[Text Analytics] 2-2강: Text Preprocessing-part 2
Lexical Analysis(어휘 분석)
- 의미를 보존할 수 있는 최소한의 단위(단어/토큰) 안에서 분석을 하는 것
- 목적: 일정한 순서가 있는, 의미를 가진 character들의 조합을 토큰으로 분리하는 것으로 토큰은 형태소/ 단어 단위로
- 순서: 문서 토큰화 -> 각각의 토큰이 문장에서 어떤 역할을 하는지 POS tagging -> 추가적으로 객체명 인식(NER : name entity recognition - 사람인지, 사물인지 인식하는 과정)
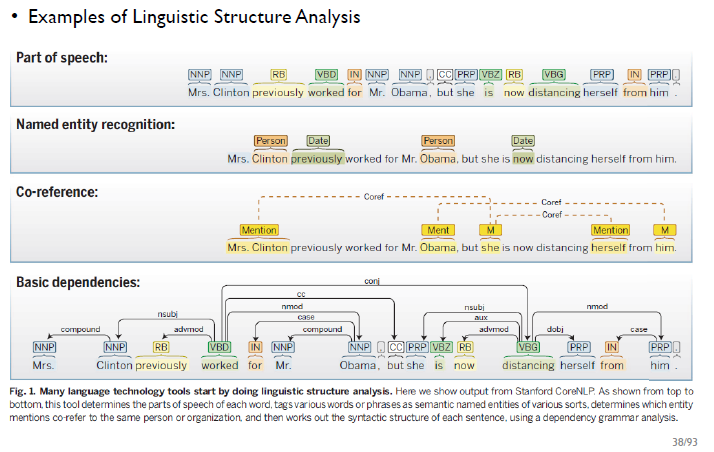
-> Part of speech : 각각의 단어가 문장에서 명사인지, 부사인지, 동사인지
-> Named entity recognition : 각각의 단어가 사람인지, 날짜인지
-> Co-reference : 대명사가 어떤 명사를 가리키는지, 문장 안에서 어떤 명사가 같은 사람을 지칭하는지
-> Basic dependencies : 동사, 부사가 어떤걸 수식하는지
Process of Lexical Analysis
1) Sentence Splitting
- NLP에서는 중요하지만, topic model과 같은 몇몇 분야에서는 중요하지 않은 단계임
- 단순히 문장부호 (마침표(.), 느낌표(!), 물음표(?) )를 기준으로 문장을 나누면 축약형인 "U.S"같은 단어나 날짜를 표시하는 "3.14"같은 경우도 문장으로 나누어버림
- 일반적인 방식: 규칙기반(rule-based) 또는 문장단위로 나누어서 모델을 학습시킴
2) Tokenization
- 중요하지만 완벽하게 하기 어려움
- 문서를 의미를 가진 기본적인 단위인 token으로 분리하는 일
- 영어에서는 whitespace(공백)을 기준으로 토큰화를 하는데, 중국어처럼 공백이 없는 언어에는 적용하기 어렵다.
3) Morphological Analysis(형태소 분석)
- 토큰의 의미를 훼손하지 않으면서 차원을 축소하는 방법 : Stemming, Lemmatization
- Stemming/ 어간 추출 : 단어의 base form을 찾음, 사전에 등장하지 않은 단어가 될 가능성이 있음
- 정보 추출의 관점에서 많이 사용되며, suffix-stripping과 같은 규칙기반 방식으로 적용됨
- 영어에는 Porter stemmer가 있음
- 정의한 규칙은 언어에 의존적이고
- 결과가 존재하지 않는 단어일 수도 있음, 다른 stem의 단어인데 같은 stem으로 추출될 수 있음
- Lemmatization/ 표제어 추출 : 단어의 lemma를 찾음, 품사를 보정해 단어의 원형을 찾음
- Stemming보다는 정확하지만, 처리속도가 느리고 복잡함
- 의미분석(semantics)이 중요한 경우에는 lemmatization이 필요하지만, 그렇지 않은 경우에는 stemming이 더 효율적임
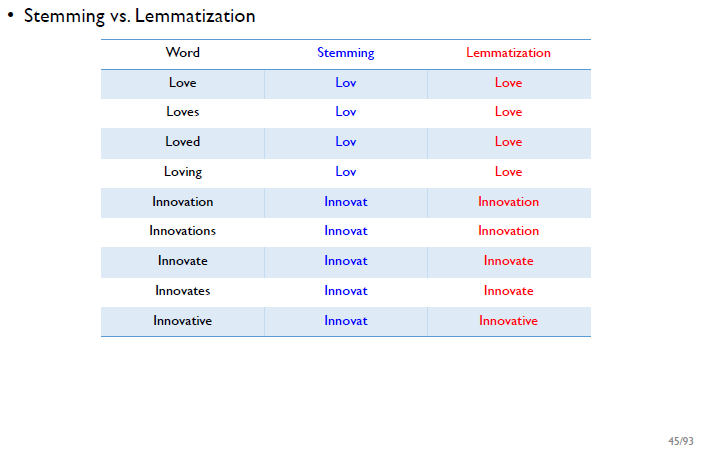
-> "Loving"을 stemming하면 e가 없기 때문에 "Lov"를 찾지만, "Lov"는 사전에는 없는 단어
-> Lemmatization의 결과는 원형을 보존함

-> stemming : company/ companies => company/ compani
-> lemmatization : company/ companies => company/ company
4) Part-of-Speech(POS) tagging (품사 태깅)
- 토큰으로 이루어진 문장을 입력에 넣으면, 각 토큰의 품사정보를 출력함
- POS tagging과 parsing은 다르다.
- 통계기반으로 POS tagging을 하려면, manually annotated corpus가 필요함

-> 같은 토큰(단어)라도 품사인 POS tag가 달라질 수 있음
POS tagging algorithms
- Training : manually annotated corpus가 필요함
- Tagging algorithm : training에 사용된 corpus와 같은 domain에서 수행하면 정확도는 높음
- 방법 : decision trees, Hidden Markov Models(HMMs), Support Vector Machine(SVM), 딥러닝

-> Pointwise prediction : "Natural language processing(NLP)"가 들어갔을 때 "processing"의 품사를 반환
-> HMM : W1 -> W2 -> W3 각 토큰에 해당하는 pos를 순차적으로 반환
-> CRF : (W1, W2, W3) 각 토큰에 해당하는 pos를 한번에 반환
Pointwise prediction : Maximum Entropy Model

- Feature encoding: 특정 단어와 문맥상의 정보를 고려했을 때, 이 정보가 품사를 예측하는데 중요한지에 대한 정보를 포함함 (접두사와 접미사의 여부, 주변단어를 고려)
- 예시 : W_j (j번째 단어)의 접미사가 "ing"이고 t_j (j번째 단어의 품사)가 VBG일 때, f_i(W_j, t_j)값은 1을 가지고 나머지 경우에는 0을 가짐
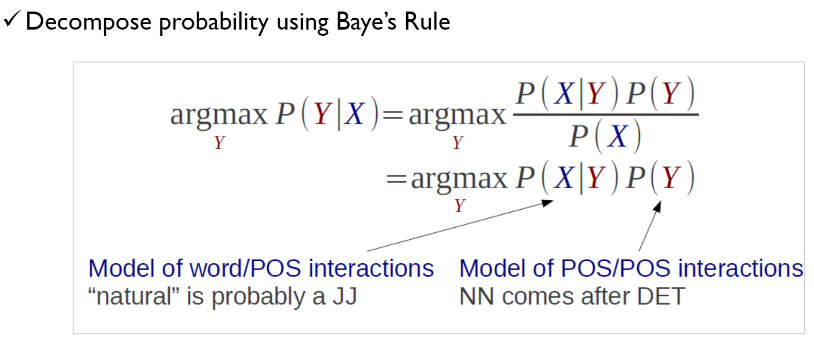
Probabilistic Model for POS tagging

-> 문장이 주어졌을 때 가장 그럴듯한 tag sequence를 찾음
-> 전체 문장 관점에서 tag들의 조합이 가장 그럴듯해 보이는 tag set Y의 확률이 가장큰 경우를 찾음
Generative Sequence Model
5) Named Entity Recognition (개체명 인식)
- Dictionary, rule-based로 했을 때 좋은 성능을 보임
- 개체마다 해당하는 리스트를 만들어 단순비교해서 개체명을 인식할 수 있음-> 리스트를 계속 업데이트 해야하는 단점이 있음
- CNN 기반 : Word2Vec, N-Grams 등이 있음
