Tabular Insights, Visual Impacts: Transferring Expertise from Tables to Images
연구 배경
-
현대 AI 모델들은 이미지, 텍스트, 오디오, 동영상 등 다양한 데이터 유형(모달리티) 을 활용하여 학습
-
멀티모달 학습(Multimodal Learning) 은 여러 데이터 유형을 결합하여 성능을 향상시키는 기법
-
하지만 서로 다른 데이터 모달리티는 획득 비용이 다르고, 데이터 유형 간 차이(heterogeneity)가 존재함
-
의료 분야에서 이미지(X-ray, MRI) 는 고가의 장비가 필요하지만, tabular 데이터(환자 기록, 검사 수치 등) 는 전문가 지식을 포함하고 있음
-
기존 연구들은 주로 텍스트-이미지, 오디오-비디오 등의 멀티모달 학습에 초점을 맞추었지만,
- tabular 데이터와 이미지 간의 학습 연구는 부족함
- tabular 데이터는 구조화된 형태(structured format)의 정보를 포함하고 있어 기존 방법들과 차별화된 접근이 필요
CHARMS(CHannel tAbulaR alignment with optiMal tranSport)
CHARMS(CHannel tAbulaR alignment with optiMal tranSport)는 tabular data에서 전문 지식(Expert Knowledge) 을 추출하고 이를 이미지 모델(image model)에 효과적으로 전이(transfer)하는 새로운 방법이다.
tabular -> image
- tabular data에는 구조화된 정보(structured information) 가 포함되어 있음
- 이미지 모델은 시각적 정보(visual features) 를 처리하는 데 최적화됨
- 하지만 기존 멀티모달 학습(Multimodal Learning)은 주로 텍스트-이미지, 오디오-비디오 조합에 집중됨
- tabular data를 보조 정보(auxiliary knowledge) 로 활용하여 이미지 모델이 더 강력한 예측 성능을 갖도록 하는 것이 목표
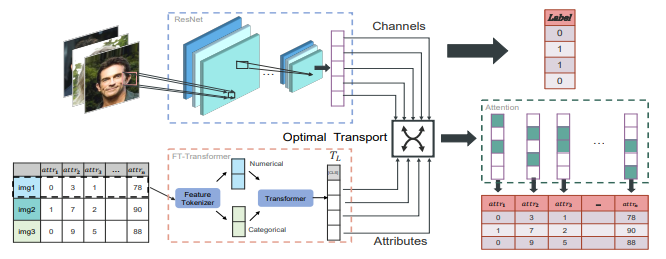
CHARMS는 크게 3단계로 이루어진다:
- 샘플 간 유사도(Sample-wise Similarity) 계산
표 형식 데이터의 속성(attribute)과 이미지의 특성(feature)이 직접적으로 매칭되지 않음
따라서, 개별 속성(attribute)과 개별 이미지 채널(channel) 간의 직접적인 대응 관계를 설정하는 대신, 샘플 간 유사도를 이용
이를 통해, 표 데이터와 이미지 특징(feature map) 간의 관계를 간접적으로 파악
✔ 샘플 간 유사도 정의
표 형식 데이터에서는 유사한 속성을 가진 샘플들이 비슷한 레이블을 가질 가능성이 높음
이를 활용하여,
표 데이터에서 각 샘플 간 유사도를 계산하고,
해당 유사도가 이미지 모델에서도 유지되도록 정렬함
✔ 유사도 계산 방법
표 데이터에서는 L2 거리(Euclidean distance) 또는 코사인 유사도(Cosine similarity) 를 사용하여 샘플 간 유사도를 측정
이미지에서는 CNN(ResNet 등의 backbone)을 활용하여 feature embedding을 추출하고, 유사한 샘플들이 유사한 이미지 feature를 갖도록 유도
- 최적 수송(Optimal Transport, OT) 기반 정렬
표 데이터와 이미지 데이터를 직접 결합하는 것은 어렵기 때문에, 각 속성을 이미지 모델의 특정 채널과 정렬하는 방식으로 접근
Optimal Transport(OT) 이론을 사용하여 표 데이터의 속성과 이미지 채널 간의 최적의 대응 관계(cost matrix)를 학습
✔ 최적 수송(Optimal Transport, OT) 개념
OT는 두 개의 확률 분포(P, Q) 간의 최적 매핑(mapping)을 찾는 기법
여기서,
P: 표 형식 데이터의 속성(attribute)
Q: 이미지 데이터의 채널(channel)
두 데이터 간의 "비용 함수(cost function)"를 설정하고, 최소 비용으로 정렬하는 매핑을 학습
✔ OT를 통한 채널 정렬 과정
1️⃣ 표 데이터의 속성을 확률 분포로 변환
각 표 속성(attribute)을 확률 분포 형태로 변환
예: 속성 값들을 정규화(normalization)하여 확률 값으로 표현
2️⃣ 이미지 모델의 채널을 확률 분포로 변환
이미지 CNN 모델에서 각 채널의 활성화 값(activation values)을 확률 형태로 변환
이를 통해 표 속성과 이미지 채널 간의 비교 가능성 확보
3️⃣ OT 기반 비용 함수(cost function) 계산
두 확률 분포(P, Q) 간의 "수송 비용(transport cost)"을 최적화
이 과정에서 각 속성(attribute)이 이미지 모델의 어느 채널(channel)과 가장 관련이 있는지를 학습
4️⃣ 채널-속성 매핑을 활용하여 이미지 모델 학습
표 형식 속성과 매칭된 이미지 채널을 활용하여 표 데이터 없이도 더 나은 이미지 예측이 가능하도록 설계
- 특성 유형별 정렬 방식
표 형식 데이터에는 두 가지 주요 특성 유형이 존재하며, CHARMS는 각 유형에 맞는 방식으로 정렬을 수행한다.
✔ 숫자형 특성(Numerical Features)
연속적인 수치 값을 가지므로, MSE(Mean Squared Error) 손실을 사용하여 정렬
각 숫자형 속성이 특정 이미지 채널과 연결될 수 있도록 최적화
✔ 범주형 특성(Categorical Features)
여러 개의 고유한 클래스를 가지므로, 교차 엔트로피(Cross-Entropy) 손실을 사용하여 정렬
예: 성별(남성/여성), 카테고리(고양이/강아지 등) 같은 데이터는 원-핫 인코딩 후 처리
실험 결과
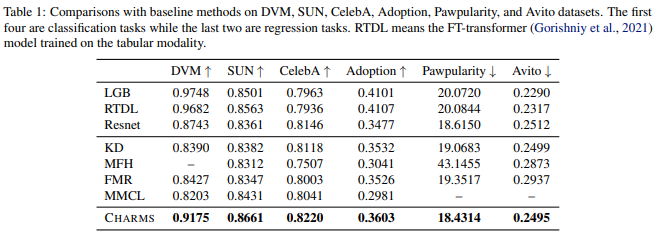

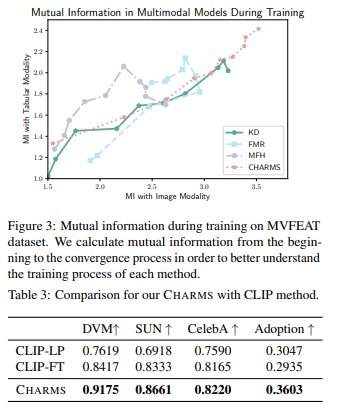
CHARMS는 표 데이터 없이도, 표 데이터를 활용한 모델과 비슷한 수준의 성능을 달성
ResNet(이미지 전용 모델)보다 훨씬 높은 성능을 기록
특히, DVM, Adoption과 같이 표 데이터의 정보력이 강한 데이터셋에서 뛰어난 성능을 보임
SUNAttribute, CelebA와 같이 이미지 자체의 정보가 중요한 데이터셋에서도 성능이 유지됨
CHARMS는 기존 크로스모달 학습 방법들보다 높은 성능을 기록
특히 DVM과 같은 데이터셋에서는 Knowledge Distillation(KD)보다 2%p 높은 정확도
Pawpularity(회귀 문제)에서는 RMSE가 기존 방법과 동일하지만, 표 데이터 없이 달성된 결과라는 점에서 의미 있음
