1. 과제 설계 배경 및 필요성
프로젝트에 알림 기능을 추가하면서, 운영 서버가 직접적으로 서드파티(알림 전송을 위한 api)와 연결되는 상황이 늘어났다. 서버의 안정성과 아키텍처에 관심이 있어 서드파티와 직접 연결되는 작업 서버를 운영 서버에서 따로 분리하고자 한다. 그러나, 거쳐야 하는 통신 단계가 하나 더 늘어나므로 데이터 송신 시간을 최소화해야 한다는 요구 사항이 발생한다.
또한 분산 서버에서 알림 시스템은 시나리오에 따라 각자 다른 요구 사항이 발생한다. 어떤 상황에서는 실시간성이나 신뢰성이 가장 핵심적인 요소로 간주되며, 다른 경우에는 대량의 메시지를 효율적으로 처리하는 것이 중요하다.
본 과제에서는 이러한 사용 사례들을 고려하여 Redis Stream, RabbitMQ, Kafka를 대상으로 성능 비교와 분석을 수행하고자 한다. 각 브로커의 메시지의 전달 속도, 신뢰성, Tail Latency와 같은 특성을 조사하여, 어떤 상황에서 어떤 메시지 브로커가 가장 적합한지를 심층적으로 이해하고 최적의 선택 기준을 도출하고자 한다.
추가적으로 Redis Pub/Sub에 비해 선행 연구가 부족한 Redis Stream을 탐구함으로서 Redis Stream의 장단점과 적합한 사용 환경을 제안해 보고자 한다.
2. 과제 수행 방법
AWS EC2로 아래와 같은 테스트베드를 구축하였다.
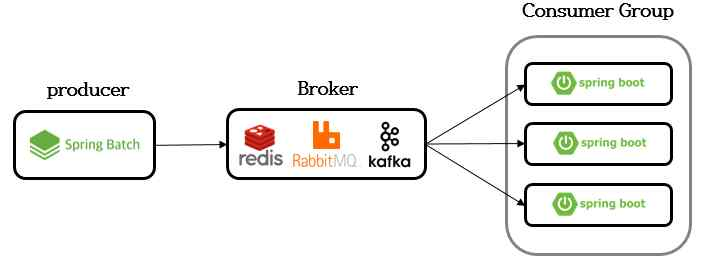 Fig. 1. Testbed Configuration
Fig. 1. Testbed Configuration
- 1 Producer : 1 vCPUs, 1.0 GiB of mem
- 1 Broker : 1 vCPUs, 2.0 GiB of mem
- 3 Consumers : 1 vCPUs, 1.0 GiB of mem (in same Consumer group)
실험에서 비교하는 메시지 브로커는 총 4 종류이다. 기본값 RDB만 설정되어 있는 Redis Stream, AOF 설정이 추가된 Redis Stream, 그리고 RabbitMQ와 Kafka와 이다.
메시지의 크기는 1kb와 50kb으로 설정했으며, 메시지 크기 별로 소량(1, 2, 3, 4, 5, 10건) 및 대량(100, 1,000, 10,000건) 발송하였다. Tail Latency는 더 큰 부하 상황에서 측정하기 위해 50kb 메시지를 20,000건 발송하였다.
메시지 각각에 대하여 Producer에서 메시지를 송신하기 직전의 시점, Broker의 큐에 메시지가 저장된 시점, Consumer가 메시지를 수신한 시점의 Time Stamp를 남겨 저장하였다. 그리고 해당 데이터를 기반으로 아래와 같은 요소를 측정하였다.
- N개의 메시지 전송에 소요된 전체 지연 시간.
- 하나의 메시지가 Producer에서 출발해 Broker에 저장되는 데 소요된 시간의 평균.
- 하나의 메시지가 Broker 서버에 저장된 시점부터 Consumer에 도착하기까지 소요된 시간의 평균.
- 현재 메시지와 직전 메시지와의 Produce Term, Consume Term.
- p9999(상위 0.01%)까지의 Tail Latency.
신뢰성 측면에서, 해당 실험을 진행하면서 Redis Stream, RabbitMQ, Kafka 모두 유실되는 메시지가 없는 것을 확인하였다.
3. 성능 분석 결과
1) 전체 지연 시간
 Fig. 2. 1kb, 50kb 메시지의 전체 지연 시간
(메시지 1~10건)
Fig. 2. 1kb, 50kb 메시지의 전체 지연 시간
(메시지 1~10건)
Fig. 2는 메시지를 1~10건 발송했을 때 1kb, 50kb 크기 별 메시지의 전체 지연 시간을 비교하고 있다. 한 번에 전송하는 메시지 개수가 10개 이하일 때, Redis Stream의 지연 시간 성능이 가장 좋다. 메시지를 한 개 보낼 때의 지연 시간은 1kb 6ms, 50kb 10.3ms로 RabbitMQ의 1kb 73.7ms, 50kb 86.3ms과 비교해 보아도 현저히 낮다.
그러나 Redis Stream은 단일 스레드의 영향으로 메시지 개수가 증가함에 따라 지연 시간도 비례해 증가하는 모습을 보인다. 메시지 1건과 10건의 송수신 지연 시간 차이가 약 7배인 Redis Stream과 달리 RabbitMQ와 Kafka는 1kb의 메시지의 경우, 10건을 송신할 때 약 1.3배의 시간이 더 소요되었다. 50kb의 메시지를 전송한 경우에는 지연 폭이 조금 더 커져 RabbitMQ는 약 1.6배, Kafka는 약 1.8배의 지연 시간 차이가 발생했다.
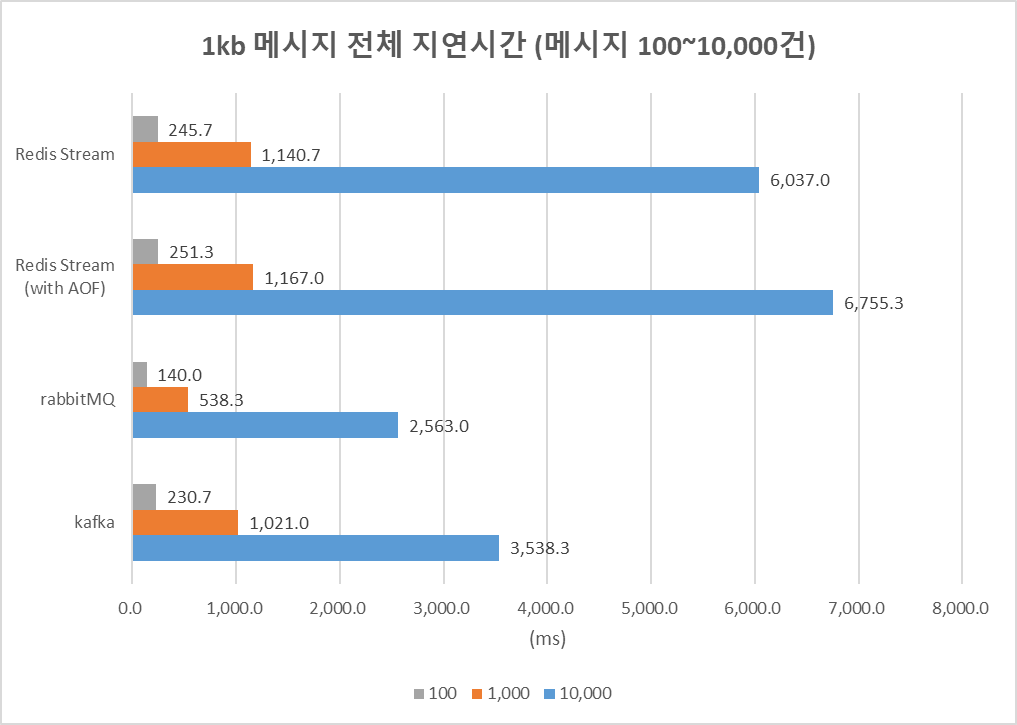 Fig. 3. 1kb 메시지의 전체 지연 시간
(메시지 100, 1,000, 10,000건)
Fig. 3. 1kb 메시지의 전체 지연 시간
(메시지 100, 1,000, 10,000건)
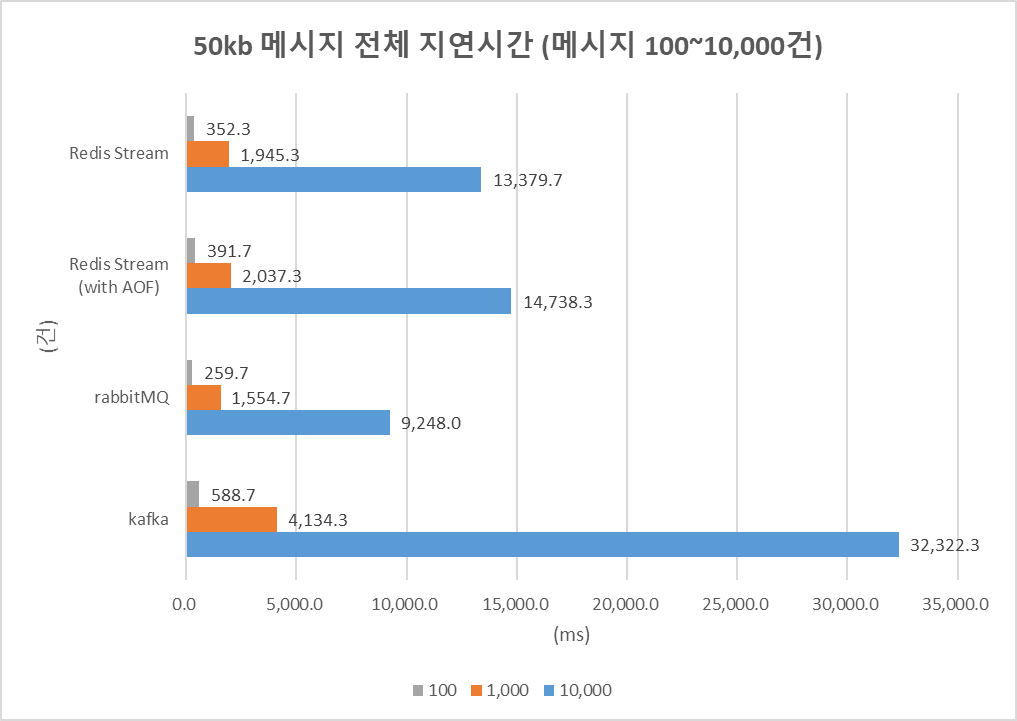 Fig. 4. 50kb 메시지의 전체 지연 시간
(메시지 100, 1,000, 10,000건)
Fig. 4. 50kb 메시지의 전체 지연 시간
(메시지 100, 1,000, 10,000건)
소량의 데이터를 전송할 때와는 달리 Fig. 3에서 100건 이상, 대량의 1kb 메시지를 전송할 때는 Redis Stream의 전체 지연 시간 성능이 가장 좋지 않은 것을 확인할 수 있다. 대량 전송 상황에서 메시지의 크기 및 개수에 상관없이 가장 빠른 성능을 보인 RabbitMQ와 비교하면, 메시지 1,000건 전송과 10,000건 전송에서 Redis Stream은 2배 이상 시간이 더 소요되었다.
50kb를 전송하는 Fig. 4에서는 Kafka의 지연 시간이 가장 길었으며, 10,000건의 메시지를 전송하는 경우에는 32,332.3ms나 소요되었다.
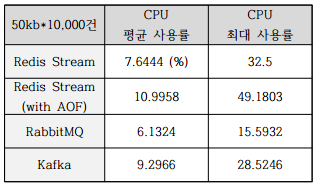 Fig. 5. CPU 평균, 최대 사용률
Fig. 5. CPU 평균, 최대 사용률
한편, Fig. 2, 3, 4에서 AOF를 적용한 Redis Stream의 수행속도가 AOF를 적용하지 않은 경우와 비교했을 때, 큰 차이가 나지 않은 것을 볼 수 있다. 따라서 메시지의 신뢰성이 최우선이면서도 부가적으로 빠른 전송을 필요로 하는 상황에서 AOF를 적용하는 것은 좋은 선택이 될 수 있다. 다만, 브로커 별 CPU 사용률을 나타낸 Fig. 5를 참고하면 Redis Stream에 AOF를 적용하면 CPU의 부하가 높아짐을 알 수 있다.
2) 구간별 평균 지연 시간
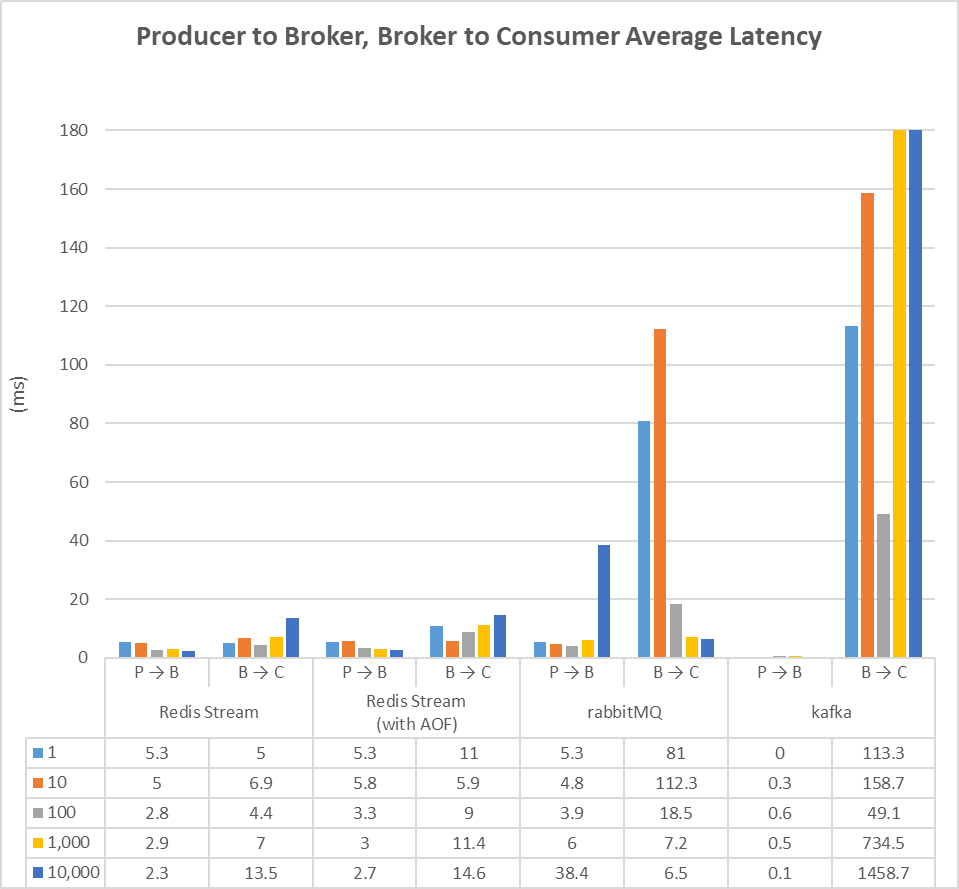 Fig. 6. Producer to Broker, Broker to Consumer
평균 지연 시간
Fig. 6. Producer to Broker, Broker to Consumer
평균 지연 시간
Fig. 6은 Producer에서 메시지가 출발한 시간, Broker에 저장된 시간, Consumer가 메시지를 받은 시간을 구간별로 나누어 평균 지연 시간을 구하고 있다. 그래프를 보면 Redis Stream이 송신되는 시점부터, 수신되는 시점까지 개별 메시지의 평균 지연 시간이 가장 짧은 것을 볼 수 있다. 특히, Broker에서 Consumer로 넘어가는 구간에서, 메시지를 10,000건 전송하는 경우를 제외하면 다른 메시지 브로커에 비해 성능이 매우 좋다.
3) Tail Latency
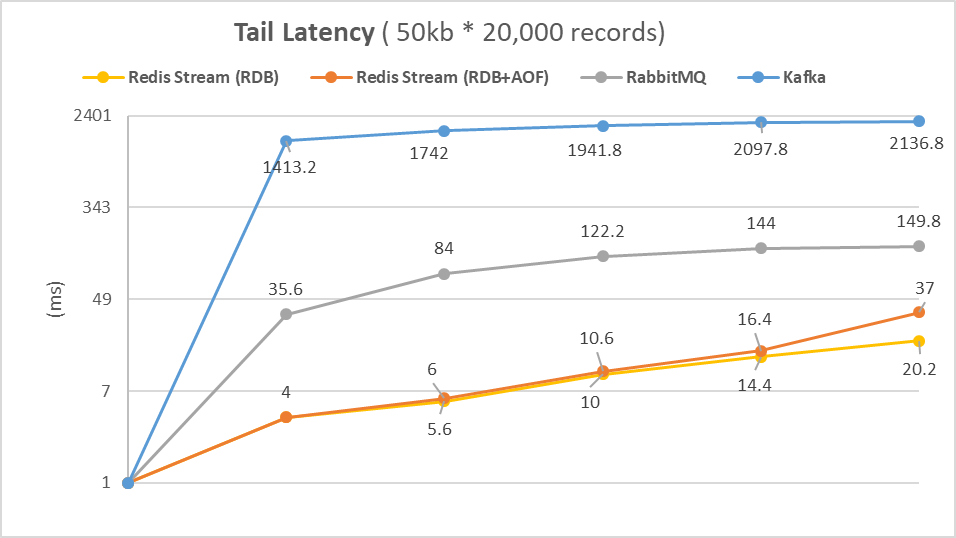 Fig. 7. Tail Latency
Fig. 7. Tail Latency
Fig. 7은 p50, p90, p99, p999 p9999에서의 Tail Latency를 비교한다. 우선 Kafka는 p50에서의 값이 1413.2ms로 전체 메시지의 50%는 약 1.4초 내에 도착하였음을 알 수 있다. p9999의 값은 2136.8ms로 측정되었는데, 이러한 결과로 미루어보아 개별 메시지의 실시간성이 중요한 환경에서 Kafka는 메시지가 일정 지연 시간 내에 도착하는 것을 보장하지 못할 위험이 있다.
RabbitMQ는 전체 메시지의 99.99%가 149.8ms 안에 도달하기 때문에 비교적 안정적인 성능을 보인다. 하지만 Redis Stream의 p50은 4ms, p9999는 20.2로, AOF를 적용하여도 RabbitMQ보다 4배 빠른 37ms의 도달 시간을 보장한다.
4) Produce Term & Consume Term
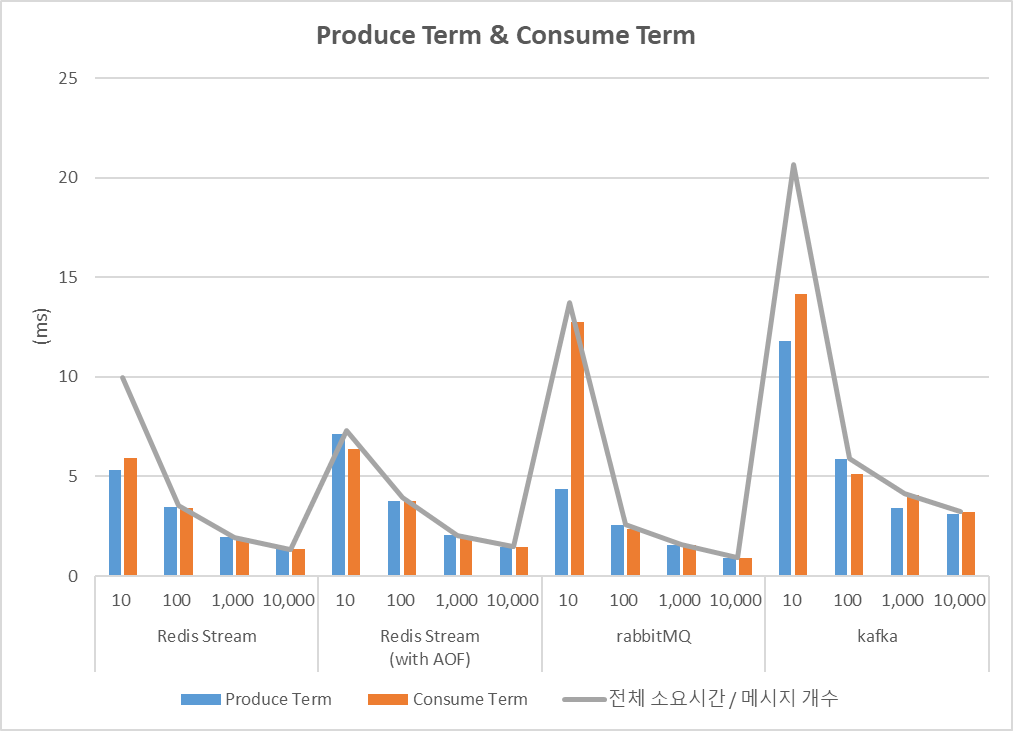 Fig. 8. 평균 Produce Term & Consume Term
Fig. 8. 평균 Produce Term & Consume Term
개별 메시지의 지연 시간은 Redis Stream이 압도적으로 좋은 성능을 보이는 반면, 전체 메시지가 모두 도달하는 데에는 시간이 많이 소요되는 이유를 Fig. 8를 통해 분석할 수 있다.
Fig. 8에서 막대 그래프는 현재 메시지와 바로 직전 메시지 간 Produce, Consume 되는 시간 간격(Term)의 평균값이다. 선형 그래프는 ‘전체 지연 시간 ÷ 전달한 메시지 개수‘ 의 값을 나타내는데, 이 값은 Consume Term과 Produce Term 중 병목현상이 발생하는 구간의 값과 흐름이 거의 일치함을 볼 수 있다.
4. 결론
해당 과제에서는 선행 연구가 부족했던 Redis Stream을 중점으로 하여, 다양한 메시지 브로커가 어떤 상황에 더 적합한지 다양한 지표를 통해 알아보았다.
예를 들어, 일반적으로 SNS의 활동(좋아요, 댓글 등)으로 개별 알람이 오는 환경이나, 인증을 위한 알림 송신처럼 적은 개수의 메시지를 신속하고 신뢰성있게 전달하려는 경우 Redis Stream을 사용하는 것이 가장 적절하다. ack 매커니즘으로 처리되지 못한 메시지를 다시 처리할 수 있으며, 영속성을 보장하기 위해 AOF 설정을 추가할 수도 있다.
물론, AOF는 로그 파일을 추가하는 것이기 때문에 디스크 공간을 과도하게 사용하지 않도록 설정하고, 높은 CPU 사용률로 서버가 다운되지 않도록 CPU의 한계를 명확히 파악하거나, CPU의 개수를 추가하는 부수적인 방법들을 고려해야 한다.
대량의 메시지를 처리하는 환경에서는 RabbitMQ가 가장 빠르게 데이터를 전달하였다. 특히 본 연구의 테스트베드와 유사한 Pub/Sub 구조에서는 RabbitMQ를 선택하는 것이 성능상 이점을 가져온다. 알람 시스템의 실제 사례를 예로 들어본다면, 배치로 모든 사용자에게 한 번에 동일한 알람을 보내야 할 때 유용하게 활용할 수 있을 것이다.
본 과제의 모든 상황에서 낮은 성능을 보인 Kafka는 Muti Producer 및 Multi Consumer의 분산 환경에서 대규모 데이터를 주고받기 위한 목적으로 설계되었으므로, 더 복잡한 구조의 환경에서 최적의 성능을 보일 것으로 예상된다.
5. 개선할 점
이번 과제에서는 비용의 부담으로 비교적 간단한 환경에서 테스트를 진행하였다.
- 브로커 서버의 코어 수가 1vCPU였으므로, 일반적으로 코어 당 쓰레드가 하나씩 할당되는 것이 최적값임을 고려하면 RabbitMQ와 Kafka에서 멀티스레드를 제대로 활용하지 못했다고 할 수 있다.
- 또한 실제 서비스의 알림 시스템을 고려하면 fcm, sms, email 등 각각의 서드파티와 연결된 서버와 그에 따른 큐 및 클러스터링이 필요할 것이다.
