Text Analytics/ Text Mining 이란?
unstructured data(비정형 데이터)에서 데이터를 분석해 의미있는 정보를 추출하는 것으로, 텍스트 데이터를 분석하면 정보를 빠르게 축약(abstraction), 요약(summarization), 시각화(visualization)할 수 있다.
ex)
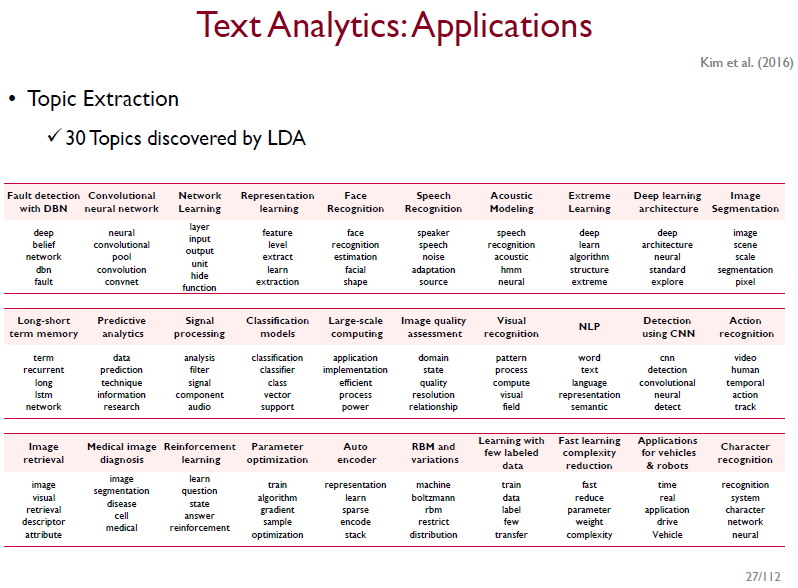
topic modeling - LDA(Latent Dirichlet Allocation)
스팸메일 분류(rule based, 스팸메일과 일반메일의 제목과 내용을 비교)
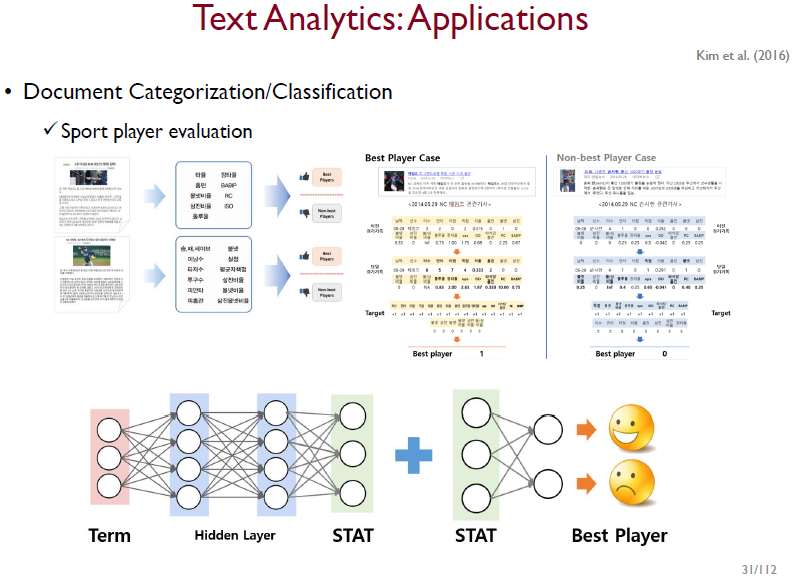
위의 예시는 야구선수의 뉴스 기사로부터 통계량을 뽑아 선수가 잘 했는지, 못 했는지 예측하는 모델이다.
또한, 자연어처리 적용분야는 다음과 같다.
- 트위터의 트윗을 통해 sentiment analysis
- 한 문장을 단어 단위로 쪼개서 학습시키기 & 글자 단위로 쪼개서 학습시키기 모두 사용하면 한가지만 사용한 것보다 높은 성능을 보임
- 여행지 추천: 블로그의 포스팅을 분석해 가장 긍정적인 반응이 많은 장소를 추천
- 영화의 흥행여부 예측: SNS를 통해 사람들이 무엇을 언급하는지(언급하는 횟수의 증감, 언급의 긍부정) + 배급사, 감독 등 기존의 방식
- Dov2Vec : 문서를 벡터화
- 질의응답(Question Answering)
https://aperswithcode.com/task/question-answering
- 챗봇 시스템!
- 텍스트 분석이 어려운 이유: 텍스트 데이터는 고차원이며, 문맥에 따라 의미가 달라지고, 언어 자체가 모호성을 가지기 때문.

개발노트