Redis 특징
Redis Stream을 이해하기 위해서는 먼저 Redis에 대한 이해가 필요하다.
Key-Value 쌍의 해시맵
Redis는 고성능 키-값 저장소로서, NoSQL로 분류될 수 있다.
Key-Value 쌍의 해시맵 형태의 서버로서 별도의 쿼리 없이 Key를 통해 빠르게 결과를 가져올 수 있다는 장점이 있다.
인메모리
Redis는 인메모리(RAM에 데이터 저장)라는 특성으로 작업 속도가 상당히 빠르다.
그러나, 서버가 다운되면 모든 데이터가 사라질 수 있다는 문제가 있는데 Redis에서는 이를 보완하기 위해 디스크에 데이터를 저장할 수 있는 두가지 방법을 제공한다.
영속성 보장 1. RDB(Redis DataBase)
스냅샷 방식으로, 일정 조건에 따라 메모리 내용을 바이너리 파일로 디스크에 저장한다.
# save [Seconds] [Changes]
save 900 1 # 900초(15분) 동안 1번 이상 key 변경이 발생하면 저장
save 300 10 # 300초(5분) 동안 10번 이상 key 변경이 발생하면 저장
save 60 10000 # 60초(1분) 동안 10000번 이상 key 변경이 발생하면 저장기본값으로 redis.conf에 위와 같이 설정되어있다.
RDB 저장 방식
- SAVE: blocking으로 redis 동작을 정지시키고, snapshot을 저장한다.
- Main process가 데이터를 새 RDB temp 파일에 쓴다.
- 쓰기가 끝나면 기존 파일을 지우고 새 파일로 교체한다.
- BGSAVE: non-blocking으로, 별도의 자식 프로세스(백그라운드 SAVE)를 띄운 후, 명령어 수행 당시의 snapshot을 저장한다. redis는 동작을 멈추지 않는다.
fork()를 하기 때문에 메모리를 두 배정도 사용하므로 주의해야 한다.
- Child process를 fork()한다.
- Child process는 데이터를 새 RDB temp 파일에 쓴다.
- 쓰기가 끝나면 기존 파일을 지우고, 이름을 변경한다.
stop-writes-on-bgsave-error yesBGSAVE 이벤트 시 RDB 파일을 디스크에 저장하다 실패했을 경우, Redis에서 데이터를 받아들일지 말지를 결정하는 파라미터이다.
- yes: Default. RDB 저장 실패시 모든 쓰기 요청을 거부한다. 쓰기에 문제가 발생했으니 빨리 조치를 취하라는 의미이다.
- no: 디스크 저장이 실패해도, 쓰기 요청을 포함한 모든 동작을 정상적으로 처리한다.
영속성 보장 2. AOF(Append-Only File)
레디스 서버에 데이터의 업데이트 명령이 수행될 때마다, 해당 명령어의 로그를 디스크에 appendonly.aof파일로 남긴다.
AOF는 non-blocking으로 동작하며, append-only이므로 write 속도가 빠르다. RDB와 달리 text 파일이므로 편집이 가능하다.
RDB와 AOF를 동시에 사용하면 데이터의 영속성을 보장할 수 있다. 하지만, AOF는 text파일이라 무겁기 때문에, redis.conf에 용량을 제한하거나 rewrite 기능 등을 설정해야 한다.
appendonly yes #AOF 적용
appendfsync everysec #AOF에 기록되는 시점
# AOF 파일 사이즈가 64mb 이하면 rewrite를 하지 않는다.
auto-aof-rewrite-min-size 64mb
# AOF 파일 사이즈가 특정 퍼센트 이상 커지면 rewrite 한다.
# 비교 기준은 레디스 서버가 시작할 시점의 AOF파일 사이즈이다.
# 0으로 설정하면 rewrite를 하지 않는다
auto-aof-rewrite-percentage 100appendfsync
AOF는 버퍼 캐시에 저장하고 적절한 시점에 이 데이터를 디스크로 저장하는데, appendfsync로 디스크와 동기화를 얼마나 자주 할 것인지 설정할 수 있다.
- always: 명령 실행 시 마다 AOF 기록. 정합성은 높지만 성능이 매우 떨어진다.
- everysec: 1초마다 AOF에 기록. 권장
- no: AOF 기록 시점을 OS가 정한다.(일반적인 리눅스 디스크 기록 간격은 30초) 데이터가 유실될 수 있다.
rewrite
AOF 파일의 상태가 특정 조건일 때 AOF 파일을 현재 상태에 맞춰, 설정에 따라 덮어쓰기 하거나 새로 생성하도록 한다.
싱글 스레드(원자성)
Redis는 싱글 스레드를 사용해 Race Condition이 거의 발생하지 않는다는 장점이 있다. 하지만, 싱글 스레드는 멀티 스레드에 비해 속도의 한계가 명확하다.
이 문제를 해결 하기 위해 Redis 6.0에서는 ThreadedIO가 도입되어, 기존보다 속도가 약 2.5배 빨라졌다고 한다. 메모리 내부에서 명령의 실행 자체는 싱글 스레드로 동작하나,
- 클라이언트가 전송한 명령을 네트워크로 읽어서 파싱하는 부분
- 명령이 처리된 결과 메시지를 클라이언트에게 네트워크로 전달하는 부분
에 ThreadedIO가 적용되었다.
꽤 어려운 개념이라, 자세한 내용은 아래의 글을 읽어보면 좋을 듯 하다.
https://charsyam.wordpress.com/2020/05/05/입-개발-redis-6-0-threadedio를-알아보자/
Redis의 Collection
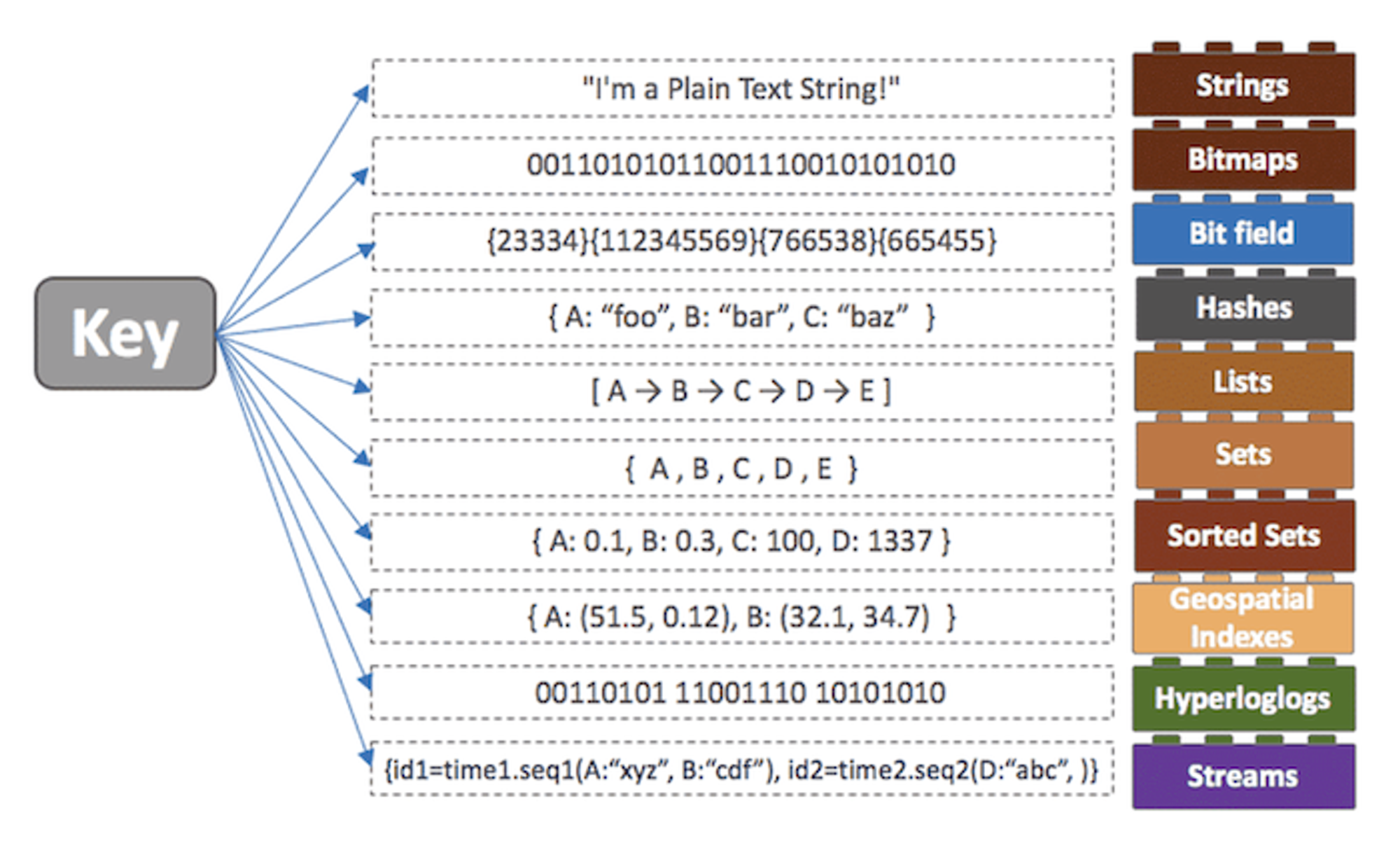
Redis는 String 뿐 아니라 다양한 데이터 구조체를 지원함으로써 DB, Cache, Message Queue, Shared Memory 용도로 사용될 수 있다.
Redis Pub/Sub
https://redis.io/docs/interact/pubsub/
Redis Pub/Sub은 Redis 2.0에 추가된 레디스 구조체 중 하나로서, 단순한 브로드캐스팅 작업을 지원한다.
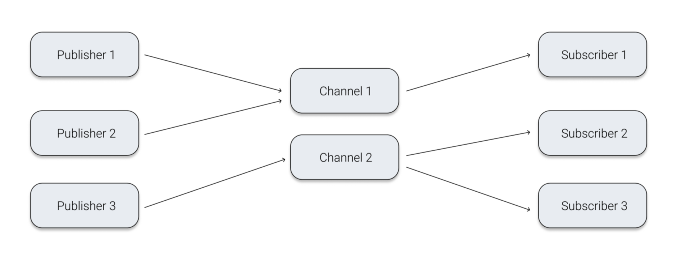
RabbitMQ나 Kafka와 달리, 메시지가 전달되는 Channel은 이벤트를 저장하지 않기 때문에, 이벤트가 도착했을 때 채널의 Subscriber가 없다면 이벤트는 증발한다.
Redis Stream
https://redis.io/docs/data-types/streams/
Redis Stream은 Redis 5.0에 추가되었으며,
- ACK를 지원하여, 메시지의 내구성과 지속성 보장
- 각 메시지에 고유한 ID 부여
- Consumer Group 지원
- Consumer마다 서로 다른 메시지 소비 가능
등 기존 Redis Pub/Sub에서 더 나아가 이벤트 브로커로서의 기능을 갖추었다.
레디스의 인메모리 & 싱글 스레드 특징으로, 테스트 결과 RabbitMQ와 Kafka처럼 대량의 메시지 처리보다는 적은 개수의 메시지를 신속하게 보내는 환경에 더욱 적합했다.
Redis Pub/Sub을 다룬 논문은 많았으나, Redis Stream은 선행 연구가 부족하여 이번 캡스톤 디자인의 목표로 삼았다. Redis Stream에 대한 더 자세한 설명은 다음 게시글에서 다룰 예정이다.
Redis Cluster
Redis Cluster는 데이터를 자동으로 여러 개의 Redis 노드에 나누어 저장할 수 있도록 한다. 따라서, 일부 노드가 죽거나 통신이 되지 않을 때 작업을 계속할 수 있다.
Redis는 싱글 스레드로 동작하기 때문에 성능을 올리기 위해서 Redis Cluster를 구성할 수도 있다.
특징
1. 샤딩(Sharding)
샤딩은 "조각내다"라는 뜻으로 DB 저장 기법 중 하나이다. 데이터를 파티셔닝 하는 기술을 뜻한다.
Redis Cluster는 master를 여러개 두어 분산 저장(Sharding)이 가능하며, Scale out이 가능하다.
2. 가용성
- master에 하나 이상의 slave를 둘 수 있다.
- 노드 하위 집합에서 장애가 발생하거나, 클러스터의 나머지 부분과 통신할 수 없을 때 작업을 계속할 수 있다.
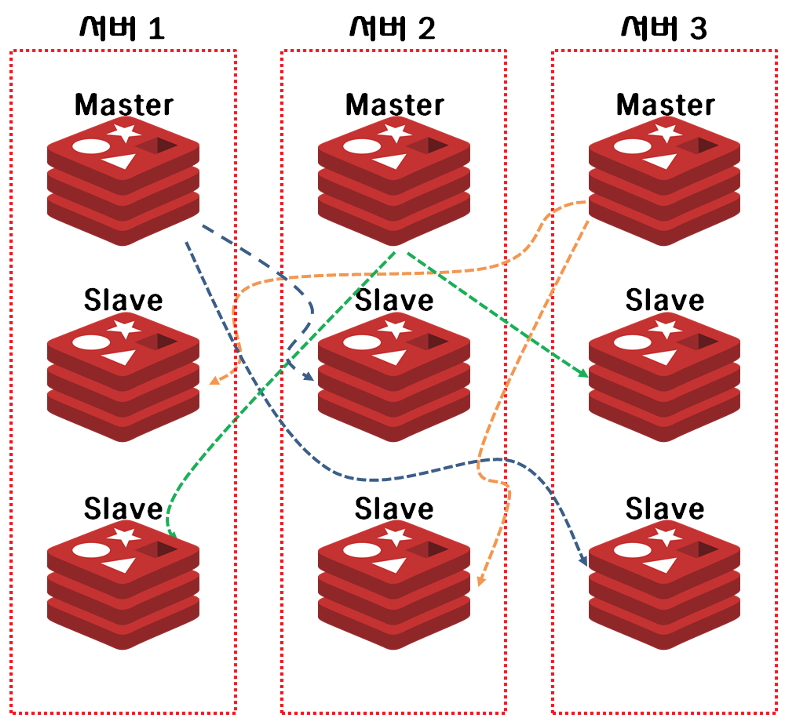
예를 들어, master 1,2,3이 있다면 데이터는 3개 중 하나에 저장된다.
Client가 데이터 읽기 요청 시 저장된 곳이 아닌 다른 마스터에 요청했다면, 저장된 마스터 정보를 알려준다. Client는 전달받은 마스터 정보에 다시 요청해서 데이터를 받아올 수 있다.
이 때, 서버 1에 문제가 발생해 더 이상 통신이 되지 않는다면, 자동으로 서버2 or 3에 있는 replica 노드 중 하나가 master가 되어 작업을 계속할 수 있다.
따라서, 모든 서버가 고장날 때 까지 클러스터는 정상적으로 작동한다.
Docker로 Cluster 설정
3대의 서버에 총 6개의 노드를 띄우는 예시이다.
- master 노드 1개씩(*3) : 7000번 포트
- slave 노드 1개씩(*3) : 7001번 포트
config 파일 설정
1. 방화벽 해제
cluster 구성 시 cluster bus가 통신하는 포트는 각 노드 포트 + 10000번이므로 7000, 7001, 17000, 17001번 포트의 방화벽을 해제한다.
❗cluster bus는 장애 감지, 구성 업데이트 failover 승인 등에 사용된다.
2. 메모리 사용량 overcommit & Accept 소켓 개수 변경
# 메모리 사용량이 허용량을 초과할 경우, overcommit을 처리하는 방식. "항상"으로 변경
# 실제 메모리가 사용되기 전, 요청된 메모리 양을 계산하여 요청 양보다 많은 메모리가 사용될 경우에만 할당
sudo sysctl vm.overcommit_memory=1
sudo echo "vm.overcommit_memory=1" >> /etc/sysctl.conf
sudo sysctl -a | grep vm.overcommit
# 서버 소켓에 Accept를 대기하는 소켓 개수 파라미터를 변경
sudo sysctl -w net.core.somaxconn=1024
sudo echo "net.core.somaxconn=1024" >> /etc/sysctl.conf
sudo sysctl -a | grep somaxconn2. 디렉토리 생성
/opt/redis디렉토리를 생성하여 하위에 7000, 7001 폴더를 생성한다.
/opt/redis/7000,/opt/redis/7001
추후 docker로 redis 실행 시 볼륨 마운트 할 예정이다.
3. master 노드 conf 파일 생성
/opt/redis/7000/7000.conf생성
bind 0.0.0.0
daemonize yes
protected-mode no
port 7000
pidfile /opt/redis/7000/redis_7000.pid
logfile /opt/redis/7000/redis-7000.log
#dir /opt/redis/7000
dbfilename dump_7000.rdb
requirepass [redis password]
masterauth [redis password]
cluster-config-file node-7000.conf
cluster-enabled yes
cluster-node-timeout 5000
cluster-announce-ip [서버 public ip] # NAT/포트포워딩 사용시
rename-command keys ""
appendonly no- requirepass: (default null). redis 서버에 password 설정. redis.conf에 plaintext로 작성한다.
- masterauth: master 노드에 패스워드 설정이 되어 있는 경우, slave가 replication synchronization 작업을 하기 전에 slave에게 비밀번호를 알려주는 역할이다.
- cluster-config-file: 클러스터의 상태가 변경될 때마다 바이너리로 저장하는 파일이다.
- cluster-enabled:
yes를 추가해야 클러스터 모드로 동작한다.
no로 설정 시 standalone 모드로 동작한다. - cluster-node-timeout: 레디스 노드가 다운되었는지 설정된 시간(ms)마다 확인한다.
- cluster-announce-ip: docker 사용 / NAT / 포트 포워딩 환경에서는 Redis cluster 노드를 찾을 수 없는 상황이 발생한다. 이 때, 각 노드에게 자신의 Public IP를 알려주는 역할을 한다.
4. slave 노드 conf 파일 생성
/opt/redis/7001/7001.conf생성
bind 0.0.0.0
daemonize yes
protected-mode no
port 7001
pidfile /opt/redis/7001/redis_7001.pid
logfile /opt/redis/7001/redis-7001.log
#dir /opt/redis/7001
dbfilename dump_7001.rdb
requirepass [redis password]
masterauth [redis password]
cluster-config-file node-7001.conf
cluster-enabled yes
cluster-node-timeout 5000
cluster-announce-ip [서버 public ip]
rename-command keys ""
appendonly noredis 노드 띄우기
docker로 각 서버에 redis master & slave 실행
docker run -v /opt/redis/7000:/etc/redis/7000 -p 7000:6379 --name redis-master -d redis redis-server /etc/redis/7000/7000.conf
docker run -v /opt/redis/7001:/etc/redis/7001 -p 7001:6379 --name redis-slave -d redis redis-server /etc/redis/7001/7001.conf각 노드가 잘 동작하는지는 로그로 확인할 수 있다.
/opt/redis/7000/redis-7000.logcluster에 master 노드 추가
서버 한 대에서 다음 명령어로 클러스터를 실행한다.
docker exec -it redis-master bashredis-cli -a [비밀번호] --cluster create [서버1 IP]:7000 [서버2 IP]:7000 [서버3 IP]:7000cluster에 slave 노드 추가
서버 한 대에서 slave 노드를 추가한다.
서버 2에는 서버 1의 slave, 서버 3에는 서버 2의 slave, 서버 1에는 서버 3의 slave를 둔다.
redis-cli -a [비밀번호] --cluster add-node [서버2 IP]:7001 [서버1 IP]:7000 --cluster-slave
redis-cli -a [비밀번호] --cluster add-node [서버3 IP]:7001 [서버2 IP]:7000 --cluster-slave
redis-cli -a [비밀번호] --cluster add-node [서버1 IP]:7001 [서버3 IP]:7000 --cluster-slavedocker-compose로 Cluster 구성하기
https://velog.io/@nwactris/Docker-compose로-Redis-Cluster구성with-Predixy
Redis Cluster 앞의 Proxy 기능을 하는 Predixy까지 포함하여 따로 정리했다!
Kubernetes에서 Redis Cluster를 구축한 사례
Redis Cluster Scale in/out에 대해서도 생각해 볼 수 있는 글이다.
(다 이해하긴 아직 어렵다)
https://tech.kakao.com/2022/02/09/k8s-redis/
참고
https://inpa.tistory.com/entry/REDIS-📚-데이터-영구-저장하는-방법-데이터의-영속성
https://zangzangs.tistory.com/88
https://velog.io/@tngusqkr1/Redis-cluster-설정-1
https://co-de.tistory.com/24
