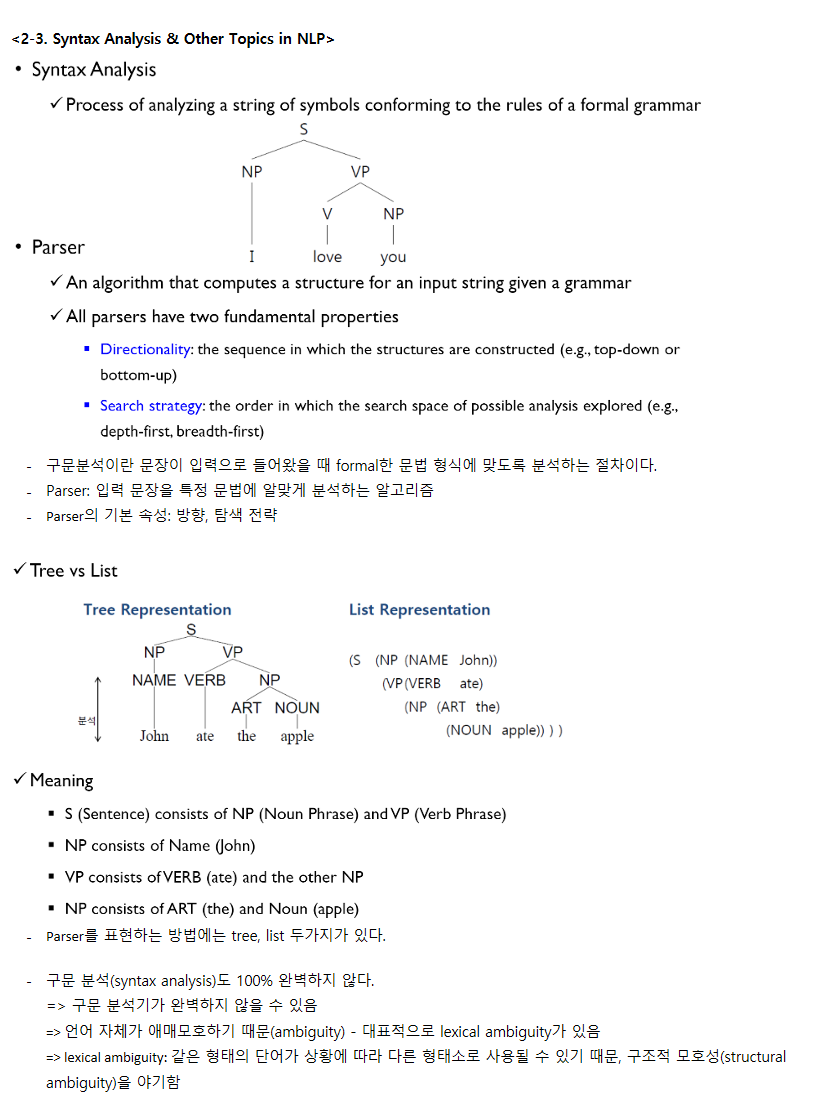
Syntax Analysis & Other Topics in NLP
- 구문분석이란 문장이 입력으로 들어왔을 때 formal한 문법 형식에 맞도록 분석하는 절차이다.
- Parser: 입력 문장을 특정 문법에 알맞게 분석하는 알고리즘
- Parser의 기본 속성: 방향, 탐색 전략

-
Parser를 표현하는 방법에는 tree, list 두가지가 있다.
-
구문 분석(syntax analysis)도 100% 완벽하지 않다.
=> 구문 분석기가 완벽하지 않을 수 있음
=> 언어 자체가 애매모호하기 때문(ambiguity) - 대표적으로 lexical ambiguity가 있음
=> lexical ambiguity: 같은 형태의 단어가 상황에 따라 다른 형태소로 사용될 수 있기 때문, 구조적 모호성(structural ambiguity)을 야기함
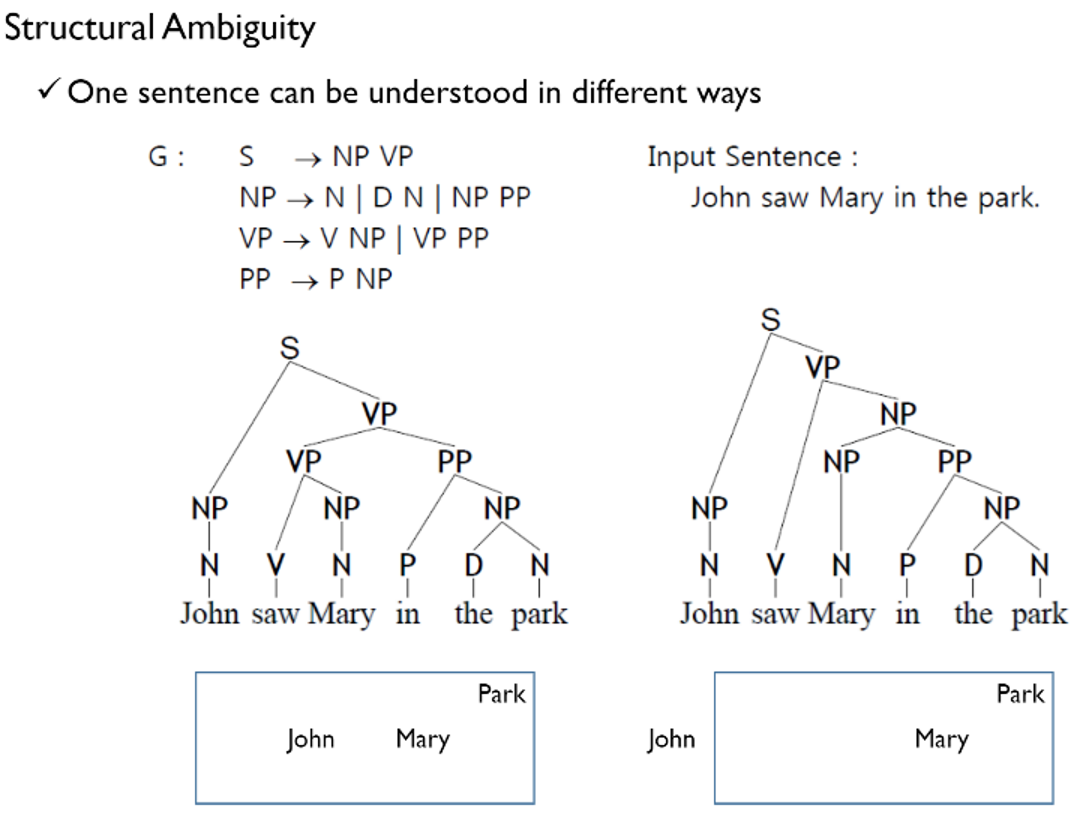
- 왼쪽: John, Mary 둘 다 공원안에 있음
- 오른쪽: 공원 안에 있는 Mary를 John이 봄
- 문서의 구문을 정확하게 분석하지 않아도 토픽 모델링, 문서 분류 등이 가능함.
Other topics in NLP

- 확률적 언어 모델: 문장이 들어왔을 때 확률을 매김, POS태그처럼 단어 각각이 아닌 문장 전체에 확률을 계산한다. -> 그럴듯한 문장인지 판단할 수 있기 때문
- High wind가 large wind보다 자연스러운 표현이기 때문에 high wind의 확률이 더 높을 것이다.
- Pre-trained 모델인 ELMO, BERT 모두 language model을 기반으로 만들어지 모델이다.

- 일련의 단어들 또는 문장이 들어왔을 때, 확률분포를 구한다.
- P(W)는 조건부확률로 chain rule에 의해 구할 수 있다.

- 문장의 마지막 단어를 예측해야하는 상황이면 앞의 모든 단어들이 필요하기 때문에, 해당하는 경우의 수를 찾기 어려움(첫번째 단어부터 마지막 단어까지 동일해야 조건을 만족하기 때문)
- 뒷부분을 없애고 uni-gram 모델을 만들자!! => 각각의 단어가 독립적으로 발생했다고 가정함

- Bigram: 바로 전 단어를 기반으로 P(wi)를 구함
- 확장시키면 3-gram, 4-gram, 5-gram… 으로 확장됨
- 언어가 long-distance dependency를 가지면 확률을 구하기 어려움
• 구글에서 진행한 구텐베르크 프로젝트
미국의 책을 모두 스캔해 n-gram 모델을 만듦
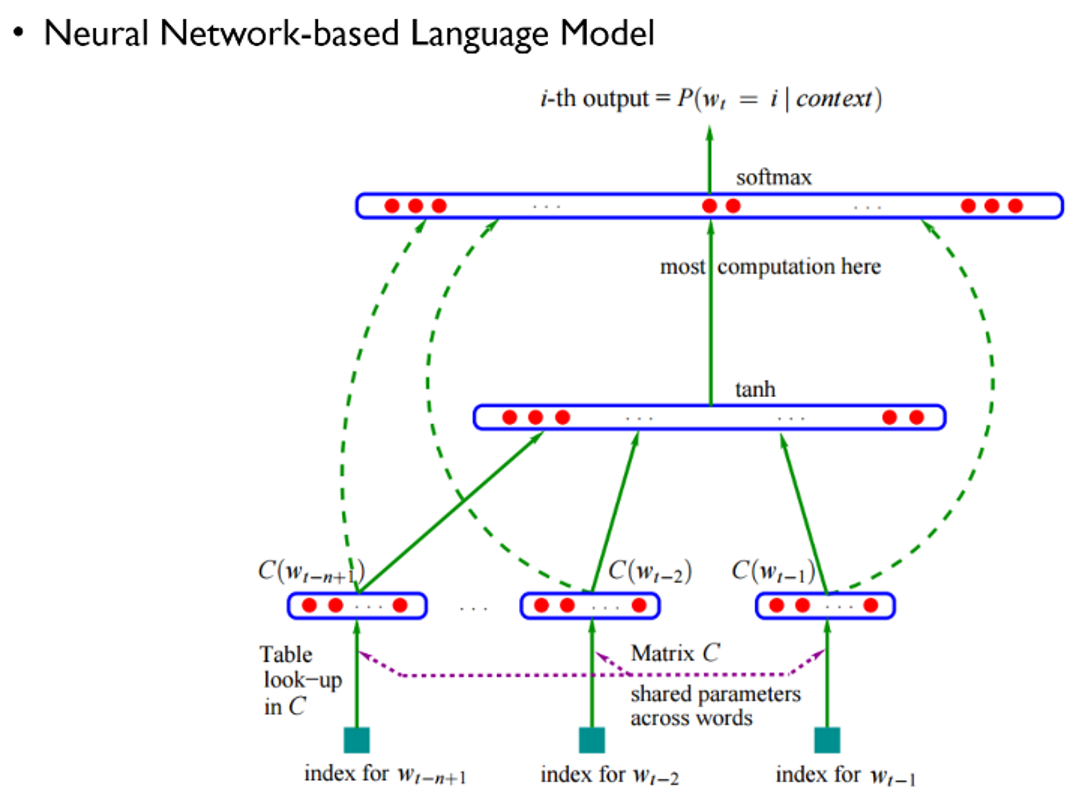
-> NNLM을 기반으로 language model을 만드는 시도를 함

개발노트