[컴퓨터 구조 - 하드웨어 - 프로세서]
참고한 자료:
Computer Organization and Desgin 5th edition,
Digital Design with an Introduction to the Verilog HDL 5th edition
1. 서론
컴퓨터의 고전적인 구성 요소 (5)
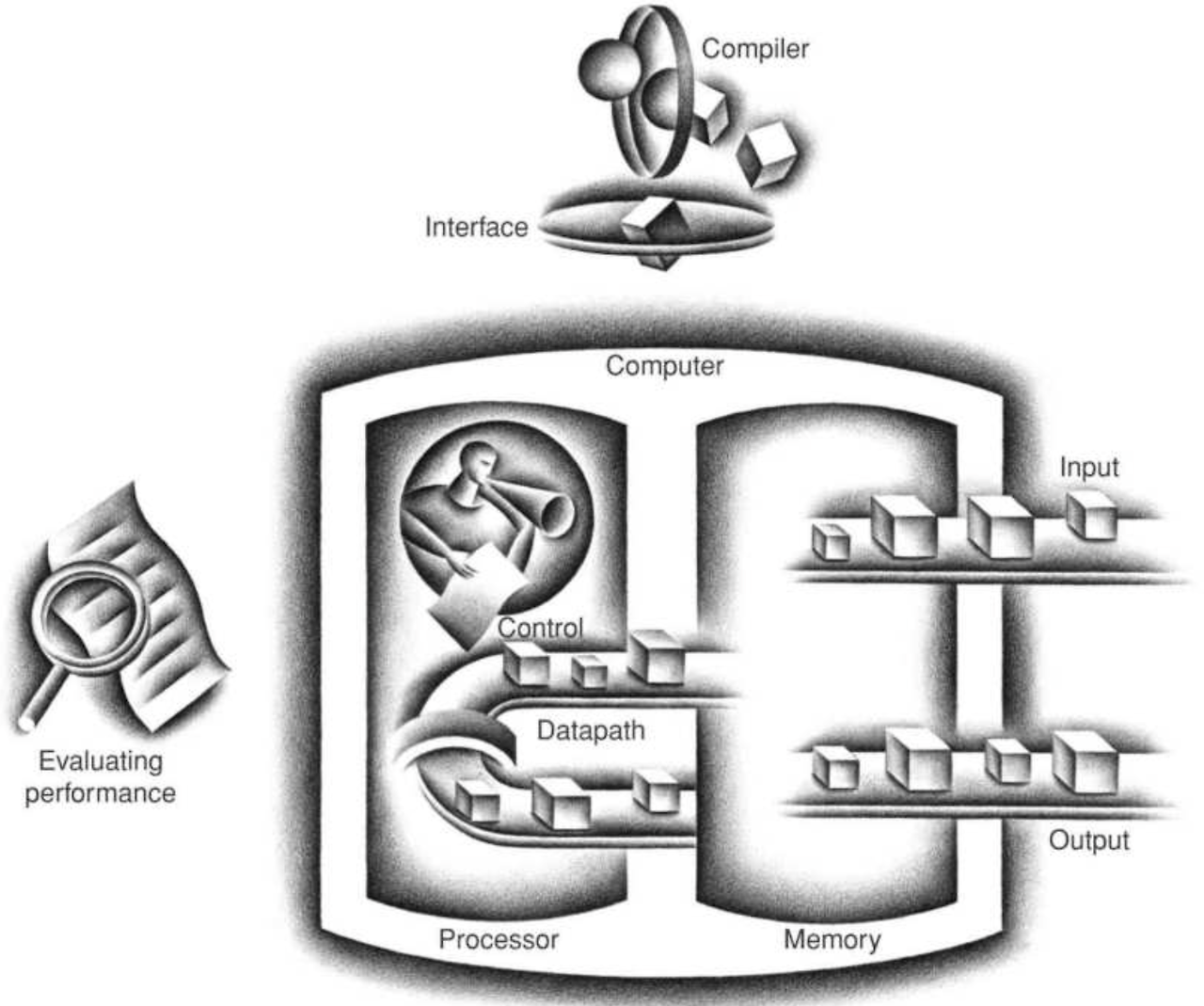
- Input
ex. 마이크 (음성 입력), 키보드 (키 입력) - Output
ex. 스피커 (음성 출력), 모니터 (화면 출력) - Memory
ex. Main memory, secondary memory - Control
ex. PC (Program Counter), - Datapath
Input 유닛은 Memory에 데이터를 쓰고, Output 유닛은 Memory 에서 데이터를 읽는다.
Datapath는 데이터를 세이브/로드하는 역할 및 연산 수행을 담당하고, Control 유닛은 컴퓨터 내부의 명령을 해석 및 실행하는 역할로 명령에에 따라 데이터패스, 메모리, 입출력의 동작을 결정하는 신호를 보낸다.
이 때, Control 유닛과 Datapath 유닛을 합쳐 Processor 라고 한다.
Processor 는 CPU를 보조하며 연산/제어의 핵심부를 담당하는데, 시간이 흐름에 따라 Processor라는 용어가 점차적으로 CPU라는 용어를 대체하여 현재는 동일한 의미로 통한다고 볼 수 있다.
2. CPU (Central Processing Unit)
CPU 는 중앙 처리 장치로, 메모리에 저장된 명령어를 읽어들이고, 읽어들인 명령어에 대한 interpret 와 implement를 담당한다.
진부한 표현이지만, CPU는 결국 컴퓨터에 있어 두뇌 역할을 하는 장치이다.
CPU의 구성요소
- ALU
- CU
- Register
- Cache
ALU (Arithmetic Logic Unit)
ALU는 산술 연산 (덧셈, 뺄셈, 곱셈, 나눗셈)과 논리 연산 (AND, OR, NOT, XOR) 을 수행하는 연산 장치이다.
CU (Control Unit)
CU는 instruction을 해석하고, 그 명령의 순차적인 실행과 제어 흐름을 관리하는 역할을 한다. CU는 다른 구성요소가 적절히 작동하도록 관리하는데, PC (Program Counter)를 통해 명령어의 순차적인 실행을 보장한다.
Register
Register는, clock을 공유하는 n개의 Flipflop으로 구성되어 n개의 비트를 통해 binary 정보를 저장하는 장치이다.
cf. FlipFlop
전자 회로에서 1bit 정보를 저장하는 기억 소자
Cache
Cache는 CPU와 RAM 메인 메모리 사이 데이터 전동 속도를 높이기 위해 사용되는 고속 저장장치이다.
CPU의 작동원리 w. 시나리오
예시 시나리오에 대해 CPU가 처리하는 과정을 살펴보자. 사용자가 15 + 57을 계산한다고 가정하자.
CPU는 Instruction Cycle을 통해 (Fetch -> Decode -> Execute -> Store) 다음과 같은 단계를 거친다.
위 시나리오에서는 다음과 같은 일련의 명령어 집합을 수행해야 한다.
LOAD 15
ADD 57
STORE RESULT1) Fetch Instruction
CPU는 메인 메모리에서 코드 데이터를 읽어오며, 위 instruction들에 대해 PC가 첫 번째 명령어 LOAD 15를 가리킨다. 해당 명령어를 Instruction Register에 가져오고, PC는 다음 명령어를 처리할 수 있게 증가한다.
2) Decode Instruction
Instruction Decoder가 처리할 명령어에 대해 해석 과정을 거친다. 명령어 LOAD 15에 대해, Operator인 LOAD는 적재 명령어임을 해석하고, Operand인 15는 메모리에서 가져와 Register에 저장한다.
3) Execute Instruction
앞서 decode된 내용을 바탕으로 작업을 수행한다.
LOAD 15에 경우, decode된 내용은 적재, 15이므로 accumulator에 15를 저장한다.
4) 다시 Fetch
PC가 앞선 fetch과정에서 증가했기에, 두 번째 명령어인 ADD 57 명령어를 가리킨다. 이 명령어를 가져오고, PC는 다시 증가한다.
5) Decode Instruction
명령어 ADD 57에 대해, Operator인 ADD 덧셈 산술 연산 명령어임을 해석하고, Operand인 57 메모리에서 가져와 Register에 저장한다.
6) Execute Instruction
ADD 57의 경우, decode된 내용은 덧셈 산술 연산, 57이므로 accumulator에 저장된 값 (15)에 메모리에서 가져온 피연산자 57에 대한 산술 연산을 처리하여 결과값(72)을 다시 accumulator에 저장한다.
7) Store
accumulator에 저장된 계산 결과를 메모리 위치에 저장한다. 앞서서 from memory to register의 방향으로 처리한 load 적재와 반대로, store 저장은 register에서 memory로 데이터를 보낸다.
요약
이러한 일련의 과정 속에서, 앞서 설명했듯이
레지스터는 메모리로부터 데이터를 가져와 저장하고,
ALU는 산술/논리 연산을 수행하며
CU는 instruction의 실행 순서를 관리한다.
cf. register와 cache 차이?
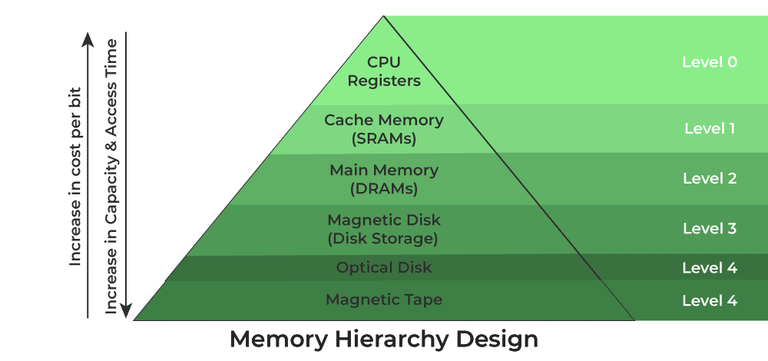
양자 모두 CPU 내부에서 데이터를 저장하는 메모리 역할을 하지만 그 용도와 작동 방식은 다르다.
register의 경우,
- CPU 내부에 직접 사용되는,
- 매우 빠른 처리 속도의
- 연산에 필요한 소량의 데이터/주소를 일시적으로 저장하는 역할을 한다.
cache의 경우,
- main memory 와 CPU 사이 위치한
- 최근에 사용/ 빈번하게 사용되는 데이터를 빠른 접근을 위해 저장하여
- main memory 접근 시간을 줄임으로 성능을 향상시키는 역할을 한다.
cf. Pipelining
위의 예시 시나리오에서 간단한 명령어 집합을 처리했지만, CPU는 위 예시 이외에도 다양한 복잡한 명령어를 처리해야 한다. 모든 명령어가 같은 길이의 클럭 사이클을 가지게 된다면 단일 사이클 설계만으로 처리가 수월하겠지만, 부동소수점 유닛을 포함한 복잡한 명령어 집합에 대해서는 그렇지 못하다.
이러한 단일 사이클 구현은 Common Case Fast라는 설계 원칙에 위반되기 때문에, 여러 명령어가 중첩되어 실행되는 구현 기술인 Pipelining을 보편적으로 사용한다.
ex. 앞선 시나리오에서 예를 들면,
단일 사이클이라면,
첫 번째 명령어 LOAD 15 의 처리 사이클을 마친 이후
두 번째 명령어 ADD 57 에 대해 수행될 것이다.
파이프라이닝을 적용하면,
첫 번째 명령어 LOAD 15 의 Decoding 이후,
LOAD 15의 Execution을 처리하면서 동시에 ADD 57을 Decoding하고, 다음 명령어를 가져올 수 있다.
정리하자면, Pipelining은 적용하면
cycle time 자체를 단축시키지는 못하나
throughput을 증가시킴으로 병령 처리를 통해 전체 명령어 집합 처리 시간을 단축시킨다.
3. 성능 측정
우리는 종종 성능에 대해 추상적으로 성능 최적화, 성능을 효율적으로 한다는 등 너무 추상적으로 성능에 대해 잘못 표현하는 실수를 저지르곤 한다. 위와 같은 말은 성능에 대해 너무나 부족한 정보를 가진 말이기 때문에 언제나 performance와 관련해서는 엄밀한 척도에 대한 정의가 필요하다.
개개인 유저 입장에서는 Response Time 응답시간으로서의 요청을 보낸 시점부터 응답이 도착하기까지 걸리는 시간, 혹은 Execution Time 실행시간으로서 프로세스 관점에서 전체 작업 개시에서 종료까지의 시간이 성능 측정 척도일 것이다.
반면, 시스템 관리자에게는 단위 시간당 완료하는 태스크의 수와 관련한 Bandwidth나 Throughput이 중요할 것이다.
1. Clock Cycle
클록 사이클은 하나의 클록 주기를 의미하며, 시스템의 클록이 한 번 완전히 변하는 시간이다.
클록 사이클은 CPU나 다른 디지털 시스템에서 동작을 정기적으로 동기화하는 기준이 된다.
간단히, positive edge에서 다음 positive edge까지 걸린 시간이다.
2. Clock Speed / Clock Rate
클록 속도는 시스템 클록의 주파수로, 1초 동안 클록 사이클이 얼마나 발생하는지를 나타냅니다. 측정 단위로 Hz(헤르츠)가 사용되며 초당 발생하는 클록 사이클 수를 의미한다.
(clock rate는 cct의 역수 관계)
단위 시간 동안의 positive edges의 수를 의미한다.
cf. Positive Edge
Positive Edge는 clock signal이 낮은 상태에서 높은 상태로 변화할 때 발생하는 ( 0 -> 1) 상승 엣지 순간을 의미한다.예를 들어, flipflop이나 register 같은 순차 회로는 positive edge에서 데이터를 읽거나 저장한다.
고전적인 CPU 성능 식
CPU 시간 = Instruction 개수 X CPI (Clock cycles per Instruction) X Clock Cycle Time
cf. cpu와 관련하여 알면 좋을 CA 쪽 지식들
ISA (Instruction Set Architecture)
ISA, 명령어 집합 구조란 CPU가 이해하고 실행하는 명령어 집합 및 인터페이스를 정의한 추상적 모델이다.
어셈블리 기계어 단의 low level의 하드웨어와
high level단의 응용의 소프트웨어 간의 인터페이스를 정의하는 명령어 집합이다.
종류: Intel사의 x86, AMD사의 AMD64(x86-x64), ARM사의 ARM ISA, MIPS, AVR, etc.
x86
Intel 사가 설계한 x86 은 복잡한 명령어 셋으로 높은 성능과 다양한 sw를 지원하지만 높은 전력 소모가 발열에 문제점을 가지고 있다. 명령어 집합으로는 CISC를 택했으며, 16bit / 32bit을 사용한다.
MIPS
MIPS는 RISC 기반의 ISA로 단순한 명령어 셋과 고효율적인 설계로 전력 소모와 발열이 상대적으로 적은 장점을 가졌기에 embedded, IoT, 네트워크 장치 등에 널리 사용된다.
CPU 설계 철학: RISC와 CISC
CISC (Complex Instruction Set Computing)
CISC는 복잡하고 다양한 명령어를 포함한 CPU 설계 철학으로, 고급 명령어를 제공하며 SW에 가깝게 high level단으로 프로그래머의 편의성에 초점을 둔 설계 방식이다.
설계 방식에서의 가장 큰 특징은 복잡한 명령어의 개수가 많다는 점이다. 이 특징이 가져오는 장단점은 다음과 같다.
(+) 장점
- 컴파일 과정이 쉽고 sw친화적 명령어로 인해 호환성이 좋다.
- 복잡한 작업에 대해 단일 명령어로 처리 가능하다.
- 다양한 주소 지정을 지원하고, sw 개발에 보다 용이하다.
(-) 단점
- 가변적인 명령어 길이로 하드웨어 설계와 decoding 과정이 복잡하다.
- 위의 이유로 전력 소모 및 발열이 높다. 이로 인해 모바일 환경 혹은 저전력 기기에 적합하지 않다.
- 복잡성이 높은 만큼 파이프라이닝 설계가 어려워 처리/실행 속도가 상대적으로 느리다.
RISC (Reduced Instruction Set Computing)
RISC는 간소화된 명령어 집합을 포함한 CPU 설계 원칙으로, HW에 가깝게 Low level 단으로 고효율 고성능의 하드웨어 설계에 초점을 둔 설계 방식이다.
다음과 같은 장단점을 가진다.
(+) 장점
- 명령어가 간단한 형식과 단순화된 종류를 가진다.
- 명령어가 고정 길이이기 때문에 decoding 과정이 단순하고 빠르다.
- 대부분의 명령어가 동일 clock cycle안에서 실행된다.
- 메모리 접근 및 cache 활용이 효율적이다.
- 단순한 명령어로 인해 병렬 처리가 수월하고 파이프라이닝 성능이 극대화된다.
- 단순한 설계로 전력 소모와 발열이 적은 편이다.
(-) 단점
- 복잡한 작업을 처리하는 데에 더 많은 명령어가 필요하다.
- 명령어가 하드웨어 적이며 처리 비트 단위가 변하거나 프로세서 구조 변경 시 하위 프로세서와 호환성이 떨어진다.
