacher network를 구축함으로써 fine-tuning을 통해 더욱 풍부하고 일반화 가능한 time series representation을 학습할 수 있도록 했다.
-
teacher와 student network간의 discrepancy를 유지하기 위해 student network에 prototypical signal을 통합시키고, data augmentation-based 학습 전략을 채택했다.
-
실험을 통해 15개의 real-world dataset에서 SOTA 성능을 기록했다.
Related Works
2.1 Time Series Anomaly Detection
Time series anomaly detection은 real-world의 다양한 분야에서 적용되며 중요한 역할을 담당한다. 기존의 통계 기반이나 머신러닝 기반의 알고리즘들은 시계열의 복잡한 패턴을 잡아내기가 힘들었다. 따라서 최근에는 variational autoencoder(VAE)나 generative adversarial networks(GAN) 등 수많은 deep learning 기반의 알고리즘을 활용한 anomaly detection method가 등장했다. 이러한 알고리즘들은 이상 탐지의 방법으로 one-class classification, density estimation, self-supervised 등의 방법론을 이용했고, 최근 representation learning의 엄청난 발전으로 self-supervised 기반의 method들이 이 필드를 점령했다.
self-supervised 기반의 method들은 대부분 reconstruction error를 사용해서 이상을 탐지하며 forecasting, imputation, contrastive learning 또한 anomaly를 detection하기 위한 pretext task로 사용된다.
이러한 방법론들이 최근에 SOTA를 달성하긴 했지만, self-supervised 기반 방법론을 사용할 때, 데이터셋 양이 적어지면 representation을 제대로 일반화 시키지 못해서 성능이 현저히 낮아진다는 한계점이 존재한다.
따라서 이 논문에서는 일반화 가능한 time series representation을 생성할 수 있는 pre-trained LLM을 teacher network에 적용하고, 이 network의 output을 모방하여 학습한 student network와 teacher network 간의 discrepancy를 통해 이상을 탐지하는 방법론을 제안한다.
2.2 Large Language Model
NLP나 CV에서 사전 학습 모델이 엄청난 성능 향상을 보여주면서 time series analysis에서도 많은 연구가 있었다. time series에 대한 pre-trained foundation model에 대한 연구가 활발히 이뤄졌지만 사용 가능한 대용량 데이터셋이 부족하다는 근본적인 한계(시계열에서 사용 가능한 가장 큰 데이터셋의 크기가 10GB인데 이는 NLP dataset에 비하면 현저히 적은 양임)가 있었다. 따라서 최근 연구에서는 time series와 national language가 sequential하다는 공통점을 근거로 pre-trained LLM을 time series에 fine-tuning해보기 시작했다. 단순히 pre-trained 됐기 때문에만 사용하는 것이 아니고, 숫자로 이루어진 sequential에 대해서 분포를 유연하게 모델링할 수 있어서 time series로 zero-shot, few-shot task를 풀 수도 있다는 장점이 있다.
이에 따라 forecasting, classification에도 적용되어 우수한 성능을 보였고, 특히, anomaly detection에서도 적용되어 높은 성능을 기록했다. 이에 대한 논문이 GPT4TS인데 GPT2 encoder를 사용하여 encoder-decoder 재구성 아키텍처를 통해 LLM 기반 time series anomaly detection을 수행한 유일한 논문이다.
하지만 사전 학습된 GPT2는 일반화 성능이 매우 뛰어나서 abnormal signal도 일반화 시켜서 재구성 해버리고, 이로 인해 false negative(여기서 false negative는 abnormal을 normal로 잘못 분류한 경우를 말하는 것 같음)가 발생한다.
반면에, 이 논문에서는 GPT4TS와 다르게 student network를 처음부터 학습해서 unseen anomaly를 일반화하지 못하도록 하는 새로운 knowledge distillation 기반의 방법론을 제시한다.
2.3 Knowledge Distillation
knowledge distillation은 student network가 teacher network의 output을 학습하도록 하는 것에 초점을 맞춘다. 이 방법론이 anomaly detection에 처음 사용된 것은 2020년에 vision 분야에서 student와 teacher간의 discrepancy로 이상을 판별하는 연구였다.
이후에도 vision 분야의 anomaly detection에 대해서 이 원리는 널리 사용되었지만 시계열에 적용하는 것은 아직 미개척 분야이다. 이 논문은 이런 점에서 기여도가 있다. 하지만 단순히 vision에서 사용되는 방법론을 그대로 시계열에 적용한 것이 아니라, 시계열이 갖고있는 한계점들을 극복하기 위해서 두 가지 전략을 세웠다.
앞서 설명했듯이, 시계열은 대용량 데이터셋이 없으므로 teacher network 구축이 어려운데, 이를 pre-trained LLM을 통해서 극복하고, student network가 overlearning하는 문제에 대해서는 prototypical signal을 student network에게 상기시키고 data augmentation 기반의 학습 전략을 통해서 극복하고자 한다.
Methodology

위 notation을 기본적으로 알고 가면 된다.
3.1 Overall Architecture
기존 연구들이 그랬듯이 여기서도 마찬가지로 전체 time series를 길이로 고정된 time window로 잘라서 여러 개의 subsequence 를 생성한다.
이 연구는 기존의 knowledge distillation 연구에 토대를 두며, student network는 -> , teacher network는 -> 와 같이 나타내며, 둘 다 D차원의 벡터값을 반환한다.
그리고 두 네트워크의 output은 로 나타낸다.
논문에서는 두 representation간의 차이가 크면 abnormal, 작으면 normal이라고 가정한다. 두 representation간의 차이를 비교하는 수식은 기존 연구 중에 hypersphere classifier loss[수식 (1)]라는 것으로 계산할 수 있다.
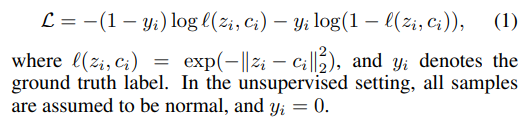
이를 토대로 이 논문의 loss 중에서 knowledge distillation의 두 네트워크 간 discrepancy에 해당하는 부분이 구성되는데 밑에서 더 자세히 다룰 예정이다.
(hypersphere classifier loss? -> 찾아볼 것)
3.2 Prototype-based Student Network
teacher network는 대용량 데이터셋으로 사전 학습 되었기 때문에 일반화 성능이 매우 뛰어나다. 하지만 student network가 teacher network 처럼 과도한 일반화 성능을 갖게되면 두 네트워크 간의 discrepancy를 비교하는 이유가 없어진다. 따라서 논문에서는 prototype을 통해 student network의 학습 방향을 가이드하여 이러한 overlearning 문제를 예방한다.
prototype은 학습 가능한 파라미터이고, 전체 시계열의 특징적인 부분을 나타낸다. 따라서 input time window와 매우 유사한 prototype을 선택해서 representation 출력을 돕는다.
기존에 multivariate time series analysis에서 channel independence가 효율적이라는 것을 시연한 연구가 있었다. 따라서 이 논문에서도 가장 유사한 prototype을 선정할 때 각 channel 단위로 선택한다.

우선, prototype pool을 초기화한다. prototype pool 로 나타낼 수 있고, 이는 i번째 channel에 대해서 각각 길이의 개의 prototype들을 표현한 것이다.
가장 유사한 prototype을 선정하는 수식은 위의 수식 (2) 와 같다. 는 input의 j번째 channel이고, similarity는 코사인 유사도를 사용해서 구한다. 그리고 위 수식으로 선택한 prototype은 로 표현한다.
그리고 input과 prototype 모두 distribution shift를 완화하기 위해서 reversible instance normalization(참고. https://www.youtube.com/watch?v=5nKzGZivW-s)을 활용하고, local의 의미 정보를 추출하기 위해서 시계열을 patching 한다. 이 때, normalizing에서 prototype과 input의 hyperparameter는 동일하다.
다음으로, input과 prototype은 각각 LLM과 transformer에 들어가기 때문에 임베딩을 시켜준다. 임베딩은 패치 내 정보를 추출하는 linear probing과 sequence의 위치 정보를 기록하는 positional embedding으로 구성된다. 이렇게 만들어진 input embedding layer는 input에 대해서 , prototype에 대해서 를 생성한다.
지금까지 계속 prototype 얘기를 했는데, 결론적으로 이걸 써먹는 이유는 original data에 통합시켜서 student network를 학습하기 위함이다. 따라서 transformer에 input과 prototype을 통과시키고, input과 prototype 모두에게서 query와 key값을 도출한다. 그리고 attention score matrix는 다음과 같이 표현된다.
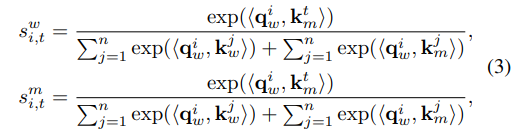
이에 value 값을 곱해서 output값을 도출한다.
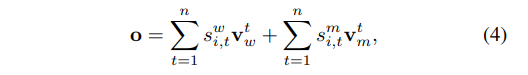
위와 같이 도출된 output을 flatten 시켜서 final representation 를 도출한다.
[내 생각]
각각의 attention score 수식을 살펴봤을 때, , 이 어떤 의미를 갖는지 모르겠음. 둘 다 수식 똑같은데..?
어차피 output을 input과 prototype에서 추출한 value값들과 각각 곱해줘서 구하니까 가시성 높이기 위해서 따로 둔건가 싶음. -> 이게 제일 말이 됨.
3.3 LLM-based Teacher Network
teacher network는 일반화 가능한 representation을 도출해내기 위한 네트워크이다. 기존의 연구에서는 GPT2를 사용해서 일반화 가능한 representation을 도출해냈고, 이 논문에서도 이 부분에 착안해서 teacher network에 pre-trained LLM을 적용했다.
앞서, input을 normalizing과 patching 시킨 후에 임베딩 시킨다고 설명했다. teacher network의 경우에는 LLM이 기본적으로 positional embedding을 지원하기 때문에 linear probing만 진행하면 된다.
또한, student network는 시계열 내의 상관관계를 추출해내기 위해 임베딩을 거치는데, teacher network는 input 시계열을 LLM 이해할 수 있는 표현으로 나타내려는 목적을 가지므로 student network의 embedding layer와 다른 파라미터를 가진다.
다음으로, 전처리된 input은 사전 훈련된 LLM의 positional embedding layer와 self-attention block을 유지하는 network에 들어간다.
이 논문에서는 GPT2를 사용하고, 사전 훈련된 LLM의 기존 knowledge를 보존하기 위해서 sequence modeling의 핵심 요소인 attention layer와 feed-forward layer를 frozen 시킨다. 그리고 positional embedding layer와 layer normalization은 intput time series에 fine-tuned 되어서 LLM이 time series representation을 이해하여 anomaly detection task를 수행할 수 있도록 한다.
마지막으로, self-attention block의 output은 flatten 되어 linear layer를 통과한 후 representation 가 도출된다.
3.4 Model Training
student network와 teacher network의 representation을 통해서 anomaly를 구별하는 것이 논문의 최종 목적이다. 따라서 anomaly label이 부족한 문제를 극복하기 위해 unsupervised setting을 따르고, data augmentation 기반의 학습 전략을 제안한다.
처음으로, 인공적으로 anomaly를 생성하기 위해서 data augmentation을 적용한다. sample의 general pattern이 유의미하게 변하지 않음을 보장하기 위해서 전체 시계열 중 일부분을 랜덤 선택하고, 이 부분들을 augmentation 한다. 이 때, 증강 방법은 jittering, scaling, warping을 사용했다. 이렇게 생성된 샘플에 대해서 original sample이 일 때, 로 표현한다.
다음으로, original과 인공 샘플을 모두 student network와 teacher network에 넣는다. 그리고 각 network를 통과하여 생성된 representation pair에 대해서 original sample은 (), 인공 샘플은 ()로 표현한다. original sample의 representation이 서로 끌어당길 동안 인공 샘플의 representation은 서로 밀어낸다고 한다. 이러한 knowledge distillation loss를 구성하기 위해 아래와 같은 수식을 사용한다. (위에 있었던 수식 (1)과 같은 맥락)
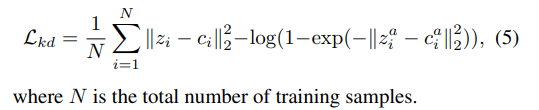
추가적으로, teacher network는 general pattern을 학습하는 데에 초점을 맞추므로 noise에 robust 해야 한다. 따라서 teacher network는 original sample의 representation과 인공 샘플(synthetic sample)의 representation (이 때, 두 representation은 positive pair 이고, 이를 contrastive learning 관점으로 보면 negetive-sample-free contrastive loss로 학습이 가능하다.)간의 거리를 minimize 해야 한다.
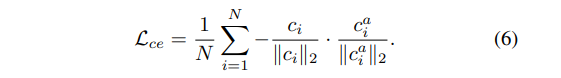
앞서 구한 knowledge distillation loss와 contrastive loss를 합쳐서 최종 loss를 도출하면 다음과 같다.
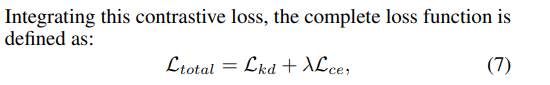
이 때, 는 hyperparameter이고, knowledge distillation loss와 contrastive loss의 weight를 조절하는 역할이다.
마지막으로, test phase에서 anomaly score를 계산해야 하는데, time window 가 주어졌다고 가정하면 아래와 같은 수식으로 구할 수 있다.
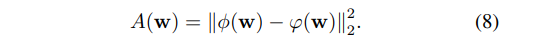
Experiment
4.1 Datasets
UCR dataset은 기존에 사용되던 벤치마크들의 몇 가지 결함을 발견함에 따라 새롭게 소개된 time series anomaly archive이다. 이 archive는 다양한 도메인에 걸쳐있는 250개의 단변량 시계열로 이루어져있다.
UCR archive 중 다음과 같은 9개의 도메인에서 추출된 dataset을 이용했다.

UCR 뿐만 아니라 기존에 주로 이용되는 다변량 벤치마크 데이터셋도 이용했다.

이렇게 총 9개의 단변량 데이터셋, 6개의 다변량 데이터셋, 총 15개의 데이터셋을 사용했다.
4.2 Settings
-
Evaluation Metrics
이상 탐지에서 전통적으로 사용되는 지표는 precision, recall, F1-score를 사용했다. 또한, point adjustment 지표도 최근 많이 사용되고 있다. 하지만 이전에 연구를 보면 이 지표가 모델 성능 과대 평가를 초래한다는 연구 결과가 있다.
이 논문에서는 event-wise 관점에서 affiliation metrics를 사용했다고 하는데, point-wise anomaly detection을 뜻한다고 생각된다. 이 때, metrics에 관해서는 [Alexis Huet, Jose Manuel Navarro, and Dario Rossi. Local evaluation of time series anomaly detection algorithms. In Proceedings of the 28th ACM
SIGKDD Conference on Knowledge Discovery and Data Mining, pages 635–645, 2022.] 이 논문을 참조했다고 한다. (affiliation metrics 공부 필요)
UCR dataset에 대해서는 9개의 각 signal data가 속한 도메인에서 성능이 잘 나오는지를 보기 위해서 accuracy를 추가로 기용했다. -
Hyperparameters
baseline 비교 모델들은 각 모델의 제안 논문에서 기술된 대로 파라미터를 튜닝했다.
이 논문에서 제안한 모델의 경우, teacher network는 GPT2를 기반으로, 6개의 layer를 사용했다고 한다. student network는 32개의 prototypes로 구성된 prototype pool을 사용했고, attention 매커니즘은 차원이 64이고, head 개수를 8개로 설정했다. 학습은 Adam optimizer를 사용했고, learning rate는 0.0001, batch size는 32로 설정했다. 모든 실험은 단일 RTX 3090 GPU로 이뤄졌다. -
Baselines

4.3 Model Comparison
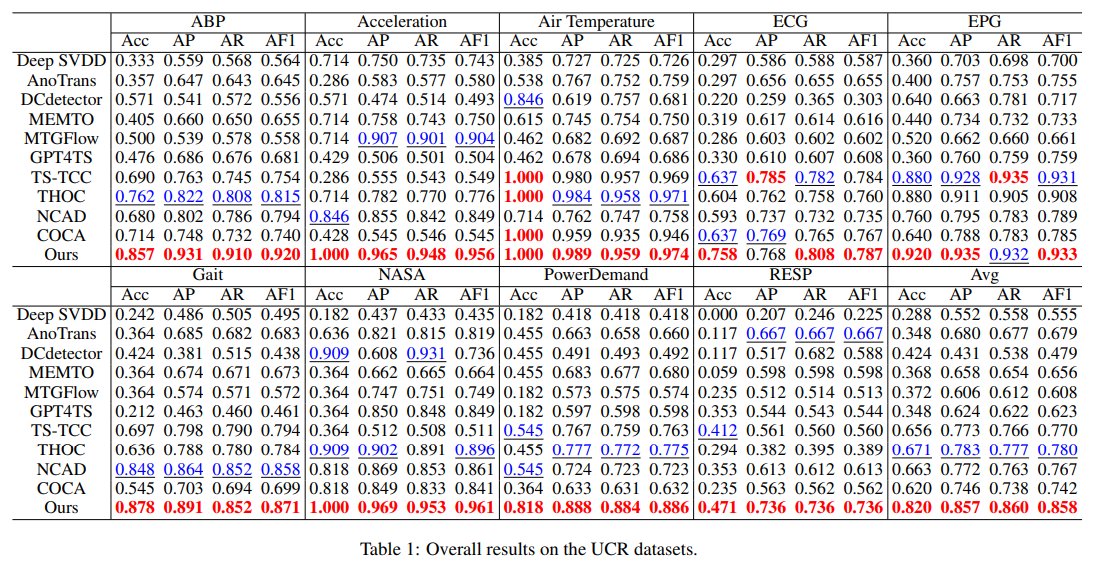
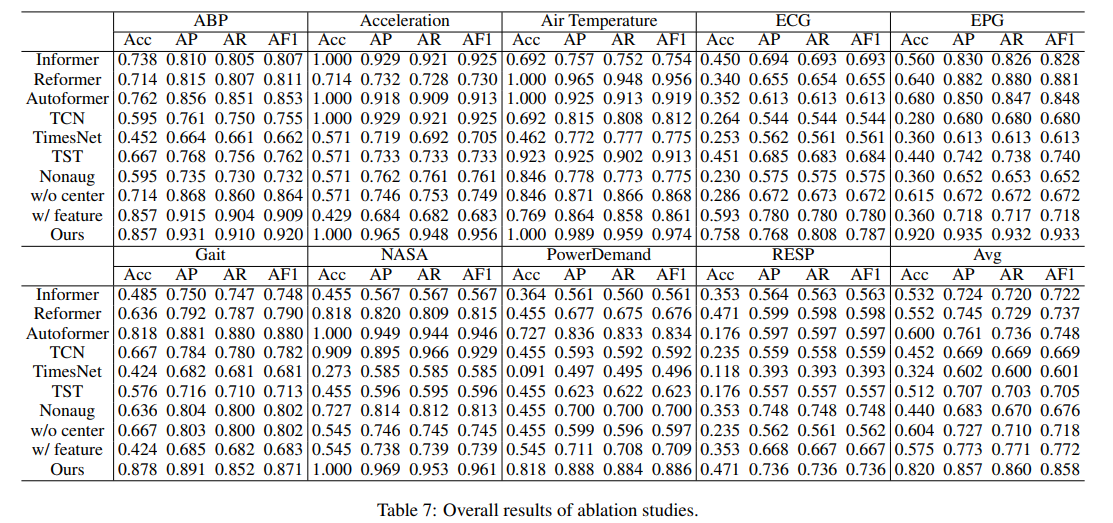
Table 1은 UCR 데이터셋에서 모든 모델의 성능을 보여준다.
논문에서 제안한 모델은 거의 모든 도메인에서 항상 최고의 정확도와 관련 F1 (AF1) 점수를 보여주며, 두 번째로 좋은 방법과 비교하여 정확도가 평균적으로 22.2% 향상했고, AF1에서 10.0%의 향상을 나타낸다. 특히, 총 이상을 감지하는 논문의 방법은 82%를 정확히 감지한다.
세 가지 주요 특징이 있다.
1) 전통적인 DeepSVDD는 만족스러운 성능을 제공하기 어려우나 THOC와 NCAD와 같은 단일 분류 방법은 time window 내에서 시간 정보를 포함할 때 시계열 이상 탐지에서 큰 잠재력을 보인다.
2) 대조적 학습 기반 방법 (TSTCC와 COCA)은 재구성 기반 방법 (AnoTrans, MEMTO)보다 우월한 성능을 보이며, 이는 이상 탐지를 표현 관점에서 접근하는 것이 original signal을 사용하는 것보다 이점이 있다는 것을 시사한다.
3) LLM (GPT4TS)의 직접적인 적용은 기대에 미치지 못한다. 이것은 LLM 기반 오토인코더의 과도한 재구성 능력으로, 비정상적인 시계열까지도 제대로 재구성하여 성능이 나빠지는 것으로 보여진다. 논문의 방법은 과도한 일반화 없이 특징을 추출하기 위해 작은 student network를 도입함으로써 이 제한을 극복한다.
<개인 생각>
-
Acc가 1.000인데 Precision, Recall, F1-score가 어떻게 1보다 작음?
-> affiliation metrics를 우선적으로 알아볼 것 -
위의 질문에 이어서, 기존 모델들이 point adjustment를 사용했기 때문에 성능이 잘 안나왔다는건 알고 있음. 따라서 PA를 제거 했을 때 성능이 많이 떨어진다는 것 또한 이해가 감. 근데 제안된 모델이랑 차이가 너무 많이 남. 이에 더해서 위의 질문처럼 accuracy가 f1보다 높은 경우가 있음.
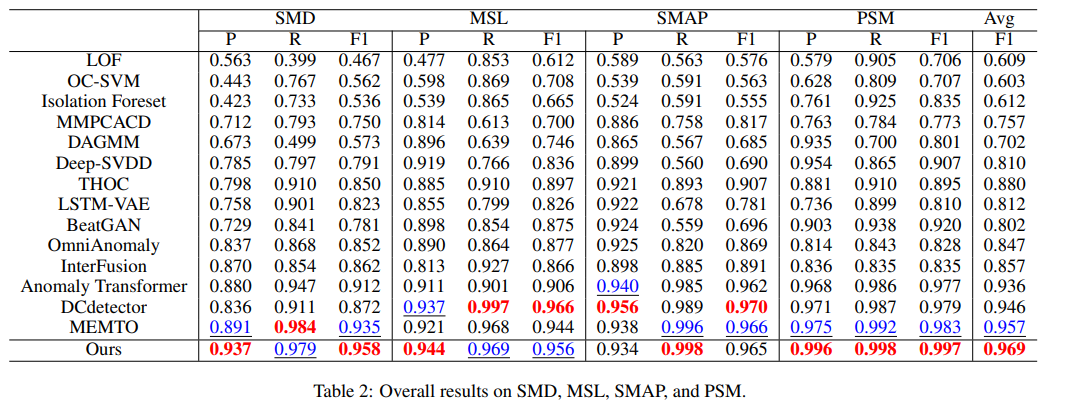

Table 2, Table 3에서 다변량 데이터셋으로 확장한 결과도 제시한다. 이전 방법 대부분은 point adjustment 전략을 적용한 결과를 보여왔다. 앞서 말했듯이 이는 모델의 성능을 과대평가하는 경향이 있지만, 공정한 비교를 위해 Table 2에서 실험에 사용한 데이터셋에 대해서는 point adjustment를 사용한 지표도 포함한다. SMD, MSL, SMAP 및 PSM과 같은 대부분의 데이터셋은 명백한 이상을 포함하며, 논문에서 제시한 모델은 SOTA 모델과 유사한 성능을 보여준다. 다양하고 challenging한 anomaly가 나타나는 NIPS-TS-GECCO 및 NIPS-TS-SWAN의 경우, DCdetector를 크게 능가하여 GECCO에서 47% 대비 62%의 F1 점수 및 SWAN에서 73% 대비 80%의 F1 점수를 달성했다.
<개인 생각>
-
최근에 SOTA라고 나온 모델들은 PA를 사용해서 성능을 평가했었음. Table 2에서 볼 수 있듯이 PA를 적용하면 Table 1과 달리 상당히 높은 성능을 보임.
이 때, 대부분이 Precision보다 Recall이 높음. 즉, window에서 이상 부분을 찾으면 해당 window를 모두 이상이라고 판단해버림. 그러니까 이상을 정상으로 오분류하는 경우는 적고, 정상인데도 이상으로 싹 다 묶어버리는 경우가 많으므로 Precision()은 낮고, Recall()은 높음. -
NIPS benchmark에서는 PA를 안쓰니까 오히려 Precison이 Recall보다 높은 경우가 많이 나타났다. 근데 앞에서 실험에 쓰였던 GPT4TS와 같은 기존 SOTA 모델들 몇 개가 빠진 채 실험을 했는데 그 이유가 뭔지 모르겠다.
4.4 Model Analysis
-
Anomaly score visualization
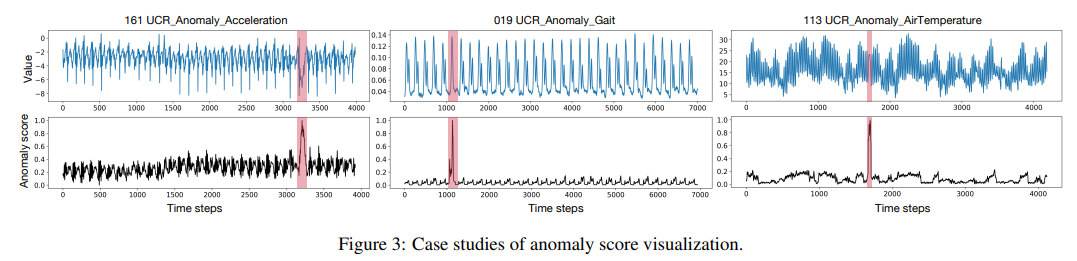
위의 Figure 3은 anomaly score를 시각화 해본 결과이다.
anomaly score는 teacher network와 student network간의 discrepancy로 계산되었고, 시각화 결과를 보면 전체적으로 anomaly score는 일반화 되어있으며 anomaly 발생 시, score가 급격히 튀는 것을 볼 수 있다.
UCR 113 데이터셋의 실제 데이터 형태는 여러 단계를 거치며 평균 값이 달라지는 non-stationary한 특성을 갖는다. 논문에서 제시한 method는 이러한 domain shift에 강건하고, anomaly 부분을 확실히 식별할 수 있음을 알 수 있다. -
Ablation study
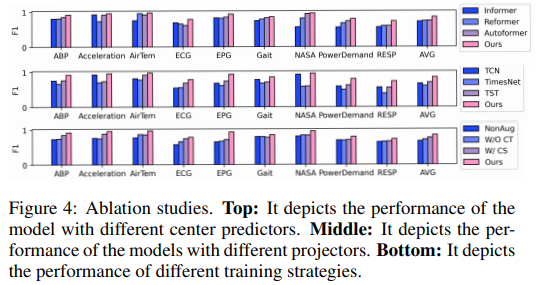
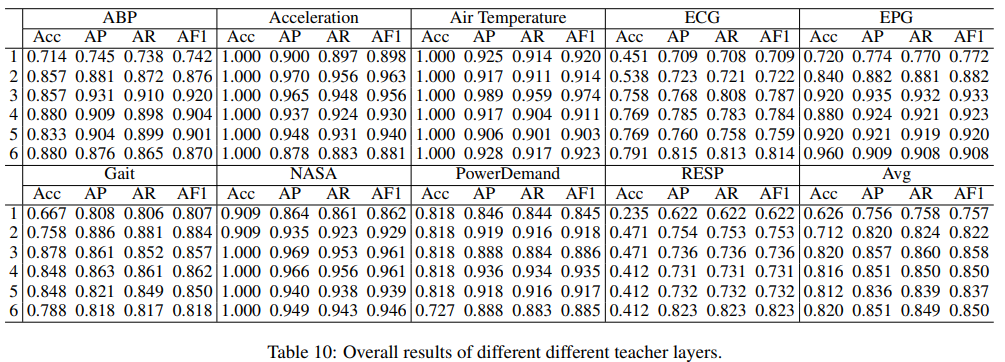
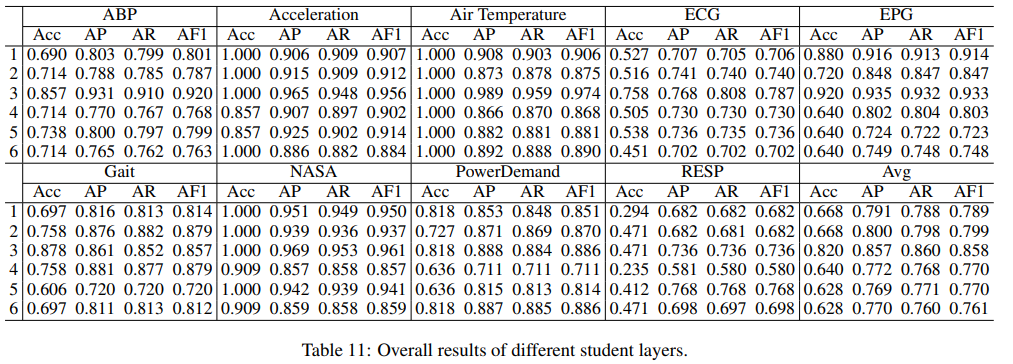
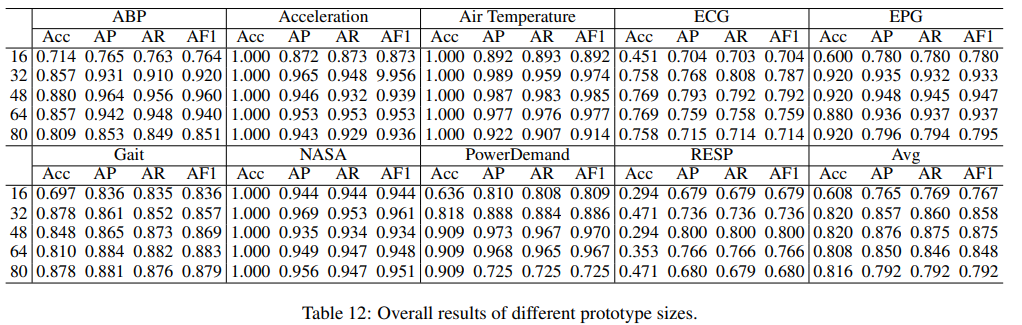
논문에서 제시한 주요 method들이 정확히 어떤 역할을 하는지에 대한 추가 실험을 진행한 결과이다.
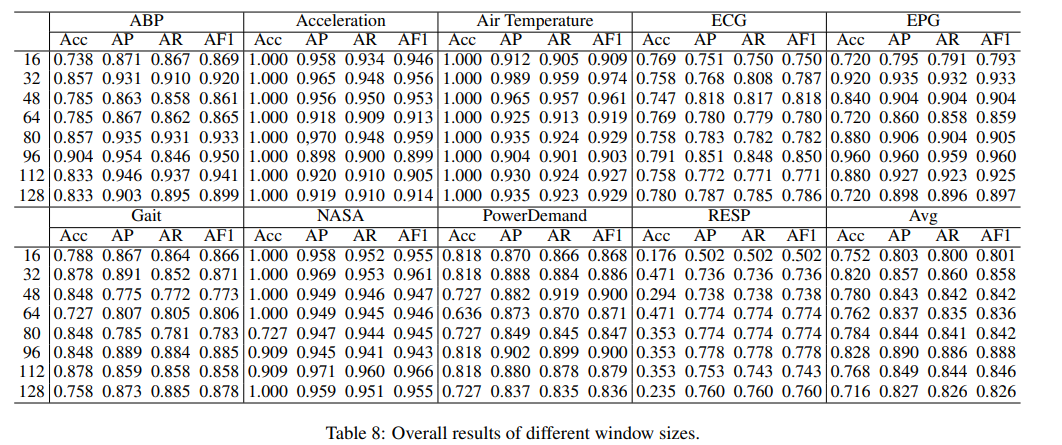
- Parameter Sensitivity


Conclusion
논문의 저자는 이 논문이 TSAD(Time Series Anomaly Detection)에 Knowledge Distillation을 적용한 첫 논문이라고 한다.
Anomaly score는 teacher와 student network간의 representation discrepancy를 통해 구해지고, teacher network는 time series signal sample이 부족한 경우에 pre-trained LLM을 fine-tuning해서 일반화 가능한 representation을 생성한다. student network는 prototypical signal을 통합시켜서 보다 더 domain-specific한 representation을 도출한다. 또한, data augmentation 기반의 학습 전략을 통해 이상치 샘플의 representation gap을 더 크게 한다.
AnomalyLLM은 9개의 univariate dataset에서 SOTA를 달성했고, time series anomaly detection에서 knowledge distillation과 LLM이 잠재력을 갖고 있음을 시사한다.
앞으로의 연구에서는 teacher network를 경량화해서 컴퓨팅 및 메모리 자원의 한계에 대한 탐색이 필요할 것이라고 말한다.
