서론
이번 시간에 알아볼 내용은, 서버 통신에서 데이터 전달을 하는 것과 연관한 여러 가지 개념들에 대해 다뤄보고자 한다. 사실상 이번에 다루는 내용의 중추는 Serialization(직렬화)에 관련한 내용이다.
Serialization 직렬화
직렬화는 객체 데이터를 byte stream으로 변환하여 네트워크에 전송하는 과정을 말한다.
<1> 엔디안 Endianness
엔디안은 CS에서 데이터 byte에서의 배열 순서와 관련하여, 컴퓨터가 데이터를 메모리에 저장하는 방식에 관한 것이다.
(1) Big Endian

MSB (Most Significent Byte)가 메모리의 앞쪽(작은 주소)에 위치하는 방식으로 왼쪽에서 오른쪽으로 데이터를 읽는 방식이다.
ex. 0x12345678 가 주어질 때에, big endian으로 저장되었다고 하면,
0x12 0x34 0x56 0x78(2) Little Endian
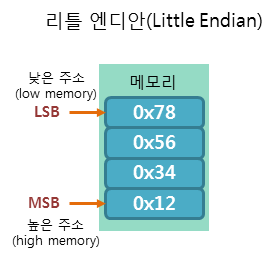
하위 바이트인 LSB (Least Signficent Byte)를 메모리 앞쪽에 위치시켜 데이터를 오른쪽에서 왼쪽으로 읽는 방식이다.
ex. 위와 동일하게 0x12345678 가 주어질 때에, little endian으로 저장되었다고 하면,
0x78 0x56 0x34 0x12Endian의 중요성
CPU 아키텍쳐에 따라 상이한 엔디안 방식을 사용하게 된다. 이를테면, x86 아키텍쳐에서는 Little Endian을, 일부 네트워크 프로토콜이나 시스템 프로토콜에서는 Big Endian을 사용한다. 이럴 경우, TCP 서버에서 데이터를 전송하거나 받을 때, 클라이언트와 서버 간 엔디안 방식이 다르다면 데이터가 잘못 해석되는 치명적인 상황이 발생 한다.
따라서 Node.js의 경우 Buffer 객체를 사용함으로 엔디안을 지정하여 이러한 상황을 막을 수 있다.
// 시나리오
// 'Hello'라는 문자열에 대해 생각해보자
// 1. String 문자열 데이터가 ASCII 코드 값 decimal로 변환된다.
// Hello => [72 101 108 108 111]
// 2. decimal 값에 대해 16진수 byte stream으로 변환된다.
// [72 101 108 108 111] => [0x48 0x65 0x6c 0x6c 0x6f]
Buffer 객체
버퍼 객체는 이진 데이터를 다루기 위해 고안된 객체로 Unicode 문자를 16bits 단위 인코딩하는 방식의 UTF-16형식의 비효율성을 해결하며 다음과 같은 특성을 가진다.
#1. 고정 길이: buffer 객체는 고정된 크기의 바이트 배열이다.
#2. 빠른 접근: buffer객체는 바이트 단위 접근 및 조작이 가능하여 binary 처리에 용이하다.
