(추후 수정)
학습 계기
학교 포털 홈페이지에 우연히 챗봇이 있는것을 알게되었고, 사용해보았을 때 미흡한 부분이 있지만 꽤 쓸만한 정보를 알려주는 것을 보고 관심을 가지게 되었다.
요즘 AI 시대라고 하는데 LLM, LangChain, RAG 단어를 들어만봤지 무슨 뜻인지 제대로 알지 못했기에 이번 기회에 무엇인지 제대로 알고, 조금이나마 활용해 보기 위해 강의를 듣게 되었다.
강의 선정 및 목적
인프런 강의 중 RAG를 활용한 LLM Application 개발 (feat. LangChain)
강의를 골라서 수강하게 되었다.
선정이유는 RAG, LLM, LangChain에 대한 설명과 간단한 챗봇을 만드는 프로잭트가 포함되었기에 이 강의를 선정하여 듣게 되었다.
강의에 관하여...
일단 강의에서 필요한 내용은 모두 수강하였다. (부록 제외)
기본적인 RAG, LLM 등을 이해할 수 있었고, 강의에서 진행한 간단한 챗봇 만들기 프로잭트도 진행하였다.
완성 코드 ⬇️
강의 수강 이후
RAG, LLM, Langchain에 대한 지식을 얻었다
챗봇 만들기를 진행하였는데, 강의에서 배운 것을 참고하여 추후 다른 내용의 챗봇을 만들어 볼 수 있을 것 같다.
(강의에서 진행 한 것은 소득세 관련 챗봇이며, 강의 코드 자료와 gpt 등의 AI를 사용한다면 가능해보인다)
🖥️ 사용한 기술 스택
챗봇 프로젝트 기술 스택
프로젝트에 다음과 같은 기술 스택을 사용
-
VS Code
개발 환경으로 Visual Studio Code를 사용 -
Jupyter Notebook (VS Code 내에서)
데이터 분석과 모델 훈련을 위해 Jupyter Notebook을 VS Code 내에서 사용
-
Streamlit
사용자와 상호작용할 수 있는 웹 애플리케이션을 만들기 위해 Streamlit을 사용
간단한 코드로 빠르게 웹 앱을 개발할 수 있어 챗봇의 UI 구현에 적합 -
RAG (Retrieval-Augmented Generation)
챗봇의 질 높은 답변 생성을 위해 RAG 기법을 사용
외부 지식 베이스에서 정보를 검색하여 답변에 반영하는 방식을 활용
(소득세 관련 문서를 word 파일로 다운받아 사용) -
LLM (Large Language Model)
LLM을 활용하여 자연어 처리 및 생성 작업을 수행
챗봇이 사용자와 자연스러운 대화를 할 수 있도록 돕는 핵심 기술 -
LangChain
LangChain은 복잡한 언어 모델을 활용한 파이프라인을 구축하기 위한 라이브러리
여러 데이터 소스를 연결하고, 다양한 작업을 처리하는 데 유용하게 사용 -
Upstage Console
Upstage Console을 사용하여 챗봇의 상태와 성능을 모니터링하고 관리하는 데 활용
강의에서는 OpenAI 모델을 사용하였는데 비용이 발생하여, 회원가입시 10달러 정도 무료로 이용가능한 Upstage Console 사용
RAG
Retrieval Augmented Generation (RAG)
-> 검색 - 증강 - 생성
R (Retrieval) 검색
- 데이터를 가져오는 것
- 언어모델이 가지고 있지 않은 정보를 가져오는 것
(언어모델이 답변 생성을 위한 모든 정보를 가지고 있지는 않음)
A (Augmented) 증강
- 마치 사실인 것 처럼
- 검색(Retrieval)된 데이터를 LLM에 주면서 -> 마치 이 정보를 아는 것 처럼 사용
G (Generation) 생성
- 가져온 데이터를 제공 -> 이 정보를 아는 것 처럼 해서 -> 답변을 생성
쉽게 정리하면 자료를 가져와서 주면 -> 마치 사실인 것 처럼(알고 있는 것처럼) -> 답변 생성
내가 해야 하는 일
사용자의 질문에 답변을 생성해주는 것은 LLM이 하는 일이다.
개발자는 데이터를 잘 가져와서 (검색) -> LLM에게 잘 전달해야 한다.
- 데이터를 잘 가져오려면 -> 잘 저장해야함
- 데이터를 잘 전달하려면 -> 프롬프트 잘 활용해야함, 문맥 제공도 중요
Vector Database
질문을 한다고 가정하면 그 질문과 관련있는 데이터가 어떻게 관련이 있다고 판단하는가?
이럴 때 유사도 검색을 사용한다.
관련성 파악을 위해 vector를 활용한다.
- 단어나 문장의 유사도를 파악해서 관련성 측정
유사도 검색이란?
- 두 개의 Vector가 얼마나 “가까운지” 를 계산하는 방법
- Encledian : 두 Vector 사이의 거리를 재는 것
Vector
- 텍스트를 수학적으로 변경한 상태
Vector를 생성하는 방법
Embedding 모델을 활용해서 vector를 생성
- Emdedding : 텍스트를 Vector로 변경하는 방법
Vector Database
- Vector Database : Embedding을 통해 생성된 Vector를 저장하는 데이터베이스
- vector 저장시 metadata도 같이 저장 (출처, 설명서 역할: 문서의 이름, 페이지 번호 등)
이후 vector 대상으로 유사도 검색을 실시한다.
- 사용자가 입력한 질문과 문서에 있는 내용 중 가장 비슷한 것을 가져오기 위해서
이때 문서 전체를 통체로 유사도 검색을 실시하면 속도도 느려지고, 토큰수를 초과해서 에러가 발생한다. (참고로 한글이 토큰수를 영어보다 많이 사용한다.)
chunking (쪼개서 저장, 나눠서 저장)
그래서 쪼개서 저장하는 것이 매우 중요한다. 쪼개는 토큰수는 본인이 사용하면 언어 모델이 맞게 설명하면 된다. (공식 문서를 참고하면 추천 토큰수 확인 가능)
Emdedding 할 때 (Emdedding : 텍스트를 Vector로 변경하는 방법)
- 영어를 Embedding 할거면 OpenAi 쓰고
- 한국어를 Embedding 할거면 Upstage Embedding 쓰는게 더 좋다.
추가로 나는 Upstage 를 사용하였다. 강의에서 진행한 소득세법이 모두 한글인 점과, Upstage의 경우 회원가입시 무료 10달러 지원을 받을 수 있다.
유사도 검색
Pinecone.io/learn/vector-similarity/
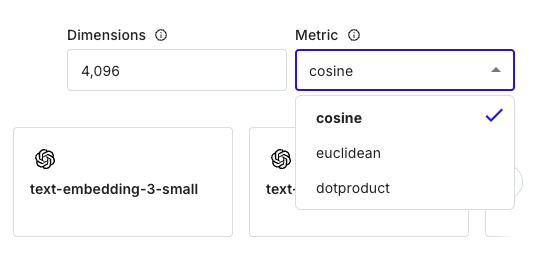
유사도 검색은 총 3가지 방식이 있다. (Euclidean distance, Dot product, Cosine)
- Euclidean distance
- 2개의 백터 사이의 거리를 잰다 - 거리를 측정함으로써 이거 2개가 얼마나 가까운지 보는 것
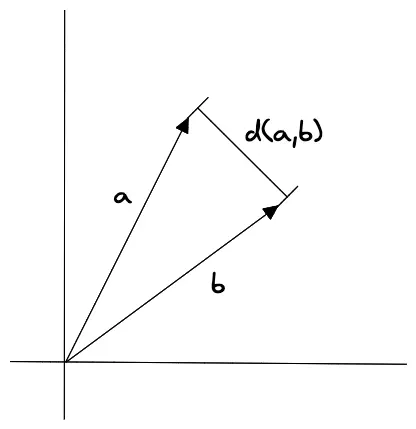
- Dot product
King = [1, 2, 3]
Queen = [4, 5, 6]
king[1]Queen[4] + king[2]Queen[5] + king[3]*Queen[6]
이렇게 비교하는데 이 방식은 dimention이 커질수록 당연히 숫자가 커져서 별로 의미가 없다.
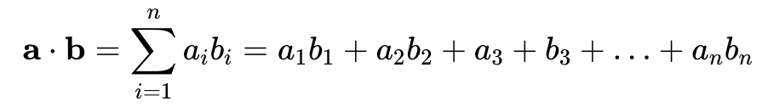
3. Cosine
2개의 백터 사이에 각을 잰다.
각도가 작을 수록 2개의 백터가 비슷하다.
cosine을 가장 많이 씀
유사도 검색 방법은 따로 정해진 것은 아니다. 하지만 cosine 방식이 많이 사용되었기에 사용하였다. 여러 방식을 사용해보며 정해도 된다.
트러블 슈팅
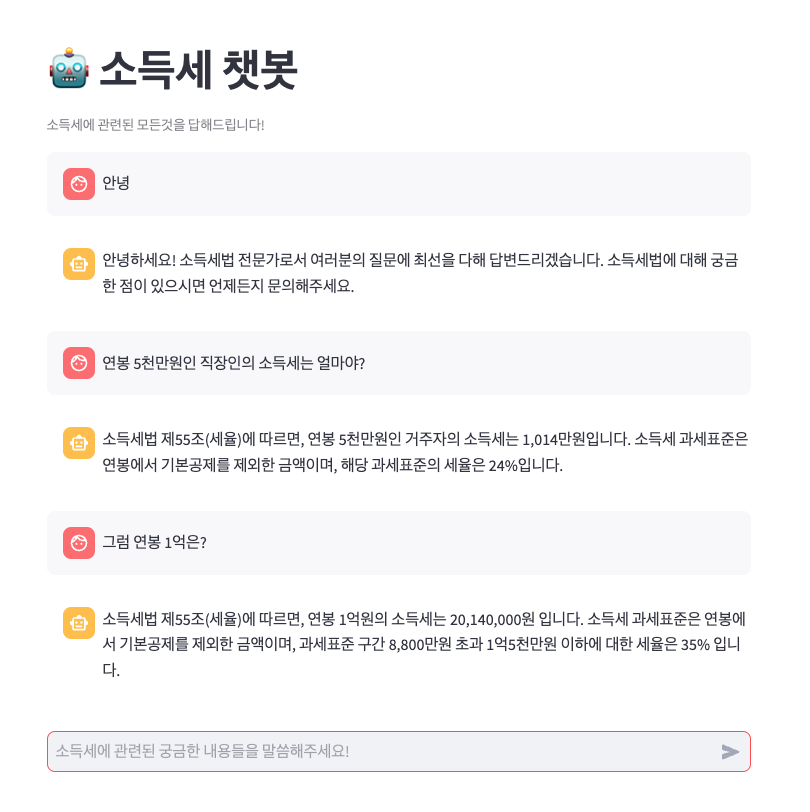
보통 챗봇이라고 하면 우리가 대화를 했던 history를 기억하고 있어야 한다.
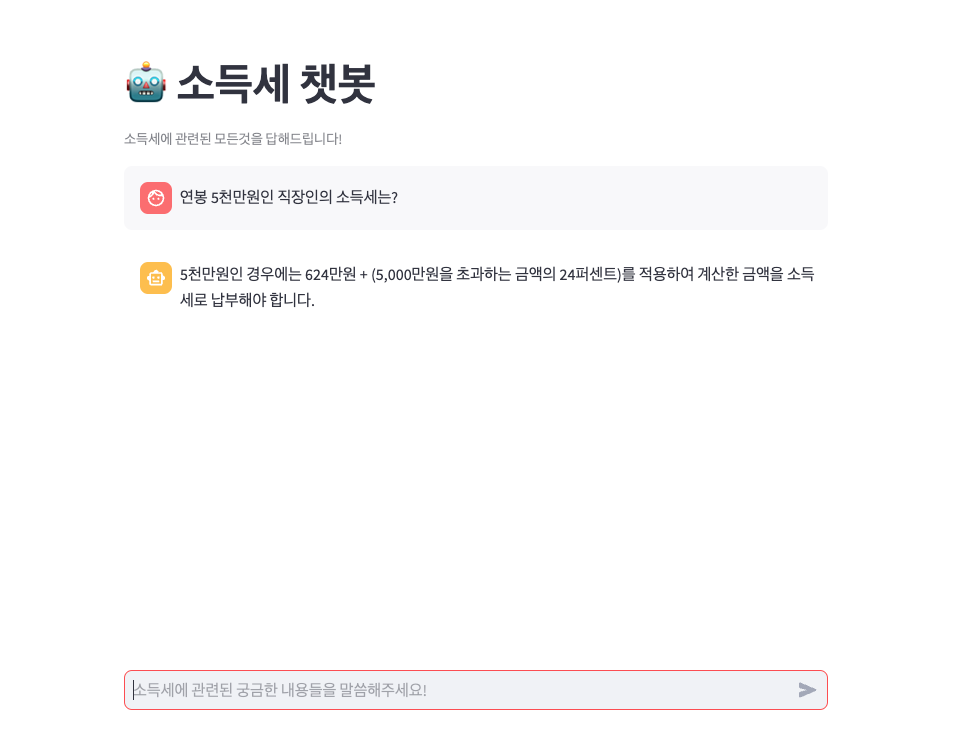
쉽게 말해서 연봉 5000천만원 직장인의 소득세는?
질문에서 이 질문을 기억하고 있다가 다음 채팅에서 그럼 1억원은? 이라고 질문하면 이전 대화 history를 기억하고 있다가 챗봇이 문맥에 맞추어 알아듣게 하는 것이다.
그것을 구현하기 위해서 langchain에서 Adding chat history 작업을 진행하였다.
langchain_Adding chat history
공식문서를 참고해서 진행하였는데 문제가 발생하였다.
공식문서에 코드가 다 나와있어 읽어보고 적용하면 되었기에 큰 문제 없을 줄 알았지만 오류가 발생하였다.

채팅 history를 추가하기 위해 위 구문을 import 해주면 되는데 작성하고 실행 후 오류가 발생하였다.
위 사진 첫줄 코드가 문제였다.
gpt 검색과 구글 검색결과 순차적으로 알게 된 정보는 다음과 같다
- LangChain이 최근 업데이트되면서 일부 모듈이 langchain_community로 분리
- langchain_community 패키지를 설치
- LangChain 업데이트로 인해 ChatMessageHistory가 더 이상 langchain_community.memory에서 직접 가져올 수 없게 변경
- langchain_core.memory에서 더 이상 직접 가져올 수 없다
- ChatMessageHistory는 이제 langchain.memory.chat_message_histories에서 가져와야 한다.
ImportError: cannot import name 'ChatMessageHistory' from 'langchain_core.memory'
LangChain 업데이트로 인하여 LangChain 최신 버전에서 ChatMessageHistory의 경로 변경되어
langchain_core.memory에서 직접 가져올 수 없다는 거였다.
이후 구글 검색과 챗 gpt의 도움을 받아
ChatMessageHistory는 이제 langchain.memory.chat_message_histories에서 가져한다는 것을 알게 되었다.
이후 langchain_community 패키지를 업데이트 및 재설치하고
from langchain.memory.chat_message_histories import ChatMessageHistory
코드로 수정하였다.
이후 정상동작하는 것을 확인하였다.
강의를 보면서 공부하는데 아무래도 강의 작성 시점과 강의 수강 시점이 텀이 있고 그 사이 langchain에서 업데이트가 되어서 문제가 발생한것 같다.
그렇게 큰 문제는 아니지만 강의의 내용과 다른부분이 있어 작성하였다.
챗봇 배포 및 시현 화면
Streamlit Cloud로 배포 (https://share.streamlit.io/)
(현재는 private 상태로 변경해둠 - Upstage Console의 모델 사용 비용 이슈)
평가 및 소감
RAG이 무엇인지 확실히 알게 되었으며, 유사도 검색의 중요성과 방식에 대해 알게 되었다.
간단한 챗봇을 만들고 배포해보았으며, 추후 비슷한 유형의 다른 정보를 제공하는 챗봇도 제작할 수 있을 것 같다.
LLM, RAG에 대해 지금은 정말 가볍게 체험해본 느낌이며, 조금 더 깊게 공부해도 좋을 듯 하다.
