time-series representation/preprocessing
RevIN(Reversible Instance Normalization)
[Kim, T., Kim, J., Tae, Y., Park, C., Choi, J. H., & Choo, J. (2021, May). Reversible instance normalization for accurate time-series forecasting against distribution shift. In International Conference on Learning Representations.]
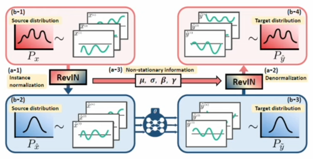
시계열 데이터는 일정한 분포를 가지는 경우도 있지만, 대체로 시간 변화에 따라 분포가 변화함(Non-stationary).
이러한 분포 차이는 Train 및 Test data 사이와 Lookback window 및 forecasting horizon에서 발생함. 이는 결국 forecasting 모델이 잘 generalization 되지 않는 결과를 초래함.
RevIN은 Symmetric한 구조로, Input Sequence에 대하여 Normalize를 진행하여 도출된 Original Distribution Information과 Scale과 Shift를 조정하는 learnable parameter를 바탕으로 Output Sequence에서 다시 De-normalize 진행.
Multi-scale Encoder
[Zheng, X., Chen, X., Schürch, M., Mollaysa, A., Allam, A., & Krauthammer, M. (2023). SimTS: rethinking contrastive representation learning for time series forecasting. arXiv preprint arXiv:2303.18205.]
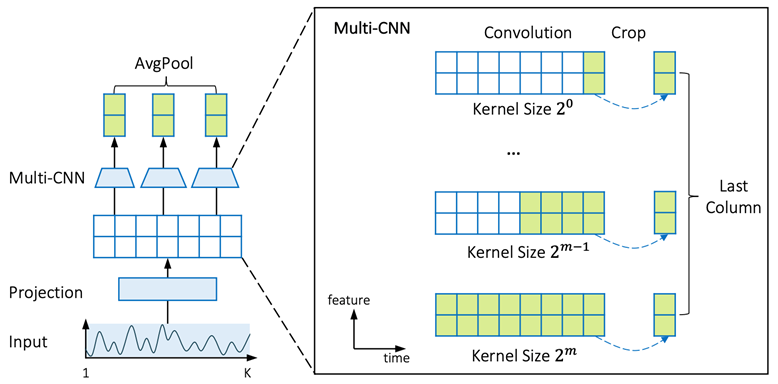
1D CNN은 주로 시계열과 같은 시퀀스 데이터를 처리하는데 사용되며, 한 방향으로만 움직이면서 합성곱 연산을 수행함.
위의 Multi-scale Encoder는 다양한 커널 크기를 가지는 다중 필터를 사용해서 합성곱 신경망을 구성함. 이를 통해 시계열 데이터의 global, local 패턴을 모두 추출할 수 있음.
[동작과정]
인코더 의 동작 과정은 아래와 같음.
1) 시계열 입력은 합성곱 projection층을 통과해서 시계열 데이터를 잠재 공간으로 투영할 수 있게 함
- 드러나지 않은 추상적인 정보와 시간 내 관계를 학습하여 표현 가능
2) 길이가 인 시계열에 대해, 다양한 커널의 합성곱 층을 통과시킴
- 개의 병렬 합성곱 층을 사용
- 번째 합성곱 커널 크기는 이고,
3) 각 합성곱 층은 표현 벡터 를 생성하고, 최종적으로 multi-scale encoder가 도출한 표현 는 을 global average pooling을 통해 얻어짐
Soft Contrastive Learning
[Lee, S., Park, T., & Lee, K. (2023). Soft Contrastive Learning for Time Series. arXiv preprint arXiv:2312.16424.]
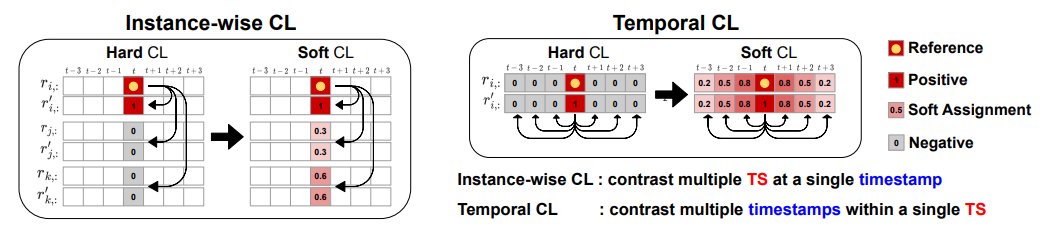
기존 Hard CL(Contrastive Learning)의 경우, positive는 1, negative는 0으로 판별했음.
반면, Soft CL의 경우, 시계열 특성을 반영하여 유사도를 측정하고, 보다 더 풍부한 정보(세밀한 정보)를 학습할 수 있도록 유도함.
- downstream task는 multi-task로 가져갈 수 있음
- RUL과 같이 지속적으로 degradation이 발생하는 경우에는 데이터 변화를 tracking할 수 있는 soft CL 방법론이 어울리지 않을까 생각함.