R-Transformer
RNN
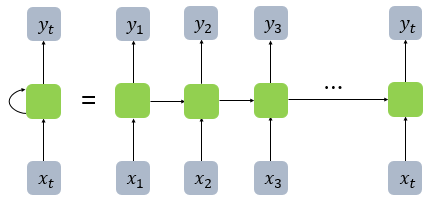
RNN은 그림처럼 순환하며 출력을 다시 입력으로 받는 모델입니다. RNN은 이런 순환성 때문에 기억을 가지는 모델이라고도 부르는데요, 문장을 이해하기 위해서는 맥락을 이해해야 하고 맥락을 이해하기 위해서는 이전의 결과가 다음의 결과에 영향을 미쳐야 합니다. RNN은 다양한 곳에 유용하게 사용되는 모델이지만, 큰 문제를 가지고 있습니다.
첫번재 문제점은 장기의존성 문제입니다. RNN은 시점이 포함된 모델이고, RNN모델 학습시 백프로파게이션은 시점마다 이루어져야 합니다. 이로인해 RNN은 gradient vanishing and exploding problems이 쉽게 일어납니다. 이렇게 긴 문장에 대해서 RNN이 학습이 제대로 이루어지지 않는 문제를 장기의존성 문제라고 합니다. 즉, RNN은 시점이 길어질 수록 앞에 정보가 뒤로 충분히 전달되지 못합니다.
두번째 문제점은 병렬화가 불가능하다는 점입니다. 이전 분석 결과가 이번 분석에 영향을 미치기에, 순차적(직렬적)으로 연산을 실행해야하기 때문에 병렬화가 불가능합니다.
이런 문제들 때문에 non-recurrent sequence모델이 많이 제안되어 왔습니다. 특히, multi-head attention을 가진 트랜스포머 모델 같은 모델이 장기의존성 문제를 capture하는 데에 효과적인 것으로 나타났습니다. 트랜스포머 모델이 장기의존성 문제에 효과적인 이유는 바로 Transformer의 multi-head attention 메커니즘을 통해 모든 위치를 시퀀스의 다른 위치에 직접 연결할 수 있어 정보가 중간 손실 없이 전달되기 때문입니다.
Transformer
그러나 Transformer 역시 문제점이 있습니다.
- Positional Embedding :
효과가 제한적이고 상당한 설계 노력이 필요한 position embeddings 에 크게 의존합니다.- local structure :
저자는 자연어 모델과 같은 sequence 모델에서는 local structure가 중요하다고 말하는데요, 그러나 트랜스포머의 경우 local structures in sequences로 모델링하는 데 필요한 구성 요소가 부족합니다. 이러한 Transformer의 문제점은 (Dehghani et al., 2018; Al-Rfou et al., 2018)의 논문에서 다루고 있다고 하니, 궁금하신 분들은 이 논문들을 참고하시면 좋을 것 같습니다.
R-transformer
이러한 RNN과 트랜스포머의 문제들 때문에 본 논문에서는 두 모델의 장점을 모두 누리며 단점들은 피하는 R-Transformer를 제안하였습니다. 즉, 이 모델은 position embeddings 을 사용하지 않고, 시퀀스에서 local structures와 global longterm dependencies in sequences을 효과적으로 capture할 수 있습니다. 어떤 구조를 가지고 있다는 건지 조금 더 자세히 살펴보겠습니다.
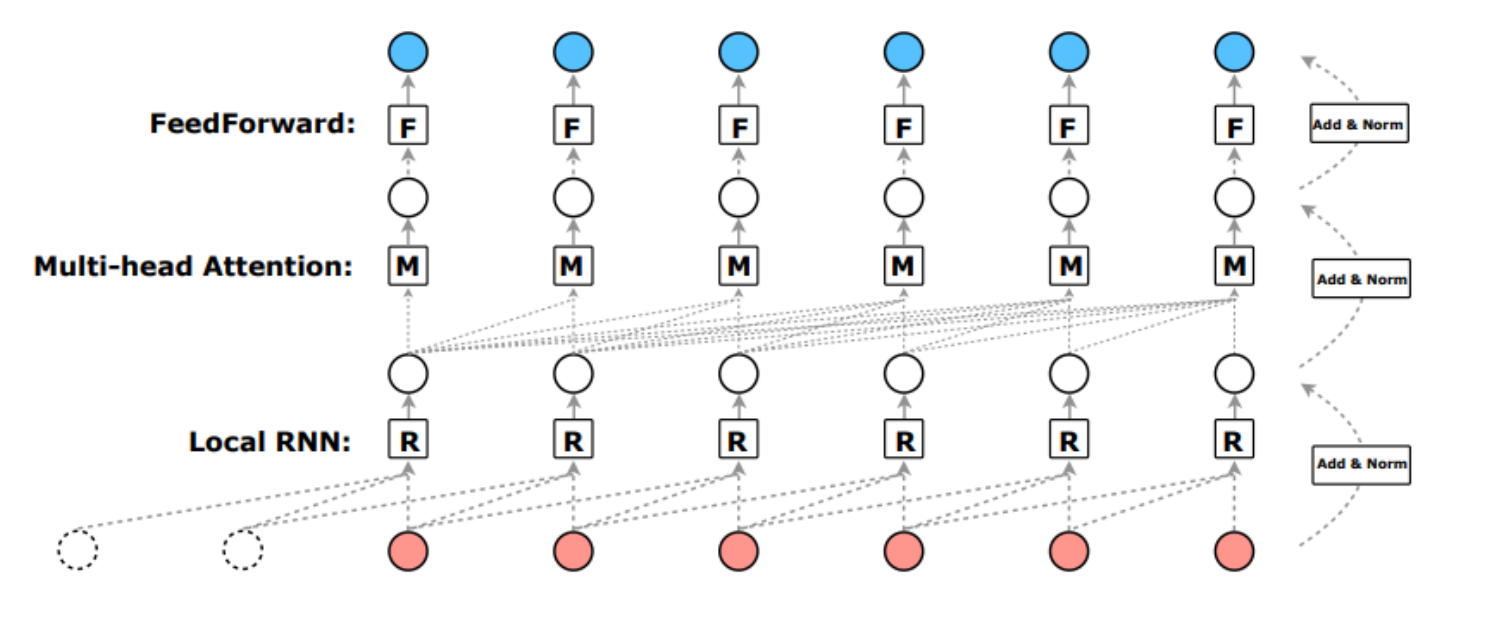
제안된 R-Transformer는 3개의 레이어로 구성됩니다. 첫번째 레이어는 Local RNN, 두번째 레이어는 Multi-head Attention, 세번째 레이어는 FeedForward입니다. 이 모델에서 새롭게 도입된 Local RNN에 대해서 설명드리겠습니다.
Local RNN입니다.
sequencial data는 본질적으로 강한 local structure를 가지고 있습니다. 따라서 locaity를 모델링하는 구성요소를 설계하는 것이 바람직합니다. 이를 달성하기 위해 저자는 RNN 을 활용하고 있습니다.
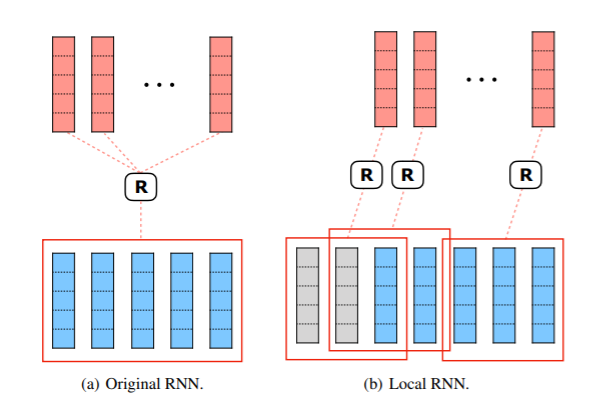
RNN이 전체 시퀀스에 작용되는 이전 모델들과 다르게, 우리는 original long sequence를 local information만을 포함하는 많은 short sequences로 재구성합니다. 그리고 RNN을 동일하게 독립적으로 적용시킵니다.

local window가 M개의 consecutive positions을 포함하고 target position에서 끝나도록 각 대상 위치에 대해 M 크기의 local window을 구성하는데요, 패딩을 통해서 개수를 맞춰준 것을 확인 할 수 있습니다. 따라서 각 local window의 position은 local short sequence를 형성합니다. 원래 RNN 비교했을 때, LocalRNN은 장기 종속성을 고려하지 않고 local short-term dependency에만 집중하는 것을 확인할 수 있습니다.
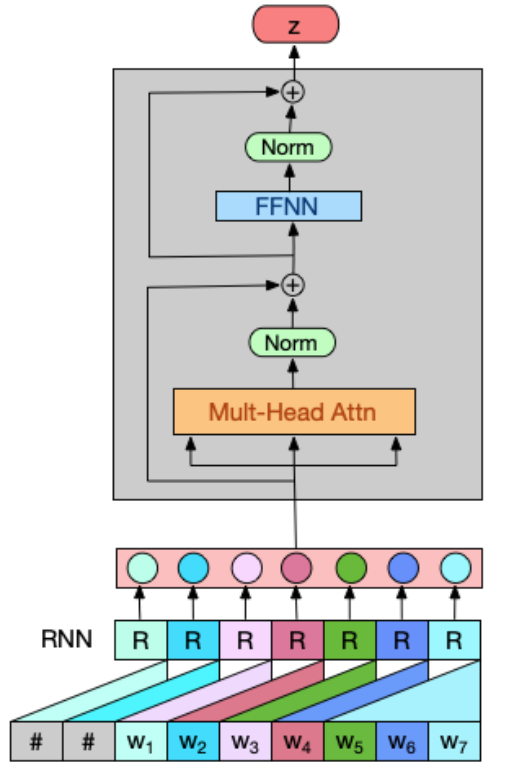
LocalRNN은 각 window 내에서 sequencial information을 완전히 캡처 할 수 있습니다. 또한 슬라이딩 윈도우 방식이기 때문에 자연적으로 global sequential information을 가지고 있다는 장점이 있습니다.
성능비교
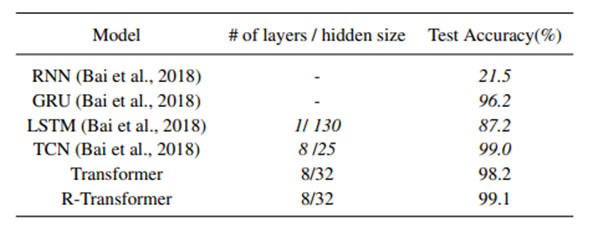
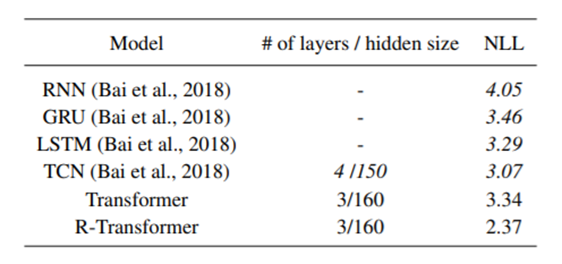
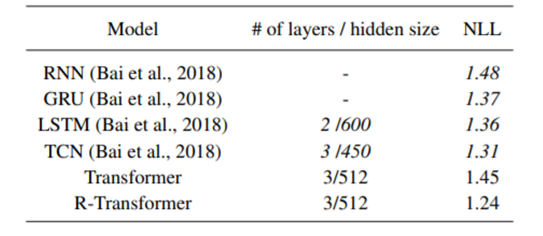
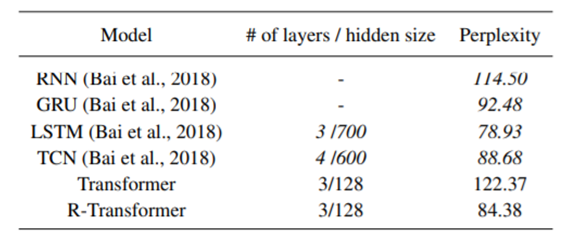
낮은 수준의 로컬 RNN과 높은 수준의 multi-head attention을 결합한 제안된 R-Transformer는 대부분의 작업에서 일관되게 TCN과 트랜스포머 모두를 큰 폭으로 능가함을 확인할 수 있었습니다.
