서버간 시간 동기화
리눅스 인스턴스 시간 설정
정확한 시간 체크를 하기 위해서는 서버 간 시간을 맞춰 주어야 한다. 내가 사용한 우분투의 경우 다음의 순서를 따라 Amazon Time Sync Service의 IPv4 엔드포인트에 연결해 시간을 동기화할 수 있다.
- chrony를 사용하여 chrony 패키지 설치
sudo apt install chrony- /etc/chrony/chrony.conf 파일을 열어, 파일에 이미 존재하는 server 또는 pool 문 앞에 다음 라인을 추가하고 변경 사항을 저장한다
server 169.254.169.123 prefer iburst minpoll 4 maxpoll 4- chrony 서비스 재시작 및 169.254.169.123 IPv4 엔드포인트를 사용하여 시간을 동기화하고 있는지 확인한다
#서비스 재시작
sudo /etc/init.d/chrony restart
#시간 동기화 확인
chronyc sources -v
#chrony에서 보고된 시간 동기화 지표 확인
chronyc tracking데이터 세팅
방법 1) 부하테스트 툴 사용
맨 처음 계획은 일반적인 서비스 동작과 유사하게 하기 위해, 외부에서 요청이 오면 DB에서 데이터를 가져와 MQ를 거쳐 각 Consumer로 전송하는 것이었다. 이를 위해 Postman과 Jmeter에 필요한 내용을 설정하였다.
Postman (DB 세팅)

Test에 스크립트를 작성하면 테스트용 DB 데이터를 간단히 세팅할 수 있다.
// 초기 변수 설정
let counter = 1;
let maxRequests = 10000;
function sendRequest() {
if (counter <= maxRequests) {
// 요청을 보내는 부분
pm.sendRequest({
url: '0.0.0.0:8080/setDB', // API 엔드포인트
method: 'POST', // HTTP 메소드
header: {
'Content-Type': 'application/json',
},
body: {
mode: 'raw',
raw: JSON.stringify({
"id": counter,
"name": "testUser",
"email": "example@gmail.com",
}),
}
}, function (err, res) {
if (err) {
console.log(err);
}
// 요청 후 실행될 코드 (예: 응답 확인 및 결과 처리)
counter++;
setTimeout(sendRequest, 0.1); // 0.1초 후에 다음 요청 보냄
});
}
}
// 스크립트 실행
sendRequest();Jmeter (부하테스트 세팅)

구성은 위와 같다.
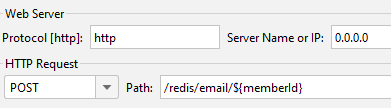
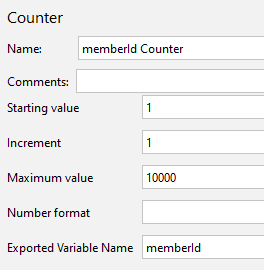
Http Request에서 ${memberId}를 변수로 주어 요청을 보내기 위해 Counter에서 memberId를 1에서 10,000까지 증가하도록 설정했다.
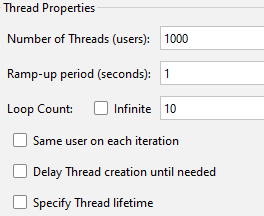
동시에 많은 유저가 접근하는 상황을 테스트하고 싶어 Ramp-up period를 1초로 설정했다. (잘못된 설정이었다. Ramp-up period는 쓰레드를 생성하는데 사용할 시간을 의미한다.)
문제점
Thread를 위와 같이 설정하면서도 과연 t2.small에서 버텨줄 수 있을까 하는 걱정이 있었는데.. 당연히도 요청의 반이 실패했다.
그리고 Ramp-up period를 설정하면 해당 시간 내에 요청을 보내는 것이 보장된다고 생각하였으나, 실제로는 그렇지 못했다. 처음 요청에서부터 마지막 요청이 완료되기까지 1분 이상의 시간이 요소되었다.
테스트 전체 시간을 제한하기 위해서는 Specify Thread lifetime을 체크하고, Duration을 설정해야 한다. 자세한 내용은 이후에 정리한 아래의 링크를 참고하면 좋다.
https://velog.io/@nwactris/Jmeter-설정
어찌되었든, 이러한 상황에서는 동시에 많은 데이터를 MQ로 전송하는 것을 제대로 테스트할 수 없다고 판단하였다. 따라서, 알람 서버(Producer) 내에서 스프링 배치를 통해 데이터를 MQ로 바로 전송하도록 계획을 변경하였다.
바뀐 테스트에서는 요청에서 응답까지의 시간을 확인하는 것이 아니므로 프로세스를 간소화하여 DB를 거치지 않고 스프링 배치에서 데이터를 생성하도록 하였다.
방법 2) 배치를 통한 데이터 전송
Spring Batch
@Bean
public Step step() {
return stepBuilderFactory.get("JobStep")
.<byte[], byte[]>chunk(chunkSize)
.reader(itemReader())
.writer(itemWriter())
.taskExecutor(taskExecutor())
.build();
}
@Bean
public TaskExecutor taskExecutor() {
SimpleAsyncTaskExecutor taskExecutor = new SimpleAsyncTaskExecutor();
taskExecutor.setConcurrencyLimit(threadSize);
return taskExecutor;
}
@StepScope
@Bean
public ItemReader<byte[]> itemReader() {
List<byte[]> content = new ArrayList<>();
byte[] randomBytes = new byte[byteSize]; //byte 수정
new SecureRandom().nextBytes(randomBytes);
for (int i = 0; i < listSize; i++) //데이터 개수 수정
content.add(randomBytes);
log.info("Complete creating all data: " + System.currentTimeMillis());
return new ListItemReader<byte[]>(content);
}
@StepScope
@Bean
public ItemWriter<byte[]> itemWriter() {
return randomBytes -> randomBytes.forEach(randomByte ->
notificationService.batchEmailMqWorker(randomByte));
}유저가 동시에 접근하는 상황을 가정하기 위해, TaskExecutor를 사용해 비동기로 동작하게 하였다.
ItemReader에서는 1kb 및 50kb 데이터를 byteSize에 따라 생성하고, 테스트할 데이터 개수를 환경 변수로 설정된 listSize만큼 추가하도록 하였다.
ItemWriter에서는 각 데이터를 Redis Stream, RabbitMQ, Kafka가 동작하는 함수로 보내도록 하였다.
byteSize, listSize, chunkSize, threadSize는 docker-compose.yml에서 환경변수로 받아와 상황 별 테스트를 쉽게 진행할 수 있도록 하였다.
배치로 1kb 데이터를 20,000건 전송하였을 때 rabbitMQ의 경우 Consumer에서 마지막 메시지를 수신한 시간 - Producer에서 첫 메시지를 송신한 시간이 4.31초 내에 이루어져, Jmeter를 사용할 때보다 병목이 개선된 환경에서 테스트를 진행할 수 있게 되었다.
궁금한 점
논문을 참고하다보면 부하테스트를 n초 내에 모든 요청이 완료됨을 보장하는 환경에서 진행하였다고 하는데, 내 경우 서버 성능이 낮아 요청시간이 보장되지 못한 것인지 의문이 든다.
