AI, 딥러닝 분야에서 학습 예제를 실행해봤다면 한 번 쯤 들어봤을 wandb에서 진행하는 세번째 밋업에 다녀왔습니다 ✨
작년에 진행했던 두 번의 밋업은 참석하지 못했습니다 ㅠㅠ
이벤트어스 사이트에서 신청했고, 이번에는 일찍 신청하면 추첨 없이 확정인 것 같았습니다!

0. W&B 소개
W&B는 손쉽게 딥러닝 모델을 학습, 평가할 수 있는 툴을 제공한다. 일반 ML 모델에는 학습 로깅 및 시각화 기능인 Experiments, 하이퍼파라미터 최적화 기능인 Sweeps 등이 있다. LLM 모델에는 모델 입출력 추적 기능인 Traces, 평가 기능인 Evaluations가 있다.
이러한 기능 뿐만 아니라, LLM을 빌딩하는 곳에서 wandb를 많이 사용하기 때문에 작년에는 LLM을 평가하는 호랑이 리더보드도 공개했다.
1. AI for Design / MIRIDIH 장주영
 미리디 회사는 "미리캔버스"라는 웹 기반 디자인 솔루션을 만든다. 발표자료나 디자인 템플릿이 다양해 한 번쯤은 들어봤을 서비스이다.
미리디 회사는 "미리캔버스"라는 웹 기반 디자인 솔루션을 만든다. 발표자료나 디자인 템플릿이 다양해 한 번쯤은 들어봤을 서비스이다.


템플릿 디자인하는데 AI를 어떻게 활용하는지 궁금했는데 아래와 같은 기능에 사용된다고 한다.
- 발표자료의 여백을 새로운 요소를 추가하거나 재배치할 때
- 발표자료에 어울리는 아이콘이나 이미지 삽입할 때


기존 VLM에서 MLLM으로 모델을 변경하고, 사내 디자인 특화 데이터셋을 활용해 SFT 진행한 프로젝트 내용을 공유해주셨다.
피피티에서 주변 이미지와 어울리는 그림을 찾을 때, 기존에는 이미지의 텍스트에 더 집중했다면 학습 이후에는 그림체나 스타일이 유사한 이미를 우선적으로 찾아오는 것으로 바뀌었다고 한다.
Q. 학습 데이터셋은 어떻게 구성했는가?
A. 기존 피피티 템플릿에서 요소를 삭제해 학습 pair 생성
Q. 학습한 모델 평가는 어떻게 하는가?
A. 초반에는 기존 템플릿과 비교 평가했고 요즘엔 A/B test, 사용자가 다운로드 받은 것을 정답으로 간주해 평가
2. AI Agent 디자인 패턴과 Weave / W&B 오현우
두 번째 세션에서는 AI 에이전트 예시와 Weave를 통한 트래킹 예시를 다루었다.
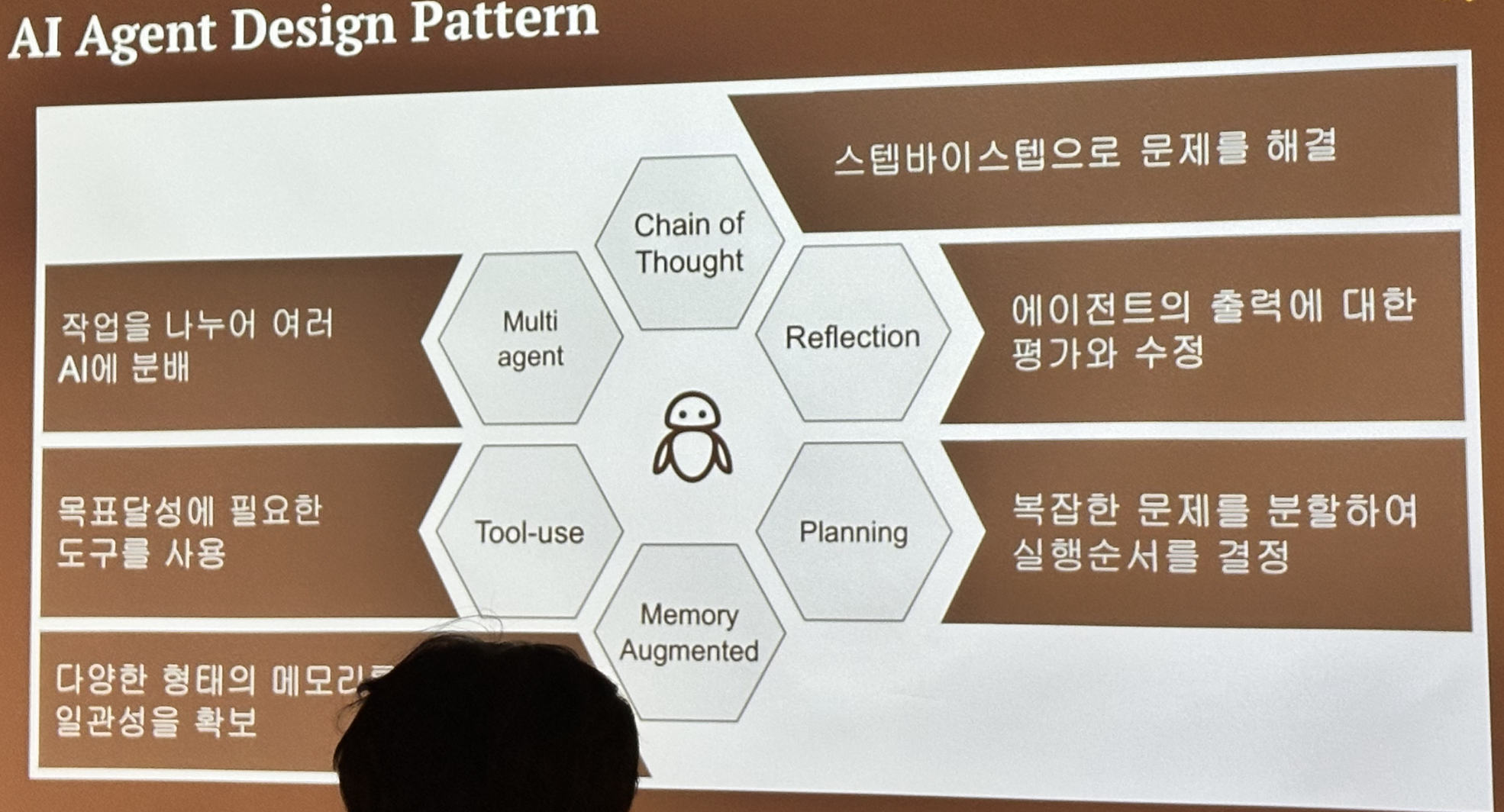 AI 에이전트를 설계할 때는 크게 6가지를 고려해야 한다. 멀티 에이전트 프로젝트에서는 복잡성이 올라가기 때문에 각 에이전트를 관리하는 것이 더 중요해진다.
AI 에이전트를 설계할 때는 크게 6가지를 고려해야 한다. 멀티 에이전트 프로젝트에서는 복잡성이 올라가기 때문에 각 에이전트를 관리하는 것이 더 중요해진다.
 Weave는 wandb에서 제공하는 LLM 관련 툴로 모델 입출력을 추적하는 Trace, 평가하는 Evaluation 기능을 제공한다.
다른 LLM 로깅, 평가 툴이 많지만 버전 관리와 데코레이터로 쉽게 적용할 수 있다는 점이 Weave의 특징이라 생각한다.
Weave는 wandb에서 제공하는 LLM 관련 툴로 모델 입출력을 추적하는 Trace, 평가하는 Evaluation 기능을 제공한다.
다른 LLM 로깅, 평가 툴이 많지만 버전 관리와 데코레이터로 쉽게 적용할 수 있다는 점이 Weave의 특징이라 생각한다.
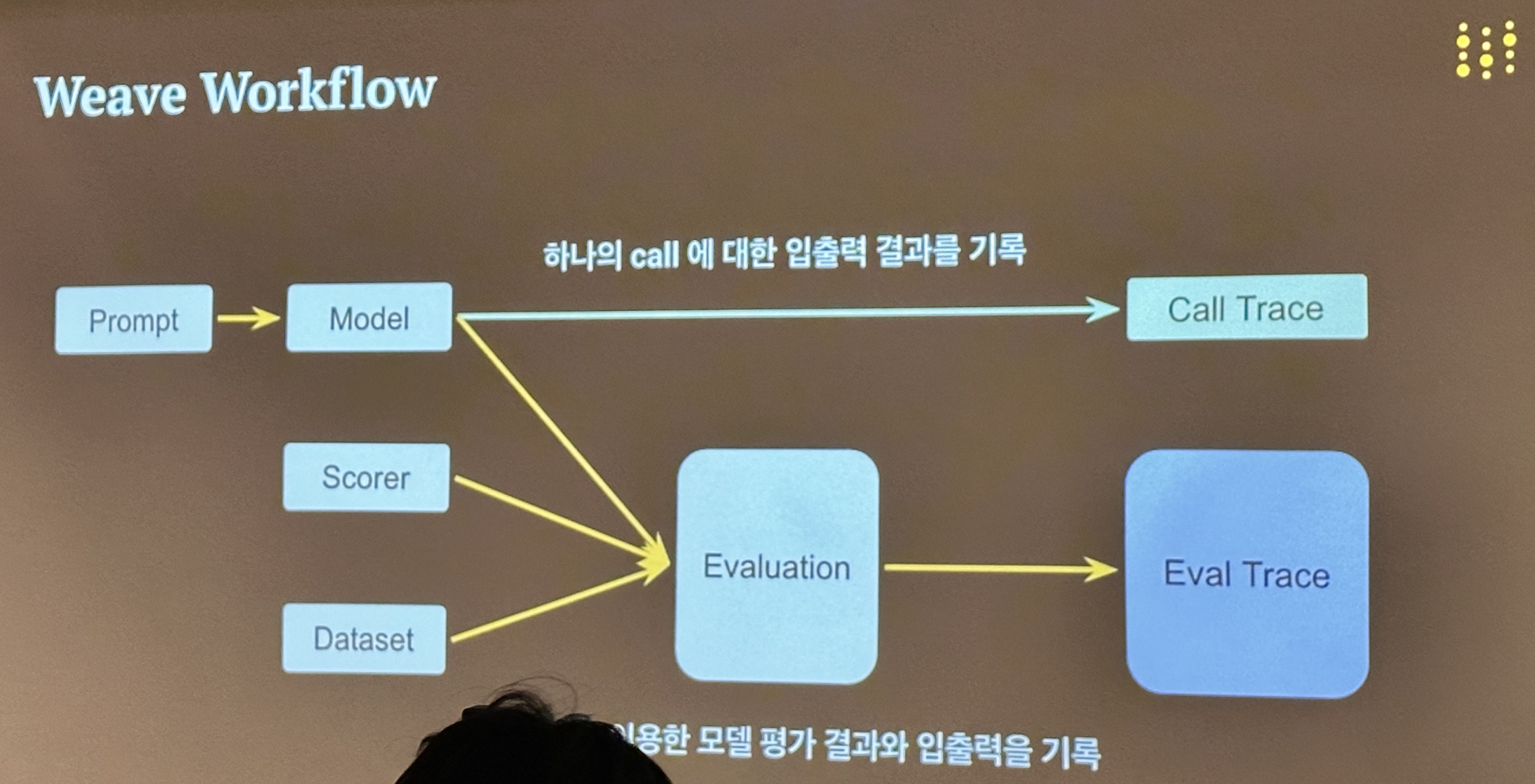 Weave의 워크플로우
Weave의 워크플로우
 crewai를 활용해 "주간 AI 뉴스레터 작성" 태스크를 수행하는 AI 에이전트를 만들고, Weave로 평가한 모습이다.
예전 버전의 LLM에 web search 툴 유무에 따라 평가했을 때, 툴을 붙인 에이전트가 최신성 질문에 올바르게 답변하는걸 확인할 수 있었다.
crewai를 활용해 "주간 AI 뉴스레터 작성" 태스크를 수행하는 AI 에이전트를 만들고, Weave로 평가한 모습이다.
예전 버전의 LLM에 web search 툴 유무에 따라 평가했을 때, 툴을 붙인 에이전트가 최신성 질문에 올바르게 답변하는걸 확인할 수 있었다.
3. LLM의 Re-Ranking Ability 검색에 이식하기 / NAVER 이영준
세 번째 세션에서는 네이버 검색에 LLM의 re-reanking을 도입한 사례를 다루었다.
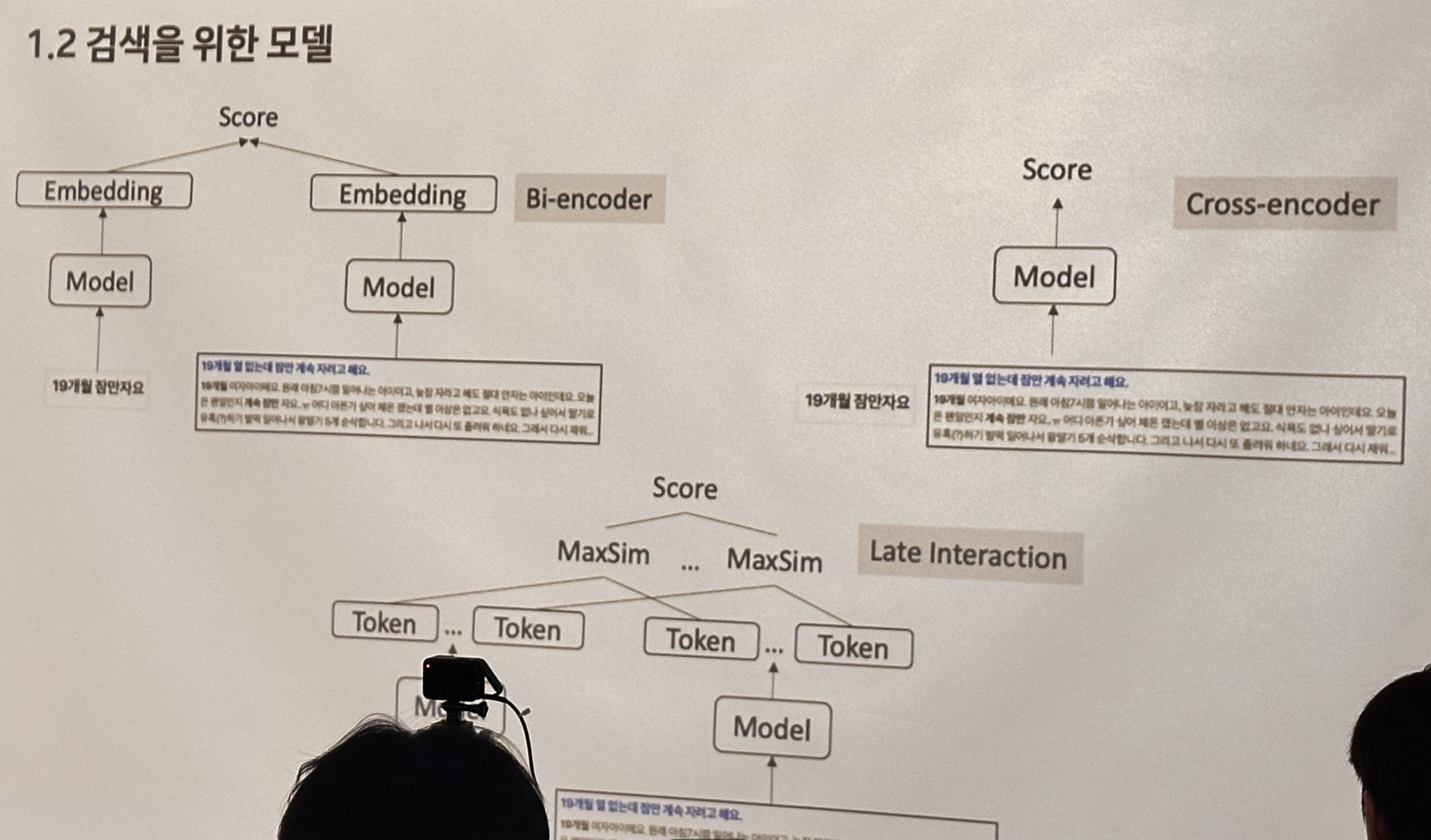 먼저 검색의 기초에 대해 설명해주셨다.
검색은 대충 비슷한 문서를 가져오는 retrieve, 가져온 문서들의 순위를 다시 재배치하는 rerank 두 단계로 구성된다.
먼저 검색의 기초에 대해 설명해주셨다.
검색은 대충 비슷한 문서를 가져오는 retrieve, 가져온 문서들의 순위를 다시 재배치하는 rerank 두 단계로 구성된다.
검색에 encoder 모델을 활용하는 구조에는 크게 bi-encoder와 cross-encoder 두 가지가 있다.
Bi-encoder는 사용자 질의와 문서를 따로 인코딩하는 방식으로, 문서를 미리 인코딩해 두어 지연시간이 짧은 장점이 있다.
Cross-encoder는 사용자 질의와 문서를 함께 인코딩하는 방식으로, 매번 질의가 달라지면 새로 인코딩해 상대적으로 지연시간이 길다.
일반적으로 retriever에는 빠른 bi-encoder 모델을, re-ranker에는 느리지만 좀 더 성능이 높은 cross-encoder 모델을 사용한다고 한다.
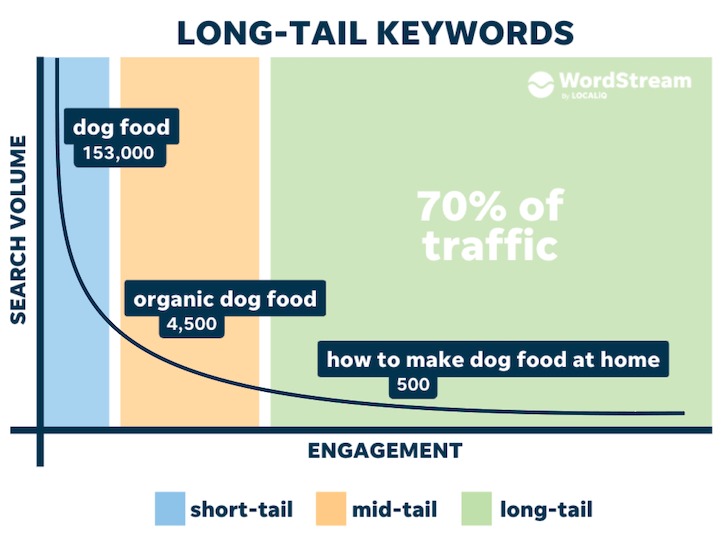 long-tail 쿼리에 대한 검색 성능을 높이기 위한 방법을 공유해주셨다.
구글에 "long-tail query"를 검색하면 위와 같은 이미지를 볼 수 있는데, 사용자 질의 길이가 길수록 검색되는 횟수는 적은 현상(?)을 의미한다.
long-tail 쿼리에 대한 검색 성능을 높이기 위한 방법을 공유해주셨다.
구글에 "long-tail query"를 검색하면 위와 같은 이미지를 볼 수 있는데, 사용자 질의 길이가 길수록 검색되는 횟수는 적은 현상(?)을 의미한다.
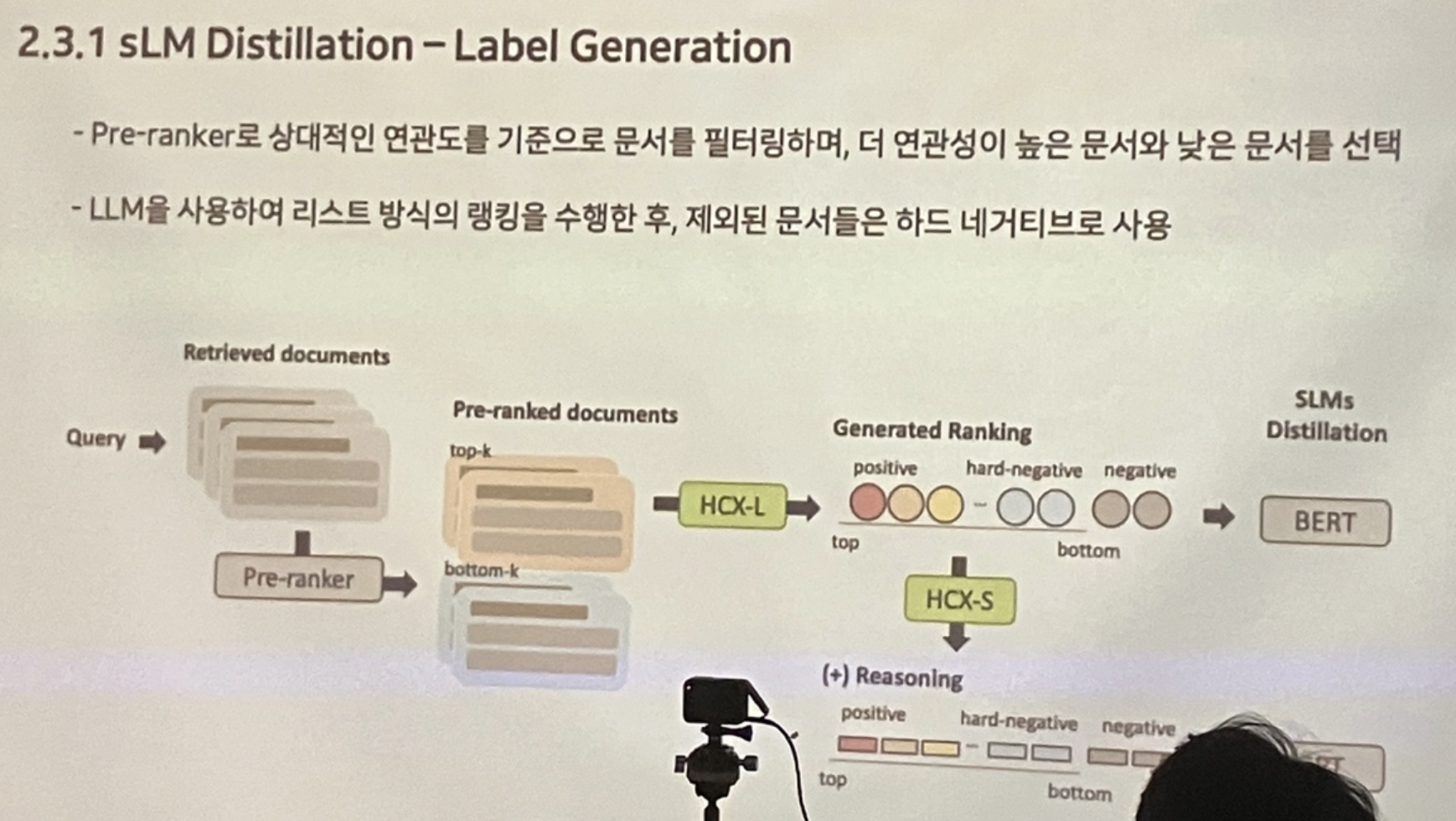 re-ranker 단계에 더 가벼운 모델을 사용하고자 BERT 모델을 distillation했고, 새롭게 학습 데이터셋을 구축했다.
re-ranker 단계에 더 가벼운 모델을 사용하고자 BERT 모델을 distillation했고, 새롭게 학습 데이터셋을 구축했다.
 BERT 모델 학습 시 "token selection" 단계를 추가해 사용자 쿼리의 핵심적인 토큰에 집중할 수 있도록 했다.
BERT 모델 학습 시 "token selection" 단계를 추가해 사용자 쿼리의 핵심적인 토큰에 집중할 수 있도록 했다.
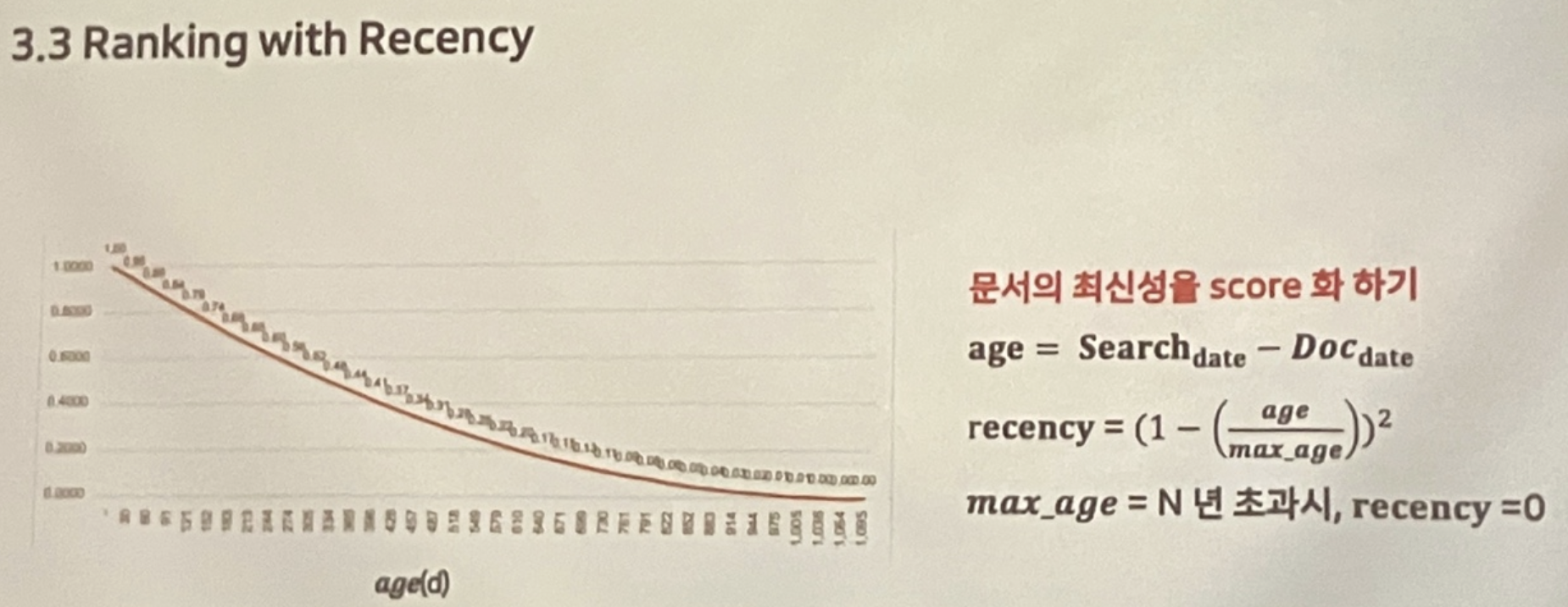 사용자 쿼리의 핵심적인 토큰에만 집중했더니 최신 문서를 잘 검색해오지 않아 문서의 최신성을 loss에 추가했다.
사용자 쿼리의 핵심적인 토큰에만 집중했더니 최신 문서를 잘 검색해오지 않아 문서의 최신성을 loss에 추가했다.
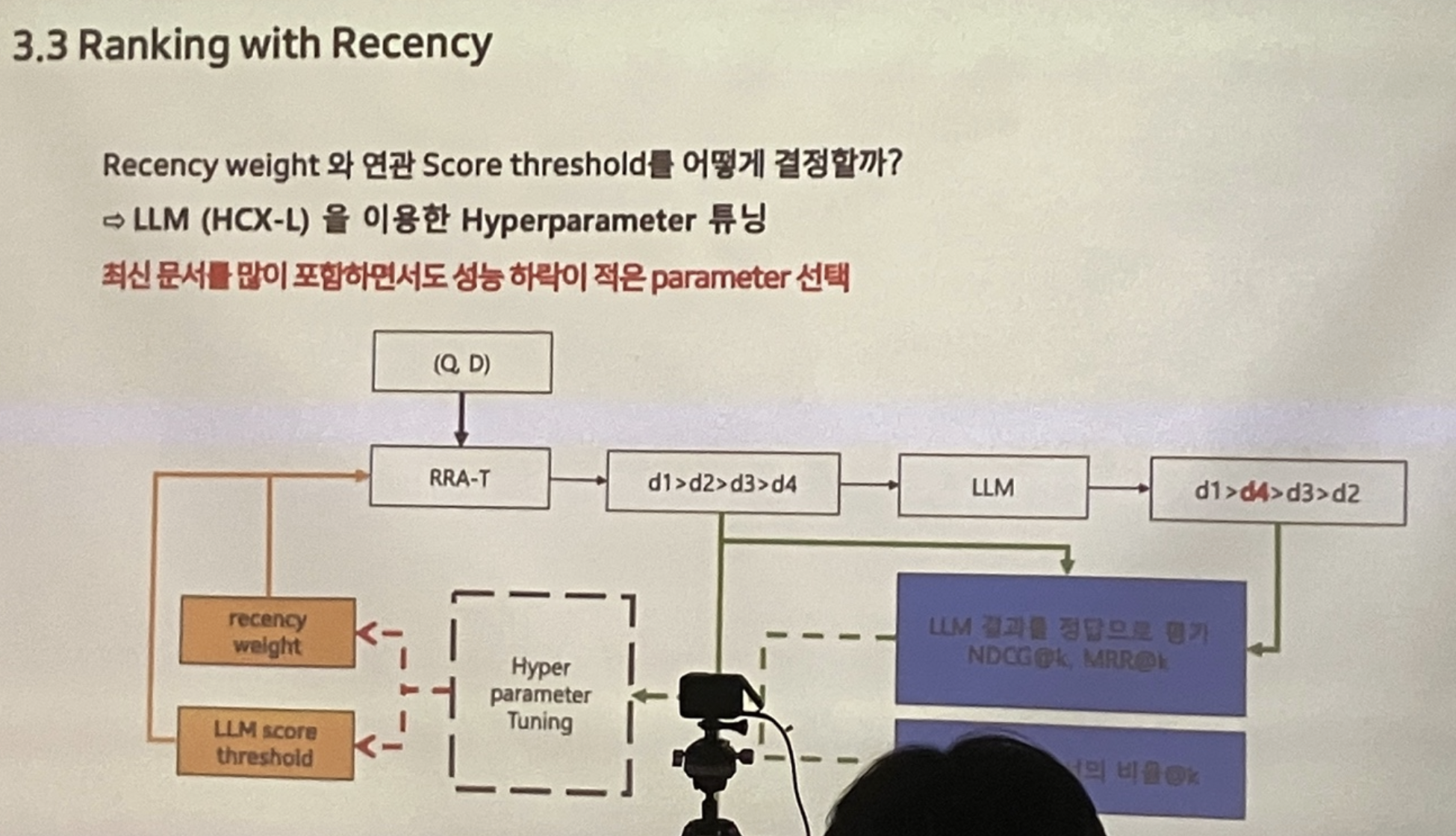 세션 후반부로 갈수록 집중력이 떨어져 사진이 많이 없습니다 ㅠㅠ 자세한 내용은 아래 네이버 컨퍼런스나 논문에서 확인하실 수 있습니다!
세션 후반부로 갈수록 집중력이 떨어져 사진이 많이 없습니다 ㅠㅠ 자세한 내용은 아래 네이버 컨퍼런스나 논문에서 확인하실 수 있습니다!
DAN 24
네이버 검색이 이렇게 좋아졌어? LLM의 Re-Ranking Ability 검색에 이식하기
EMNLP 2024
RRADistill: Distilling LLMs’ Passage Ranking Ability for Long-Tail Queries Document Re-Ranking on a Search Engine
4. 행사 후기
평일 저녁에 퇴근하고 밋업에 참여하는 사람들이 꽤 많았는데 학습 열의를 느낄 수 있었다.
행사 진행은 굉장히 원활했고 한 가지 아쉬운 점을 꼽자면 행사 후에 피자가 나와서 헝그리 정신으로 발표를 들었다.
첫 번째 세션은 이미지를 다루는 AI 팀에서는 어떤 일을 하는지 궁금했는데 대략적으로 알 수 있어서 좋았다.
두 번째 세션은 Weave 솔루션에 대한 내용이 가장 궁금했는데 해당 내용은 이전 밋업에서 다루어 이번에는 간단한 활용 예시만 다루어 아쉬웠다.
세 번째 세션은 LLM을 검색에 도입하기 위해 연관성, 속도 등 여러가지 고려할 사항과 이것들을 어떻게 풀어나갔는지 엿볼 수 있어 좋았다.
발표 시간에 비해 다루는 내용이 깊고 많아 궁금한 부분은 관련 자료를 읽어봐야겠다!
