Improving Language Understanding by Generative Pre-Training
Abstract
자연어 이해(Natural Language Understanding)은 텍스트 추론, 질의 응답, 의미 유사도 파악, 문서 분류 등 굉장히 다양하고 중요한 task들로 구성되어 있다.
그러나 이러한 task들에 대해서 난항을 겪고 있는데, 그 이유들 중 대표적인 것이 unlabeled text corpora는 풍부하지만 labeled data는 부족하다는 현실적인 문제 때문이다.
이 논문의 핵심적인 아이디어는 이러한 문제에 기반하여 다양한 unlabeled text corpus에 대해서 언어 모델로 generative pre-training과 각 특정한 task들마다 discriminative fine-tuning을 거친다면 많은 정보를 얻을 수 있다는 것이다.
기존 접근법들과 다르게, 이 GPT는 모델을 최소한만 변형하고, task를 인식할 수 있도록 input을 변형하여 fine-tuning 과정에서 전이 학습을 효율적으로 할 수 있는 방법론이다.
이를 통해 NLU task를 위한 다양한 benchmark에서 기존 모델들의 성능을 개선했다. 이로써 우리가 매우 잘 아는 엄청난 성능을 자랑하는 GPT의 초석이 다져진 것이다.
Introduction
NLP task에 있어서 raw text로 부터 의미있는 정보를 학습하는 것은 매우 중요하다. 기존 DNN 방법론을 통해 텍스트를 분석할 때에는 hand craft labeled data가 필요했지만, 현실에는 지도학습보다 비지도학습에 해당하는 unlabeled data가 훨씬 많다. 이에 따라서 unlabeled text에 대한 의미 정보를 파악할 수 있다면 text에 주석을 다는 비용을 대폭 줄일 수 있으므로 상당히 의미있는 연구이다.
또한, 비지도학습에서 의미있는 정보를 잘 학습할 수 있다면 기존의 지도학습 기반 모델의 성능 향상에도 유의미한 영향을 줄 수 있다. 이를 위해서 그 동안은 주로 pre-trained word embedding을 사용하여 성능 향상을 이뤄낸 연구들이 많았었다.
하지만 단순 단어 수준 이상의 정보를 unlabeled text에서 추출하는건 두 가지 큰 이유 때문에 어려움이 있었다.
첫 째로, text representation을 학습할 때 어떤 optimization이 가장 효율적인지 불분명했다는 점이다. 전이 학습에 있어서 데이터를 latent space에 잘 나타내는 것은 매우 중요하고, 이를 위해 필요한 것이 표현 학습이다.
language modeling, machine translation, discourse coherence와 같이 다양한 작업들이 뛰어난 성능을 가질 수 있었던 이유가 바로 그 때문이다.
둘 째로, 표현 학습이 잘 됐다고 가정하더라도 어떤게 가장 효율적인 transfer 방법인지에 대한 확답을 내릴 수 없었다는 점이다.
당시 존재했던 방법론들 또한 라벨 부족 현상을 극복하고 모델의 예측 성능을 높이기 위해서 다양한 시도를 했지만, 이는 달리 말하면 하나로 정립된 방법론이 없었다는 것이다.
이러한 불확실성 때문에 language processing에서 semi-supervised learning을 진행하는데 어려움이 있었다.
그래서 이 논문에서 하고 싶은건 unsupervised pre-training과 supervised fine-tuning을 섞어서 semi-supervised approach로 텍스트 이해를 하겠다는 것이다.
즉, 만능 representation을 학습한다면 전이 학습에서 약간만 adaptation해도 광범위한 task에 대해서 동작이 가능하다는 것이다.
이를 위해서 대용량의 unlabeled corpus와 target task의 labeled training data가 필요하다. (이 때, target task의 도메인이 unlabeled corpus와 같을 필요는 없음.)
이러한 base가 깔렸다면, two-stage training procedure를 따른다.
- neural network의 initial parameter를 학습시키기 위해서 unlabeled data에 language modeling objective를 적용하여 학습
- 학습한 파라미터를 target task에 supervised objective를 사용해서 adaptation
(여기서 language modeling objective는 말 그대로 언어 모델링의 목표를 뜻하는 것 같음.
즉, unlabeled data로 이전 단어를 학습해서 다음 단어를 예측하는 방식으로 학습을 진행하여 파라미터를 업데이트
target task에서는 task-specific한 objective에 대해서 supervised learning 방법론으로 fine-tuning)
GPT는 기본적으로 Transformer architecture를 사용한다. (흔히 Transformer의 Decoder 부분을 쌓아 올렸다고 알려져있음)
Transformer는 long-term dependencies를 제어하기 위해서 structured memory를 제공할 수 있고, 이 구조는 다양한 task에 transfer하기 용이하다.
Transfer, 즉, fine-tuning할 때에는 traversal-style approach를 기반으로 하는 task-specific input adaptations를 사용한다.
이 approach는 structured text input을 하나의 contiguous sequence of tokens로 만들게 되고, 이를 통해서 모델을 최소한만 변형하더라도 효과적인 성능을 얻을 수 있게 된다고 한다.
- Traversal-style approch?
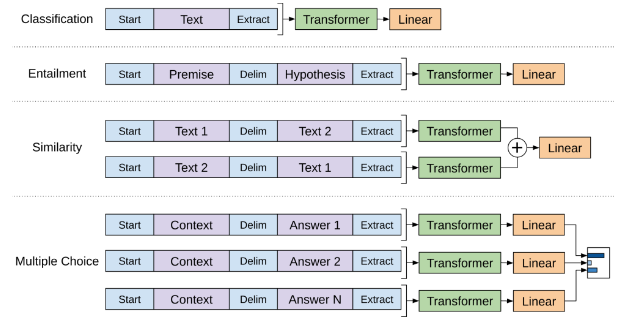
아래 그림과 같이 다양한 task의 입력을 start token, delimiter(문장 구분 토큰), end token(Extract)으로 이루어지도록 한다.
이를 통해서 모델을 조금만 변형하더라도 다양한 task에 transfer하기 용이해진다는 것이다.
Related Work
Semi-supervised learning for NLP
기존 연구에서도 대용량 Unlabeled corpus를 사용하려는 시도가 많이 존재했다.
예를 들면, 대규모 말뭉치의 통계값을 이용하고 훈련된 임베딩 벡터를 이용하려는 시도가 있었다. 이러한 방법들은 분명 효과가 있었지만 단어 수준의 관계밖에 캡쳐하지 못했고, 이 논문에서 가져가고자 하는 기여점은 단어 수준 이상의 의미 파악이기 때문에 기존의 방법론을 사용하기엔 한계가 존재한다.
Unsupervised pre-training
Unsupervised Learning은 Semi-supervised Learning의 특별한 경우라고 생각할 수 있다.
따라서 Unsupervised pre-training의 목적은 이 후 수행될 supervsied learning에 좋은 초기화 포인트를 제공하는 것이다.
이전에는 이미지 분류, 회귀 문제 등에 이 방법이 사용됐었지만, 후속 연구에서 Pre-training 기법은 정규화 작용을 하여 딥러닝 모델을 더 잘 일반화할 수 있다는 것이 밝혀졌다.
따라서, 최근의 연구에서 이 기법은 이미지 분류, 발언 인식, 기계 번역 등의 다양한 task에서 딥러닝 모델이 더 잘 훈련될 수 있게 하기 위해 사용되었다.
하지만 기존의 NLP 연구에서는 LSTM을 사용한 연구가 대부분이었고, 이는 예측 범위가 짧기 때문에 long-term에 취약하다.
반면, transformer 구조는 더 긴 길이의 언어적인 구조를 포착할 수 있으므로 generative pre-training 방법은 transfer할 때, 아주 작은 변화만을 필요로 할 수 있게 된다.
Auxiliary training objectives
추가적인 sub objective function을 사용하는 연구 또한 기존에 존재했다.
보통 unsupervised training objective를 추가해서 semi-supervised learning 형태를 만드는 방식으로 진행되었다. (POS tagging, chunking, named entity recognition 등 다양한 NLP task를 추가적으로 수행하여 data의 semantic information을 잘 학습할 수 있도록 유도함) -> self-supervised와 비슷?
이 논문에서도 auxiliary objective를 사용하지만, 기존처럼 굳이 semi-supervised form을 따르지 않아도 unsupervised pre-training 작업만으로 이미 target task와 관련있는 언어적 특성을 충분히 학습했다는 것 또한 실험을 통해 보여준다.
Framework
Training 과정은 앞에서 언급했던 것과 동일하게, 간단한 two-phase로 진행된다.
- 대용량 unlabeled text data로 high-capacity language model을 학습
- labeled data(target data)를 통해서 task specific하게 fine-tuning
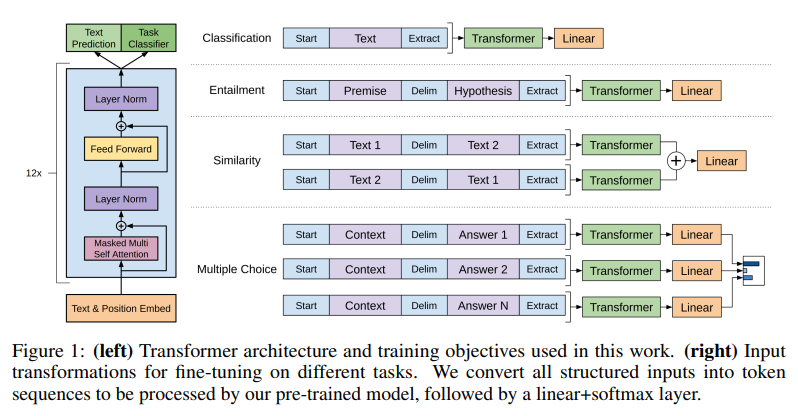
위 그림은 GPT의 전체적인 framework를 나타내는 architecture이다.
단순하면서 강력한 성능을 낸다는 점이 눈여겨 볼 점이다.
Unsupervised pre-training
Unlabeled token corpus 이 주어졌을 때, 아래 수식과 같이 likelihood를 최대화 하기 위한 standard language modeling objective를 사용한다.
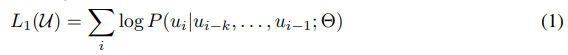
여기서 는 context window size, 는 neural net의 조건부 확률, 는 neural net의 파라미터이다.
이 때, 파라미터는 SGD optimizer로 업데이트된다.
수식을 해석해보면, 이전 단어들(부터 )을 보고, 다음 단어를 라고 예측할 확률이 높아지도록 parameter()를 학습하는 방식이다.
그리고 앞에서 언급했듯이 GPT는 기존의 encoder-decoder 구조의 Transformer에서 decoder만 사용했다.
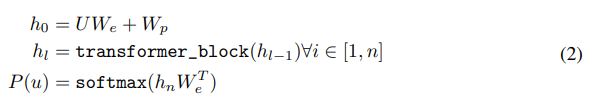
위 수식에서, 는 토큰들이 압축된 context vector이고, 은 레이어 개수, 는 token embedding matrix, 는 position embedding matrix를 뜻한다.
기존의 transformer 구조는 기계 번역에 특화된 모델인 만큼 encoder에서 압축된 sequence 정보를 decoder에 넣어서 task를 수행했지만, GPT는 다음 단어 예측, 즉, '생성'에 초점이 맞춰져 있기 때문에 encoder에서 key와 value를 받아올 이유가 없다.
따라서 text & position embedding 이후에 Masked MSA를 거치고 바로 FFNN으로 넘어간다.
Supervised Fine-tuning
fine-tuning 과정 또한 굉장히 간단하다.
우선 labeled dataset 를 가정하고, input token 이 입력됐을 때, label 가 주어진다.
앞에서 pre-trained된 모델을 통과하면 마지막 transformer block에서 을 얻을 수 있고, feed forward를 거쳐서 를 predict하는 과정은 아래 수식과 같다.
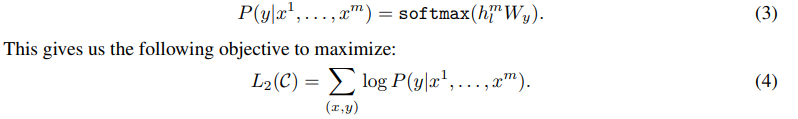
수식 (3)에서 얻은 조건부 확률에 log를 취해서 objective function을 구축(수식 (4))하고, fine-tuning은 이를 maximize 하는 방향으로 학습된다.
추가적으로, 앞에서 서술했듯이 auxiliary objective function을 통해 모델의 성능을 더 높일 수 있다.
따라서,
- supervised model의 generalization ability를 향상시키고
- convergence를 가속화시키기 위해
fine-tuning 할 때, auxiliary objective function을 추가해서 사용했다.

위와 같이 기존의 unsupervised learning에 사용했던 loss function 을 추가해서 supervised, unsupervised learning task 모두를 잘할 수 있도록 한다. (는 weight parameter)
Task-specific input transformations
Text classification같은 task의 경우, 위의 방법 그대로 fine-tuning이 가능하다. (기본적인 base model에서도 가능)
하지만 QA, textual entailment와 같이 구조적으로 다른 task의 경우에는 해당 task에 필요한 고유의 input structure를 필요로 한다.
기존 연구들의 경우, 이에 맞춰서 모델의 구조를 변형시켰고, 이 과정에서 많은 cost를 유발한다.
GPT는 이러한 문제를 해결하기 위해서 traversal-style approach를 사용한다.
해당 방법은 structured input을 unsupervised learning을 통해 pre-trained model에 process할 수 있도록 하나의 ordered sequence로 바꾼다.
즉, 아래와 같이 모든 task에 대해 input transformation은 랜덤하게 initialized start, end token (<>,<>)을 포함한다.
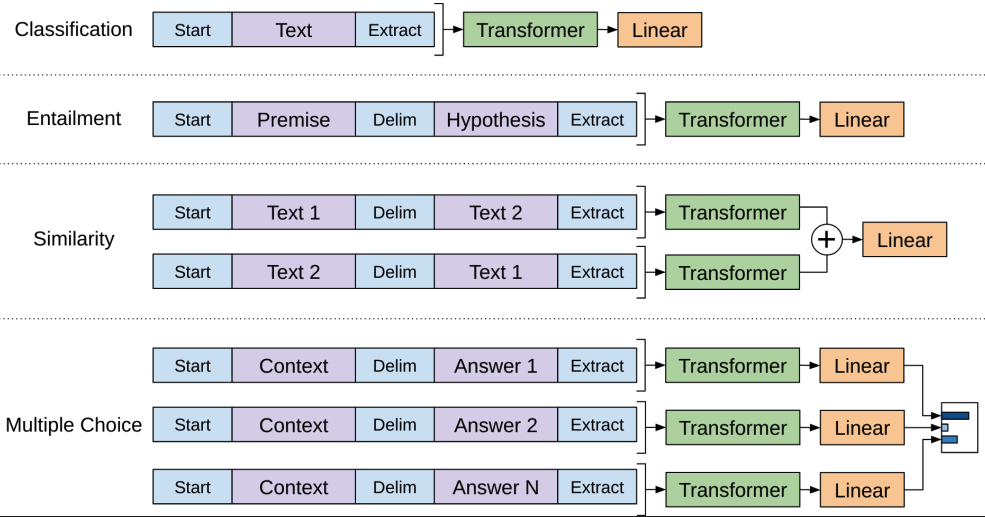
- Textual Entailment
위 그림과 같이 premise 와 hypothesis token sequence들을 concat한다. 두 token을 구별하기 위해서 delimiter(구분자) token $를 사용한다.
- Similarity
해당 task에서는 두 문장 사이에 가능한 ordering 모두를 고려해서 input transformation하여 두 개의 input을 만들고, 각각 독립적으로 transformer를 통과하여 output represenatation 을 도출한다.
그리고 각 representation들을 element-wise하게 add하고 linear output layer를 거쳐서 최종 결과를 얻는다.
이 task 또한 delimiter를 통해 하나의 ordered sequence내의 text를 구별한다.
- Question Answering (QA)
Document , Question , 가능한 answer set 가 주어질 떄, document context와 question을 묶고, delimiter token을 이용해서 answer와 concat한다.
즉, 형태의 여러 개의 input을 만든다.
각 input ssentence는 독립적으로 model을 거친 다음 softmax를 통해 normalize된 output distribution을 얻고, 이를 통해서 가장 높은 확률의 answer를 최종 결과로 도출한다.
Experiments
Setup
Unsupervised pre-training
GPT는 어드벤처, 판타지, 로맨스 등의 다양한 장르가 섞인 7,000개의 독립된 unpublished book 데이터가 담긴 BooksCorpus dataset을 사용했다.
이 데이터셋은 책 내용으로 구성된 만큼 long-range information을 학습하기에 용이하므로 GPT로 보이고자 했던 long-term에 대한 성능을 충분히 보여줄 수 있는 데이터셋이다.
이 데이터셋의 대안으로는 1B Word Benchmark가 있는데, 기존 연구 중에서 ELMo가 해당 데이터셋을 사용했다. (ELMo 또한 GPT와 비슷한 기여점을 가져감. Unlabeled dataset에 대해서 잘 작동하는 모델을 만들겠다!)
그러나 ELMo는 sentence level에서 데이터셋을 셔플했기 때문에 long-range 구조가 망가진데에 반해, GPT는 token level에서 perplexity가 18.4밖에 안되므로 데이터셋의 구조를 거의 흐트러뜨리지 않고 학습했다. (근데 perplexity scoring은 어떻게 했는지 모름.)
Model specification
