Kafka란
Apache Kafka는 실시간으로 기록 스트림을 게시, 구독, 저장 및 처리할 수 있는 분산형 데이터 스트리밍 플랫폼(distributed event streaming platform)입니다.
간단히 말해 A지점에서 B지점까지 이동하는 것뿐만 아니라 A지점에서 Z지점을 비롯해 필요한 모든 곳에서 대규모 데이터를 동시에 이동할 수 있습니다.
https://www.redhat.com/ko/topics/integration/what-is-apache-kafka
MSA처럼 여러 개의 서버가 통신해야 하는 상황에서, 각 서버마다 연결 라인을 구축해야 한다면 복잡도가 기하 급수적으로 증가할 것이다.
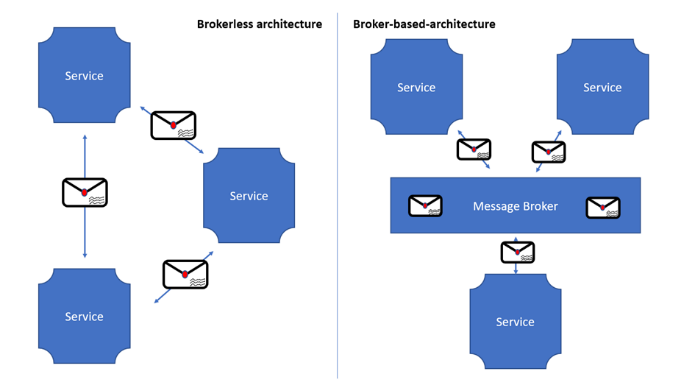
따라서 오른쪽과 같이 MQ(Message Broker)를 이용해 전달 역할을 담당하는 서버를 두면 이 문제를 해결할 수 있다.

Kafka는 MQ의 역할에서 한 발 더 나아가, Multi-Producer & Multi-Consumer 환경에서 많은 데이터를 하나의 대규모 Kafka 클러스터에 집중시키는 데이터 허브 역할 또한 담당한다. 이에 대해서는 아키텍쳐를 이해한 후 다시 설명하고자 한다.
아키텍쳐
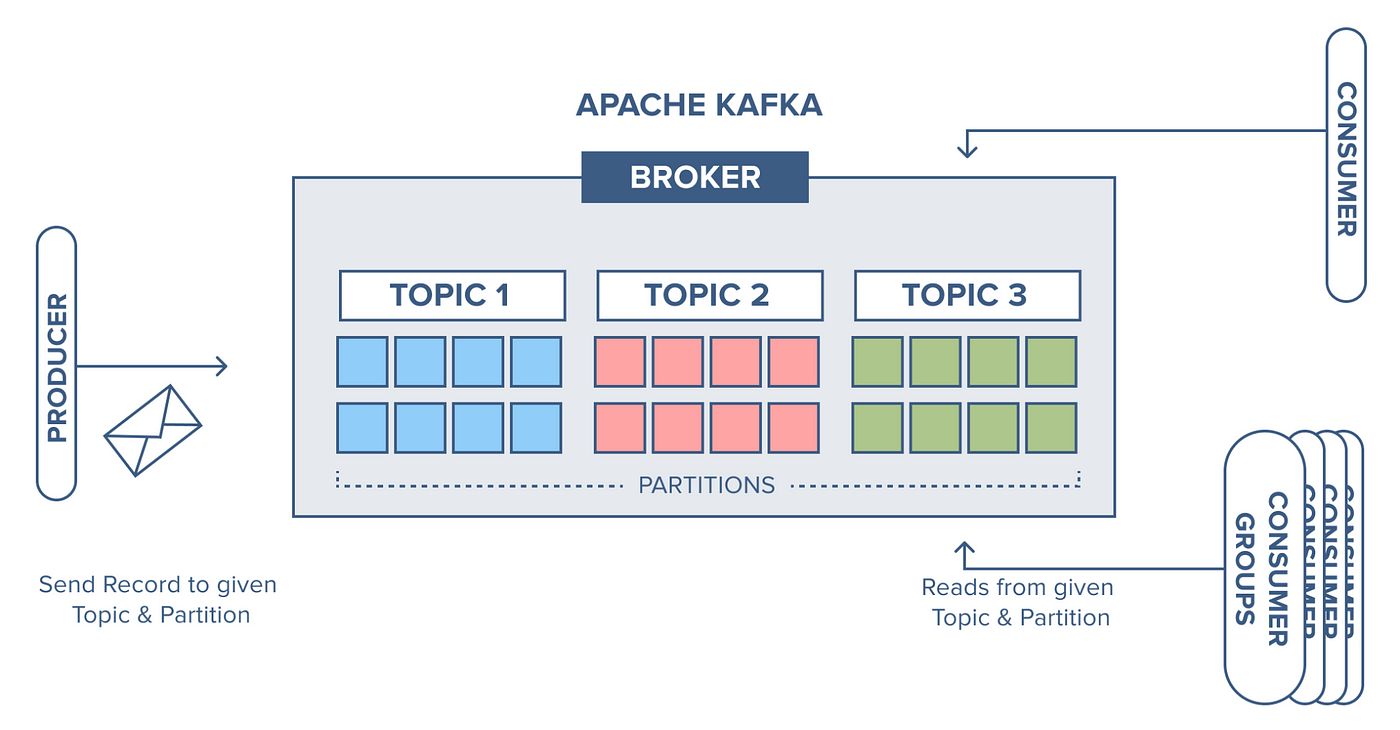
- Producer: 메시지를 생성하고 발송하는 주체
- Consumer: 메시지를 수신하고 소비하는 주체
- Consumer Group: Consumer들의 논리적 그룹.
- Broker: 개별 카프카 서버, 하나의 노드에 여러 브로커를 띄울 수 있다.
- Kafka Cluster: 카프카 서버(Broker)들의 모임. 확장성과 고가용성을 위해 클러스터를 구성한다.
- Zookeeper(⭐필수): 카프카 클러스터 정보 및 분산처리 관리 등 메타 데이터를 저장한다. 카프카(Broker)보다 먼저 실행되어 있어야 한다.
Kafka Cluster와 Zookeeper
Kafka Cluster는 다수의 브로커 정보를 관리하고, 효과적인 Leader election을 수행하기 위해 Zookeeper를 사용한다.
클러스터 내에서 broker가 되는 개별 Kafka Server는 자신의 식별자로 broker.id를 부여받으며, Producer에서 전달된 메시지를 저장할 위치 정보와 클러스터 메타정보를 저장 및 관리할 Zookeeper 연결 정보가 지정된다.
클러스터 내의 특정 broker에 fail이 발생한 경우, 컨트롤러는 Zookeeper에 변경된 Leader Partition정보를 먼저 저장하고 업데이트를 수행한다.
Broker 내 구성
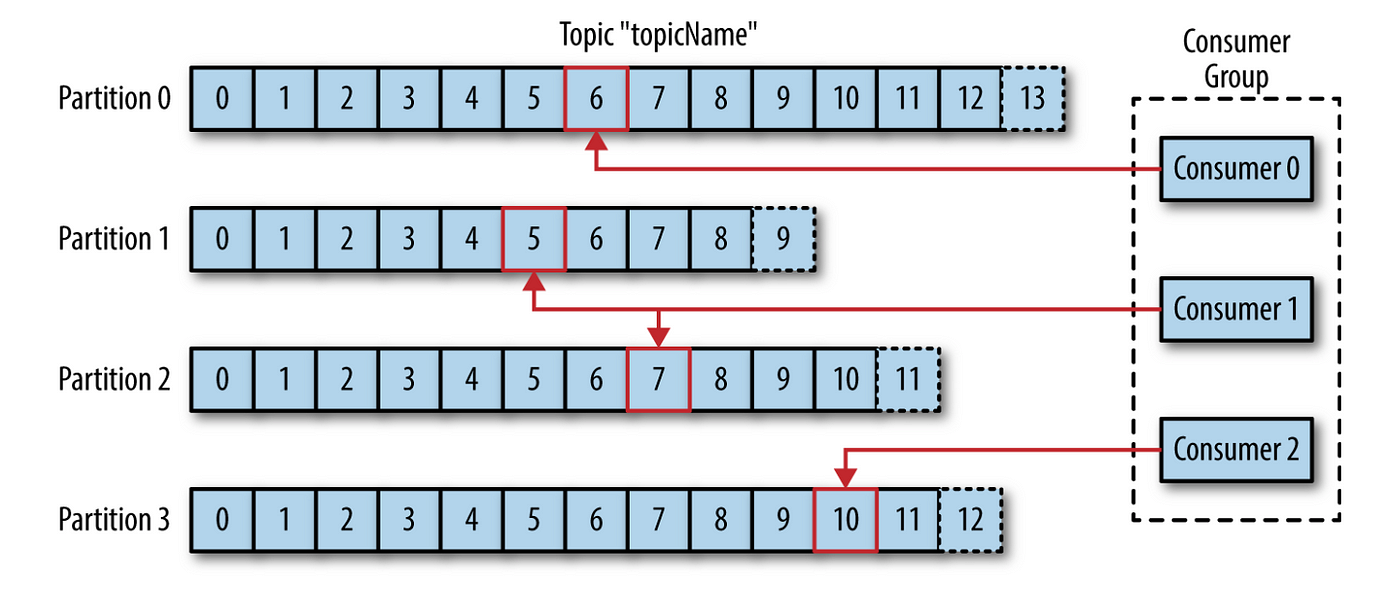
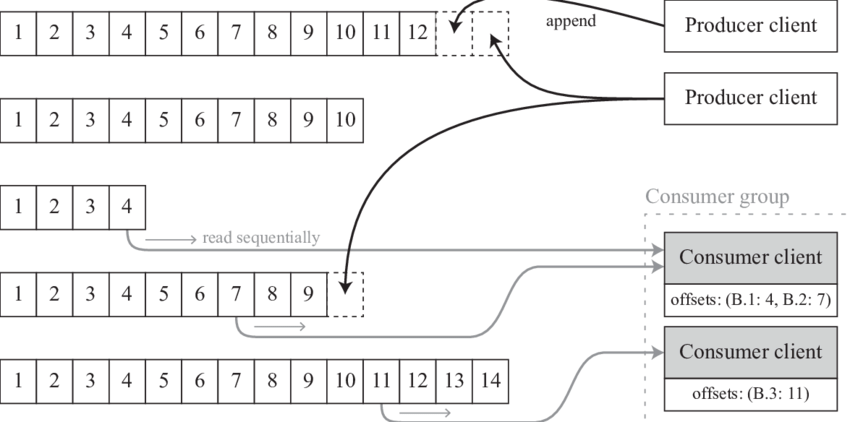
- Topic: 메시지 분류 기준. Producer는 특정 Topic에 메시지를 송신하고, Consumer는 구독하는 Topic의 메시지를 수신한다.
- Partition: 다른 MQ의 Queue와 유사한 개념. 한 개의 토픽은 한 개 이상의 파티션으로 구성된다. Kafka는 파일 시스템에 저장되는데, 파티션은 그 중 append-only 파일이다.
Partition의 메시지는 일정 기간 동안 삭제되지 않으며, 따라서 한 Consumer가 읽은 메시지를 다른 Consumer도 읽을 수 있다. - Offset: Consumer는 Offset 기준으로, 마지막 커밋 시점부터 메시지를 순서대로 읽어 처리한다. Offset은 Consumer Group 별로 관리된다.
특징
영속성 및 내결함성
File System에 저장
Kafka는 OS 레벨에서 파일 시스템을 최대한 활용하여, 빠른 속도와 영속성을 동시에 제공한다.
- OS에서는 File I/O 성능 향상을 위해 페이지 캐시 영역을 메모리에 따로 생성하여 사용하므로, 한번 읽은 파일은 메모리에 저장되어 처리량이 높다.
메시지 삭제
RabbitMQ에서는 Consumer가 메시지를 소비하면 큐에서 메시지를 바로 삭제하는 것과 달리, Kafka는 메시지를 보존 기간(Time To Live. TTL)이 만료될 때까지 보관한다. 따라서 Consumer는 규정된 기간 내에 언제든지 스트리밍된 데이터를 다시 처리할 수 있다.
고성능
Zero Copy
Zero Copy를 통해 디스크 버퍼에서 네트워크 버퍼로 직접 데이터를 복사해 속도가 빠르다. OS에서 디스크->네트워크로 데이터를 전송할 때, 전통적으로는 아래의 과정으로 진행된다.
- 해당 데이터를 커널 읽기 버퍼로 복사
- 애플리케이션 읽기 버퍼로 복사
- 다시 데이터를 사용자 공간에서 커널 공간의 소켓 버퍼로 복사
- 소켓 버퍼에서 네트워크 버퍼로 전송
이 때, 사용자 공간으로 복사하는 과정을 없애 비효율을 제거한 것이 Zero Copy 이다.
Batch 기능을 제공해 동시 처리량 증가
- Producer: 일정 크기만큼 메시지를 모아서 전송
- Consumer: 최소 크기만큼 메시지를 모아서 읽어온다.
확장성(scale out)
브로커/파티션/컨슈머를 추가해 수평 확장이 쉽게 가능하다.
고가용성(HA - High Availability)
Replication
토픽 내 파티션의 복제본으로, replication-factor로 개수를 지정할 수 있다.
replication-factor 수 만큼 파티션이 각 브로커에 생긴다.
Partition 단위
Replication은 파티션 단위로 각 서버들에 분산되어 복제되고, 장애가 발생하면 파티션 단위로 fail over가 수행된다.
Leader & Follower
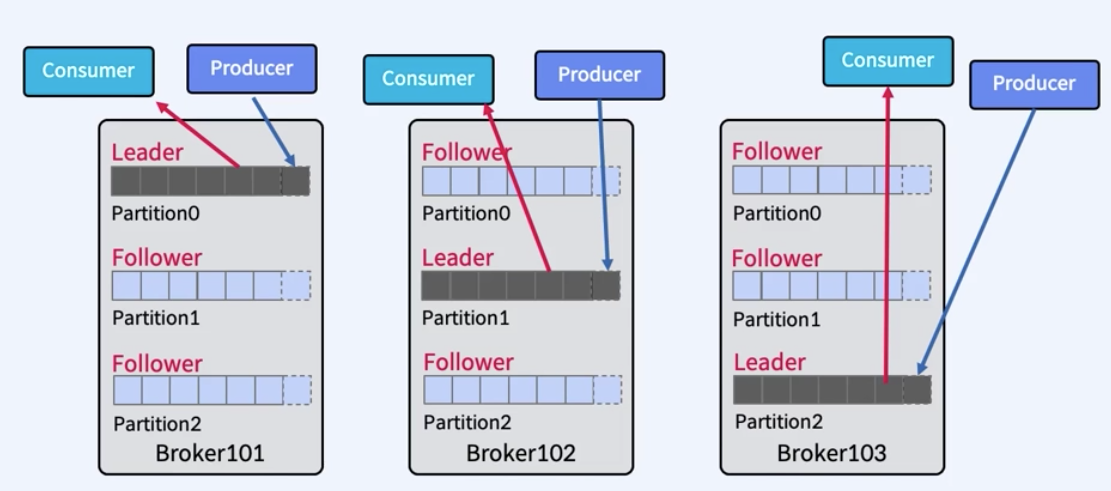
Producer와 Consumer는 Leader에서만 Write/Read를 수행한다.
Follower는 장애를 대비한 Leader의 복사본이며, Leader에서 장애가 발생하면 Follower 중에서 리더를 선출한다.
- replication-factor가 1일 경우: Leader만 존재
- 2 이상일 경우: Leader 1개 + Follower (n-1)개
ISR(In-Sync Replicas)
Follower가 Leader 파티션의 데이터를 비동기적으로 복제한다면,
ISR은 복제본 중에서 리더 파티션과 동기화된 복제본의 집합을 나타낸다.
ISR은 안정적이고 신뢰할 수 있는 데이터 복제를 보장한다.
Kafka 사용 시기
https://aws.amazon.com/ko/compare/the-difference-between-rabbitmq-and-kafka/
이벤트 스트림 재생 및 로그 처리
Kafka는 수신된 데이터를 다시 분석해야 하는 애플리케이션에 적합하다. 보존 기간 내에 스트리밍 데이터를 여러 번 처리할 수도 있고 로그 파일을 수집하여 분석할 수도 있다.
실시간 데이터 처리
Kafka는 메시지를 스트리밍할 때 지연 시간이 매우 짧기 때문에 스트리밍 데이터를 실시간으로 분석하는 데 적합하다. 예를 들어 Kafka를 분산 모니터링 서비스로 사용하여 온라인 트랜잭션 처리 알림을 실시간으로 생성할 수 있다.
데이터 허브
https://engineering.linecorp.com/ko/blog/how-to-use-kafka-in-line-1
"LINE에서 Kafka를 사용하는 방법"을 읽어보면 데이터 허브로서 어떠한 장점이 있는지 보다 명확히 파악할 수 있다.
이 방법은 어떤 서비스에 데이터 업데이트가 발생했을 때, 해당 데이터를 사용하는 다른 여러 서비스에 전파하기 위한 허브로 사용하는 방법입니다. 구체적인 예를 들어 설명하겠습니다.
LINE에서는 사용자의 친구 관계를 데이터로 저장하고 있습니다. 예를 들어 어떤 사용자 A가 다른 사용자 B를 친구로 추가했을 때, LINE 내부에서는 그에 따른 처리를 수행하고 업데이트된 관계를 Kafka의 topic에 이벤트로 입력합니다. 이 이벤트는 사용자 그래프를 활용해서 제공하는 통계 시스템이나 타임라인 등의 서비스에서 사용합니다.
Docker로 Kafka 클러스터 구성
Kafka 클러스터 내/외부 통신 구분
Producer에서는 원하는 Topic에 데이터를 보내기 위해, Topic이 저장된 위치를 알아야 하며 이 과정은 아래의 순서를 통해 이루어진다.
- Metadata를 Kafka Broker 중 하나에게 요청한다.
- 요청을 받은 Broker는 요청자가 원하는 Topic이 위치한 서버 리스트를 보낸다.
- Producer는 서버 리스트를 참고해, 서버에 직접 접근하여 전송한다.
이 때, 동일 클러스터 내의 Broker는 서로의 hostname(클러스터 내에서 서로 식별할 수 있는 고유한 값) 및 정보를 사전에 알고 있다. 따라서 클러스터 내부에서 Produce & Consume을 진행하면 Broker는 간단히 hostname과 port만 반환해도 서로 접근이 가능하다.
하지만, 외부에서 Kafka 클러스터에 접근할 때는 요청자가 hostname의 정보를 가지고 있지 않기 때문에 에러가 발생한다.
Name or service not known:kafka-1:Could not resolve host name.
따라서, Kafka는 옵션 값 설정을 통해 내/외부 통신을 구분해 서버 주소를 반환하도록 해야한다.
해당 내용은 server.properties나, docker-compose.yml 작성시 environment에 추가하면 된다.
- listeners: Kafka가 서비스를 제공하는 주소(여러개 등록 가능)
- advertised.listeners: 요청자(Client)에게 Metadata와 함께 반환할 서버 주소
listeners 및 advertised.listeners 설정
hostname이 kafka-3인 브로커에서 39092:39092, 39094:39094로 서비스 port에 맞게 port forwarding을 진행한 예시이다.
AA는 클러스터 내부, BB는 클러스터 외부(Host machine) 통신에 사용될 예정이다.
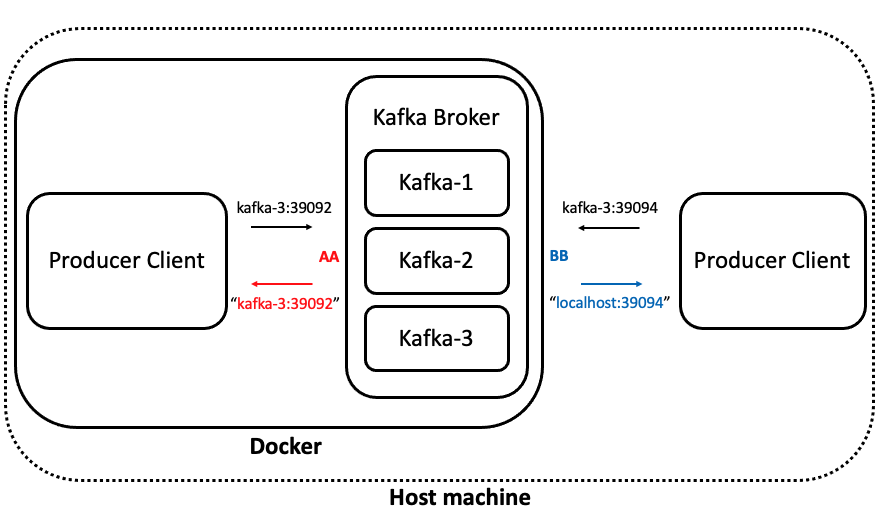
- KAFKA_LISTENERS_SECURITY_PROTOCOL_MAP: AA:PLAINTEXT,BB:PLAINTEXT
- KAFKA_LISTENERS: AA://kafka-3:39092,BB://kafka-3:39094
- KAFKA_ADVERTISED_LISTENERS: AA://kafka-3:39092,BB://localhost:39094
- KAFKA_INTER_BROKER_LISTENER_NAME: AAKAFKA_LISTENER_SECURITY_PROTOCOL_MAP
이를 통해 구분하고 싶은 네트워크 추가와 보안 프로토콜을 정할 수 있다.
- 보안 프로토콜: PLAINTEXT, SSL, SASL 등
- 형식: {listener 이름}:{보안 프로토콜}
위의 예시에서는 AA와 BB라는 이름의 listener를 추가한 것이다.
KAFKA_LISTENERS
등록한 listener마다 서버 주소를 설정해, 어떤 네트워크를 사용했는지 Kafka가 구분할 수 있다.
위의 예시에서는, kafka-3 hostname에 39092 port로 들어온 서비스는 AA listener로 구분할 수 있게 된다.
KAFKA_ADVERTISED_LISTENERS
KAFKA_LISTENERS에서 구분한 listener에 맞게 다시 요청자(Client)에게 반환시킬 서버 주소로, Client는 이 서버 주소를 받아 직접 Topic을 Producer 및 Consume한다.
예시에서, AA는 내부 통신을 의도했으므로 hostname을 반환했으며
BB는 Docker 외부, 즉 Host machine과 통신을 의도했으므로 localhost(IP 주소)를 작성했다.
KAFKA_INTER_BROKER_LISTENER_NAME
내부 통신을 위한 listener가 무엇인지, Kakfa가 사전에 알 수 있도록 작성한다.
❓그런데, BB는 외부와 통신하기 위해 localhost를 반환했는데, 왜 listener에 kafka-3 hostname을 굳이 직접 명시했을까?
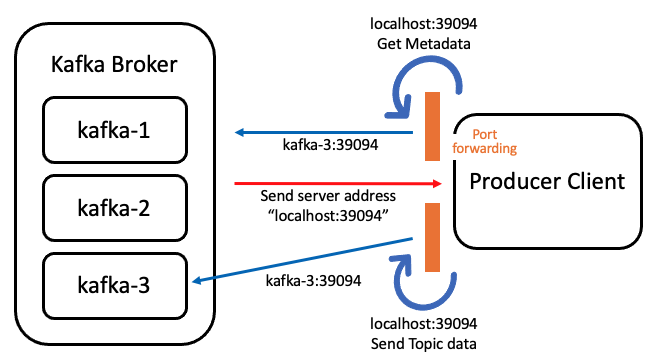
KAFKA_ADVERTISED_LISTENERS(BB에서는 localhost:39094)를 통해 클러스터와 외부의 요청자의 port forwarding이 이루어지며, Kafka 클러스터 내에서는 결국 hostname 요청 값만 고려(kafka-3:39094)하기 때문에 listener에 hostname 명시가 필요하다.
server.properties
위의 내용을 종합해보면 네트워크 연결을 다음과 같이 설정할 수 있다.
내부 클라이언트에서만 접속 가능하게 설정
- listeners=PLAINTEXT://{사설IP}:9092
- advertised.listeners=PLAINTEXT://{사설IP}:9092
외부 클라이언트에서만 접속 가능하게 설정
- listeners=PLAINTEXT://0.0.0.0:9092
- advertised.listeners=PLAINTEXT://{공인IP}:9092
- consumer.properties와 producer.properties의 bootstrap서버 주소 변경 필요
(네트워크 설정 이슈로) 내/외부 클라이언트 모두 접속 가능하게 설정 해야 할 경우 - 방법 1
- listeners=PLAINTEXT://0.0.0.0:9092
- advertised.listeners=PLAINTEXT://{공인IP or 도메인}:9092
(네트워크 설정 이슈로) 내/외부 클라이언트 모두 접속 가능하게 설정 해야 할 경우 - 방법 2
- listener.security.protocol.map=EXTERNAL:PLAINTEXT,INTERNAL:PLAINTEXT
- listeners=INTERNAL://{사설IP}:9092,EXTERNAL://{공인IP}:9093
- advertised.listeners=INTERNAL://{사설IP or 도메인}:9092,EXTERNAL://{공인IP or 도메인}:9093
Broker에서 Kafka 실행
Zookeeper 3개, Kafka 3개인 Docker container를 생성하는 docker-compose.yml은 아래와 같다.
version: '2'
services:
zookeeper-1:
image: confluentinc/cp-zookeeper:latest
hostname: zookeeper-1
ports:
- "12181:12181"
environment:
ZOOKEEPER_SERVER_ID: 1
ZOOKEEPER_CLIENT_PORT: 12181
ZOOKEEPER_TICK_TIME: 2000
ZOOKEEPER_INIT_LIMIT: 5
ZOOKEEPER_SYNC_LIMIT: 2
ZOOKEEPER_SERVERS: zookeeper-1:12888:13888;zookeeper-2:22888:23888;zookeeper-3:32888:33888
zookeeper-2:
image: confluentinc/cp-zookeeper:latest
hostname: zookeeper-2
ports:
- "22181:12181"
environment:
ZOOKEEPER_SERVER_ID: 2
ZOOKEEPER_CLIENT_PORT: 12181
ZOOKEEPER_TICK_TIME: 2000
ZOOKEEPER_INIT_LIMIT: 5
ZOOKEEPER_SYNC_LIMIT: 2
ZOOKEEPER_SERVERS: zookeeper-1:12888:13888;zookeeper-2:22888:23888;zookeeper-3:32888:33888
zookeeper-3:
image: confluentinc/cp-zookeeper:latest
hostname: zookeeper-3
ports:
- "32181:12181"
environment:
ZOOKEEPER_SERVER_ID: 3
ZOOKEEPER_CLIENT_PORT: 12181
ZOOKEEPER_TICK_TIME: 2000
ZOOKEEPER_INIT_LIMIT: 5
ZOOKEEPER_SYNC_LIMIT: 2
ZOOKEEPER_SERVERS: zookeeper-1:12888:13888;zookeeper-2:22888:23888;zookeeper-3:32888:33888
kafkacat:
image: confluentinc/cp-kafkacat
command: sleep infinity
kafka-1:
image: confluentinc/cp-kafka:latest
ports:
- "19092:19092"
- "19094:19094"
depends_on:
- zookeeper-1
- zookeeper-2
- zookeeper-3
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper-1:12181,zookeeper-2:12181,zookeeper-3:12181
KAFKA_LISTENERS: INTERNAL://kafka-1:19092,EXTERNAL://kafka-1:19094
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka-1:19092,EXTERNAL://localhost:19094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL
kafka-2:
image: confluentinc/cp-kafka:latest
ports:
- "29092:29092"
- "29094:29094"
depends_on:
- zookeeper-1
- zookeeper-2
- zookeeper-3
environment:
KAFKA_BROKER_ID: 2
KAFKA_ZOOKEEPER_CONNECT: zookeeper-1:12181,zookeeper-2:12181,zookeeper-3:12181
KAFKA_LISTENERS: INTERNAL://kafka-2:29092,EXTERNAL://kafka-2:29094
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka-2:29092,EXTERNAL://localhost:29094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL
kafka-3:
image: confluentinc/cp-kafka:latest
ports:
- "39092:39092"
- "39094:39094"
depends_on:
- zookeeper-1
- zookeeper-2
- zookeeper-3
environment:
KAFKA_BROKER_ID: 3
KAFKA_ZOOKEEPER_CONNECT: zookeeper-1:12181,zookeeper-2:12181,zookeeper-3:12181
KAFKA_LISTENERS: INTERNAL://kafka-3:39092,EXTERNAL://kafka-3:39094
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka-3:39092,EXTERNAL://localhost:39094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL- Zookeeper가 실행된 후 Kafka가 실행되어야 한다. 따라서, kafka에
depend-on을 zookeeper로 설정한다.
docker exec -it broker-server_kafka_1 kafka-topics --create --topic email --bootstrap-server ${ip}:9092 --replication-factor 1 --partitions 3실행된 도커 서버에 Topic, Partition, Replication을 위와 같이 설정할 수 있다.
Spring 적용
Producer & Consumer 공통
build.gradle 설정
implementation 'org.springframework.kafka:spring-kafka'Producer
1. application.yml 설정
spring
kafka:
producer:
bootstrap-servers: ${KAFKA_URL}:90922. Config class 작성
@EnableKafka
@Configuration
public class KafkaProducerConfig {
@Value("${spring.kafka.producer.bootstrap-servers}")
private String servers;
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> properties = new HashMap<>();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return new DefaultKafkaProducerFactory<>(properties);
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}3. Producer class 작성
@Service
@Slf4j
@RequiredArgsConstructor
public class KafkaProducer {
private final KafkaTemplate<String, String> kafkaTemplate;
public Object send(String topic, Object dto) throws JsonProcessingException {
ObjectMapper objectMapper = new ObjectMapper();
String jsonInString = objectMapper.writeValueAsString(dto);
jsonInString += LocalDateTime.now().atZone(ZoneId.systemDefault()).toInstant().toEpochMilli();
Message<String> message = MessageBuilder
.withPayload(objectMapper.writeValueAsString(dto))
.setHeader(KafkaHeaders.TOPIC, topic)
//claimTime은 테스트 위해 custom해 추가한 것으로, 제거해도 무방
.setHeader("claimTime", System.currentTimeMillis())
.build();
kafkaTemplate.send(message);
return dto;
}
}4. 서비스 로직 작성
@Service
@RequiredArgsConstructor
public class ServiceImpl {
private final KafkaProducer kafkaProducer;
public void send(byte[] content) throws JsonProcessingException {
ObjectMapper objectMapper = new ObjectMapper();
String value = objectMapper.writeValueAsString(content);
HashMap<String, String> map = new HashMap<>();
map.put("info", value);
String record = objectMapper.writeValueAsString(map);
kafkaProducer.send(emailTopic, record);
}
}Consumer
1. application.yml 설정
spring
kafka:
consumer:
bootstrap-servers: ${KAFKA_URL}:9092
#아래 내용은 선택
topic: "email"
group: "group.example"2. Config class 작성
@EnableKafka
@Configuration
public class KafkaConsumerConfig{
@Value("${spring.kafka.consumer.bootstrap-servers}")
private String servers;
@Value("${spring.kafka.group}")
private String group;
@Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> properties = new HashMap<>();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
properties.put(ConsumerConfig.GROUP_ID_CONFIG, emailGroup);
properties.put(ConsumerConfig.CLIENT_ID_CONFIG, UUID.randomUUID().toString());
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return new DefaultKafkaConsumerFactory<>(properties);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory
= new ConcurrentKafkaListenerContainerFactory<>();
kafkaListenerContainerFactory.setConsumerFactory(consumerFactory());
return kafkaListenerContainerFactory;
}
}3. 서비스 로직 작성
@Service
@RequiredArgsConstructor
public class KafkaConsumer {
@KafkaListener(topics = "${spring.kafka.topic.email}")
public void receiveMessage(ConsumerRecord<String, String> record,
@Header("claimTime") long sendTime) {
//Producer에서 Header에 넣은 내용은 @Header로 가져올 수 있다.
Map<String,Object> message = new HashMap<>();
ObjectMapper mapper = new ObjectMapper();
try{
message = mapper.readValue(record.value(), new TypeReference<Map<String, Object>>() {});
log.info(message.toString());
}catch (JsonProcessingException ex){
ex.printStackTrace();
}
Long sendTime = Long.parseLong(message.get("claimTime").toString());
//message를 활용한 로직
//..
}
}추가
server.properties에 설정할 수 있는 더 많은 내용이 있다.
https://kafka.apache.org/documentation/#configuration
network 및 I/O 쓰레드의 수도 설정할 수 있다.
# 생성되지 않은 토픽을 자동으로 생성할지 여부. 기본값은 true.
auto.create.topics.enable=false
# Broker가 받은 데이터를 관리위한 저장공간.
log.dirs=C:/work/kafka_2.12-2.1.0/data/kafka
# 서버가 받을 수 있는 메세지의 최대 크기, 기본값 1MB.
# Consumer에서는 fetch.message.max.bytes를 사용하는데
# message.max.bytes >= fetch.message.max.bytes로 조건에 맞게 잘 설정해야한다.
message.max.bytes=1000000
# 네트워크 요청을 처리하는 쓰레드의 수, 기본값 3.
num.network.threads=3
# I/O가 생길때 마다 생성되는 쓰레드의 수, 기본값 8.
num.io.threads=8
# 서버가 받을 수 있는 최대 요청 사이즈이며, 서버 메모리가 고갈 되는걸 방지함.
# JAVA의 Heap 보다 작게 설정해야 함, 기본값 104857600.
socket.request.max.bytes=104857600
# 소켓 서버가 사용하는 송수신 버퍼 (SO_SNDBUF, SO_RCVBUF) 사이즈, 기본값 102400.
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
# 토픽당 파티션의 수를 의미하며, 입력한 수만큼 병렬처리를 할 수 있지만 데이터 파일도 그만큼 늘어남. 기본값 1.
num.partitions=1
# 세그먼트 파일의 기본 사이즈, 기본값 1GB.
# 토픽별로 수집한 데이터를 보관하는 파일이며, 세그먼트 파일의 용량이 차면 새로운 파일을 생성.
log.segment.bytes=1073741824
# 세그먼트 파일의 삭제 주기, 기본값 hours, 168시간( 7일 ).
# 옵션 [ bytes, ms, minutes, hours ]
log.retention.hours=168
# 세그먼트 파일의 삭제 주기에 따른 처리, 기본값은 delete.
# 옵션 [ compact, delete ]
# compact는 파일에서 불필요한 records를 지우는 방식.
log.cleanup.policy=delete
# 세그먼트 파일의 삭제 여부를 체크하는 주기, 기본값 5분.
log.retention.check.interval.ms=300000
# 세그먼트 파일의 삭제를 처리할 쓰레드의 수. 기본값 1.
log.cleaner.threads=1
# 오프셋 커밋 파티션의 수, 한번 배포되면 수정할 수 없음. 기본값 50.
offsets.topic.num.partitions=50
# 토픽에 설정된 replication의 인수가 지정한 값보다 크면 새로운 토픽을 생성하고
# 작으면 브로커의 수와 같게 된다. 기본값 3.
offsets.topic.replication.factor=1
# 주키퍼의 접속 정보.
zookeeper.connect=localhost:2181
# 주키퍼 접속 시도 제한시간.
zookeeper.connection.timeout.ms=6000참고
https://taaewoo.tistory.com/59
https://sharplee7.tistory.com/144
https://heodolf.tistory.com/11
