모든 종류의 IT와 관련한 학습이 그렇듯이, 사용할 라이브러리/함수/메서드/기능 들은 너무나도 방대하게 존재하기 때문에 선형적으로 모든 것을 탐색해서 공부할 수 없다.
당연하게도, 여러가지 실전적인 실습 문제상황을 정의하고 이를 구현하는 데에 사용되는 것, 그리고 관련하여 확장된 것들을 공부하는 것이 바람직한 수순이다.
따라서, 실습 주제를 정해놓고 해당하는 과정에 필요한 구현이나 설명으로 학습해보고자 한다.
RPA를 통해 자동화로 수행할 가장 간단하고도 가장 쉽게 떠오르는 형태의 업무는 바로 데이터 크롤링 일 것이다.
1. 업무 정의하기
우선, 실습 프로젝트의 내용을 다음과 같이 정의하겠다.
KBO 야구협회 사이트에 접속하여, 기록실 데이터에서 작년 KBO 정규시즌의 외야수에 대해 PA 내림차순을 하여, 타율(AVG)이 0.3 이상인 선수만 필터링하여 팀별, 2B, 3B, HR 개수에 대한 피벗차트를 묶은 세로 막대형으로 저장하라.
이 프로젝트 자체의 내용이 사이트로부터 데이터를 추출한 후 가공 과정을 거쳐 엑셀 파일에 가공 데이터를 통한 시각화 자료를 저장하는 것, 이 자체를 자동화하고자 한다.

이 하나의 업무 흐름 Process 에 대해서, 단일 반복 작업 단위인 Task 로 분할할 수 있다.
이 때, 완벽하게 동일하진 않겠지만 간단히 생각하면
Process 는 OOP에서의 Class와 같은 역할을,
Task 는 그 클래스 내 특정 기능을 수행하는 Method 역할을,
Bot 은 정의된 프로세스를 실제로 실행하는 주체로서의 Instance라고 이해하면 편할 것 같다.
따라서 정의된 업무에 대해서, 위와 같이 태스크를 분할하여 작업을 설정해 볼 수 있다.
RPA는 기본적으로 시각적인 순차적 흐름을 가진 Flow Chart와 유사한 방향으로 볼 수 있다.
이미지에서 알 수 있듯, 일반적으로 프로세스는 'P'의 prefix가, 태스크는 'T'의 prefix가 붙는다.
(이벤트에 대한 내용은 이후에 다루도록 하겠다.)
2. 초기화하기
최초 태스크에서는 앞으로 사용될 여러 전역 변수나 파일 폴더 경로 생성 등의 작업을 선행해주는 것이 좋다.
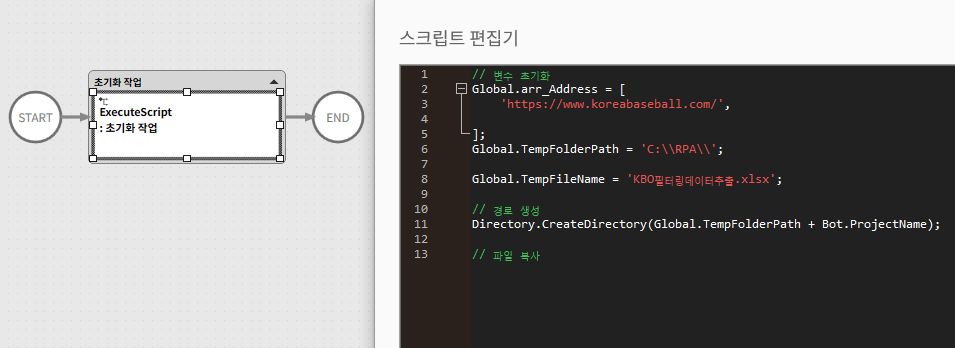
Task와 Library
Library 란 자주 사용되는 태스크 또는 하위 프로세스를 미리 만들어 두고 필요 시 사용 가능한 컴포넌트들의 집합이다.
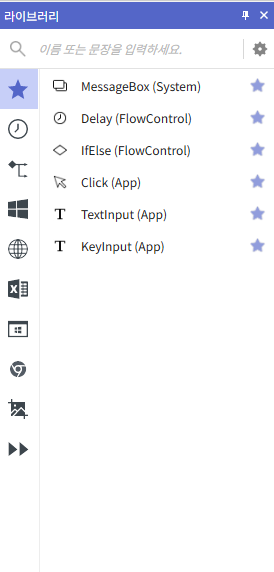
라이브러리 창에서 Brity는 애플리케이션, 네트워크, 엑셀, 크롬, 이미지 인식, 흐름 제어 등 다양한 라이브러리 기능을 제공한다.
이 이외에도 사용자가 직접 생성한 커스텀 라이브러리도 사용 가능하다.
Execute Script 라이브러리
이 라이브러리는 RPA에서 직접 사용자가 정의한 스크립트를 실행하도록 도와준다. 해당 스크립팅은 JavaScript 문법을 따른다.
RPA 프로젝트 내 변수
앞서서 초기화 작업에서는 전역 변수 초기화 과정을 거친다고 언급했다.
이 때, RPA 프로젝트 내 변수는 적용 범위는 네 가지 종류로 다음과 같다.
1) Global. 전역변수
Global. 으로 prefix가 붙는 것은 전역 변수로, 전체 프로세스 및 그에 포함된 모든 하위 태스크에서 사용가능한 변수이다. 프로세스가 시작될 때 생성되어 종료될 때까지의 생명주기를 갖는다.
보통은 전체 자동화에서 필요한 파일 경로, 처리될 트랜잭션 ID 혹은 PID, 누적값, 자격증명 정보 등에 사용된다.
2) this. 지역변수
this. 로 prefix가 붙는 지역 변수로, 정의된 태스크 혹은 시퀀스/루프 블록 내에서만 유효하다. 이 때, 라이브러리 코드 블록에서 this.로 별도의 prefix없이도 사용가능하다.
다만, this.로 등록한 지역 변수는 디버그 시 변수창에서 상태 확인이 가능한 반면 후자는 그렇지 않기에 지양되는 편이다.
3) Input, Output 매개변수
앞서서 Task는 OOP에서의 Method와 비슷한 역할을 한다고 했다. 마찬가지로, Method가 매개변수로 입력받는 값, 그리고 반환하는 값처럼 태스크가 외부 영역으로부터 입력받는 값과 태스크 영역 밖으로 산출하는 값의 역할을 한다.
보통 변수 명명시에 이를 식별하기 위해 in 혹은 i, out 혹은 o를 붙여주는 편이 좋다.
위 내용을 기반으로 다음같은 예시를 볼 수 있다.
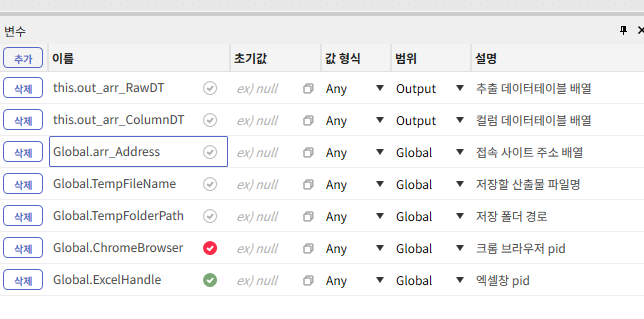
이미지에서 볼 수 있듯, 변수창에서 별도의 설명을 달아 놓을 수 있으며, 초기값 설정 및 자료형을 설정할 수 있다.
3. ChromeBrowser 다루기
크롬 브라우저 열기
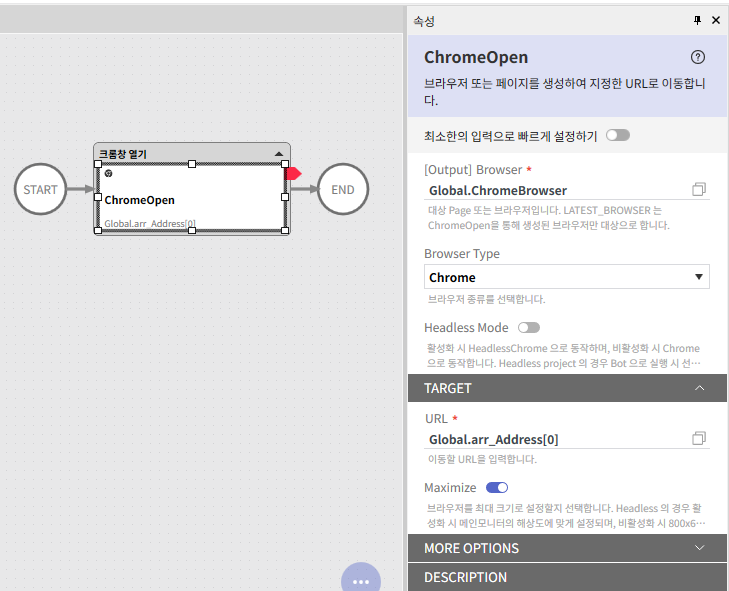
위의 이미지와 같이 ChromeOpen 라이브러리를 활용하며, 해당 크롬 브라우저의 pid를 전역변수에 저장하도록 한다. 이 pid를 기억하는 이유는 이후에 크롬 작업을 하는 데에 브라우저를 지정해줘야 하기 때문이다.
물론, LATEST_BROWSER라는 키워드로 가장 최근 사용된 브라우저를 가져올 수 있으나, 전역변수를 통해 pid를 관리하는 편을 지향한다.
만약 이미 창이 열려있다면, ChromeNavigate 라이브러리를 통해 이미 열려있는 브라우저에서 사이트로 이동하는 것도 가능하다.
추가적으로, 종종 사이트 고유의 문제로 로딩이 오래 걸리는 경우가 존재한다. ChromeOpen은 해당 브라우저에서 지정된 사이트로 접속 progressbar가 완전히 완료된 이후에야 해당 라이브러리가 종료되기 때문에, 종종 오래 로딩이 걸릴 경우 한정된 대기 시간을 초과하여 오류를 반환하는 문제가 생길 수 있다.
이 때에는, 적절한 대기시간 값과 오류 반환 시 멈추지 않고 ignore등을 설정하고 새로고침을 keyinput으로 설정해주는 것이 좋다.
사이트에서 메뉴 탭을 통해 특정 페이지로 가기 위해서는 다음 라이브러리 블럭들이 사용된다.
ChromeClick
크롬 브라우저 내에서 마우스 클릭 이벤트를 적용한다. 이를 위해 타겟 객체를 지정해줘야 한다.
(크롬 브라우저 내에서만 적용되므로, 그 이외에는 전반에서 적용되는 Click 라이브러리 사용)
MouseHover
마우스를 호버링하여 특정 객체 위에 올려놓는다.
이 때, 두 가지 정도 고려해주는 것이 좋다.
1) UI 대기하기
보통 사이트 이동 및 탭을 눌러 페이지 이동 시 대기 시간이 필연적으로 존재하기 마련이다. 이 때, 대기 시간 초과로 인해 누르고자 하는 객체가 잡히지 않아 Click에 실패하여 오류가 반환되는 경우가 존재한다.
이를 위해 권장되는 것은,
ChromeWaitAppear 와 ChromeIsExist 이다.
UI 객체가 나타나기까지 ChromeWaitAppear을 통해 대기해주고,
UI 객체가 현재 브라우저 상에서 존재하는지 ChromeIsExist 을 통해 반환되는 boolean 값으로 검증가능하다.
2) ExecuteQuery의 설정
우리가 접근하려는 UI 객체가 웹페이지 내에 정적으로 항상 존재한다면 좋겠지만, 웹페이지는 보통 동적으로 반응하여 생성된다.
가령 네이버 검색을 하는 경우를 예시로 들어보자.
검색어에 대해 '뉴스' 탭으로 접근하고자 했을 때,
어떤 검색어를 입력하느냐에 따라 실제 웹 페이지의 탭에 '뉴스' 카테고리는 몇 번째에 등장하는지 알 수 없이 상이할 것이다.
이 경우, 따라서 접근하고자 하는 UI 내 텍스트가 확실할 때
(가령 Work Items 라고 한다면)
// 예시 쿼리문
'//div[@id=\'dashmenu\']/div/a/button[contains(., \'Work Items\')]'
위와 같이 contains() 메서드를 통해 접근하는 것을 권장한다.
이 때 주의할 점은 쿼리도 '' 문자열로 들어가기 때문에 contains 될 문자열에 대해서 \' 으로 적용해줘야 한다는 점이다.
