Text Preprocessing
큰 의미의 NLP : 텍스트를 포함하는 모든 분석 기법
좁은 의미의 NLP : 어휘분석(Lexical analysis), 구문분석(syntax analysis), 문장분석 -> 언어적인 특징을 분석하는데 초점을 맞춤
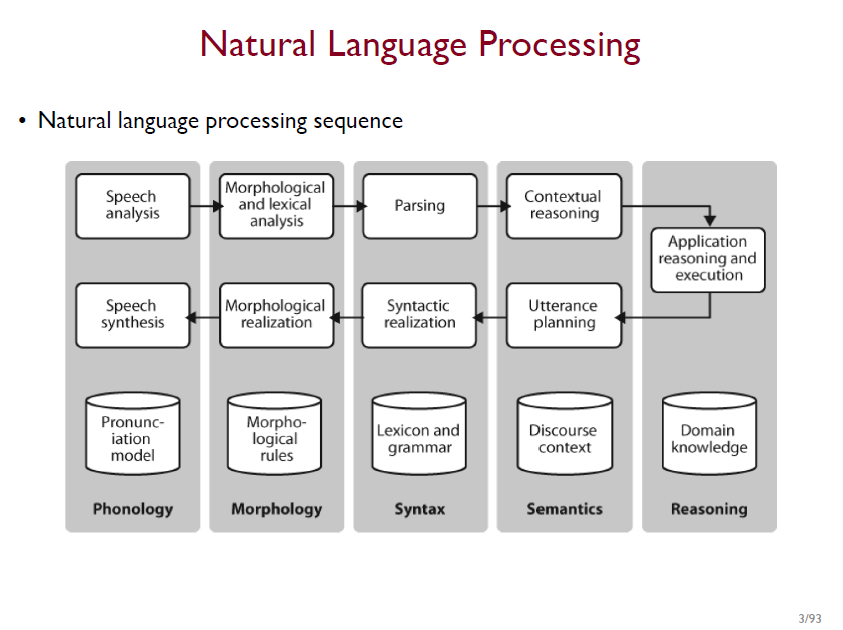
- 왼쪽 -> 오른쪽 : 음성을 텍스트로 변환해 분석
- 오른쪽 -> 왼쪽 : 분석한 텍스트를 다시 음성으로 합성

- Phonology/음운론: 사람의 음성을 어떠한 음절로 바꿀 것인가
- Morphology/ 형태소: 문장을 토큰단위로 얼마나 정확하게 구분할 것인가
- Syntax/ 구문: 단어, 토큰간의 구조적인 관계를 분석
- Semantics/ 의미론: 문장, 문단이 가지는 의미가 무엇인가
- Pragmatics, Discourse : 사람의 사회적인 작용과 연결됨, 아직 인공지능으로 구현하기 어려움

- Lexical Analysis : a(관사) teacher(명사) come(동사원형)+s(3인칭 단수형)
- Syntax Analysis : a teacher (명사부/주어부) comes(동사부/술부)
- Semantic Analysis : teacher라는 객체가 존재하고 이동하고 있다. => 이 단계까지는 현재 기술로 구현 가능함
- Pragmatic Analysis : 사회에서 통용되는 어휘/의미가 있기 때문!

- 프로그래밍 언어와 다르게 자연어(NLP)를 해석하는 일은 어렵다.
- 프로그래밍 언어는 작은 세계안에서만 사용되고, 문법이 단순하고 의미도 명확하다.
- 자연어에는 수많은 단어가 있고, 문법이 복잡하며, 의미가 애매하기도 하고 시간의 흐름에 따라 사용되는 단어가 달라진다.

- 의미1: 그는 망원경을 가진 남자를 보았다. (man~telescope)
- 의미2: 그는 망원경으로 그 남자를 보았다. (He~telescope)

1) 규칙기반(rule-based) 방식
- 자연어에 적용되는 모든 규칙을 만들 수 있다는 믿음으로 시작되었지만, 규칙기반 방식은 자연어가 가진 동적인 특징으로 인해 실패했다.
- "google"이라는 단어는 어떤것을 찾아본다는 의미를 가진다.
2) 통계 기반 방식
- 분류 관점에서는 SVM방식이 우수한 성능을 보임.
- 학습 데이터(corpus)가 필요함
- 연역적 방식(rule-based) -> 귀납적 방식(statistical, machine learning)으로 바뀜
- 통계기반 번역보다는 딥러닝기반 번역이 추세

예전에는 단계마다 사람의 개입이 필요했지만, 현재는 문서만 넣으면 최종 분류가 가능한 end-to-end 방식이 많다.
