
1. 프로젝트
지난주에 발표 영상과 발표 자료를 제출하고, 최종 프로젝트가 끝났다!!!!
우리 팀 주제는 “회의록을 활용한 질의응답(Question Answering)”으로 사용자가 회의록을 업로드하고, 궁금한 점을 질문하면, 답변해주는 서비스이다.
네이버에서 제공하는 클로바노트는 음성 기록 관리 서비스로, 모든 것을 받아적기 어려운 회의 내용을 저장하고 수월하게 복기할 수 있도록 도와준다. "이렇게 저장된 회의 데이터를 활용하는 서비스를 만들 수 있지 않을까?" 하는 생각으로부터 프로젝트를 시작했다.
초반에 브레인스토밍 했던 주제는 상품 이미지를 넣으면 마케팅 메시지를 생성해주는 것이었는데 상품 이미지-마케팅 메시지로 쌍을 이루는 데이터셋을 찾기 어려웠고, 마케팅 메시지의 종류가 우리가 생각한 텍스트와 달라서 막판에 주제를 완전 엎었다.
막판에 주제를 바꾸면서 실질적으로 프로젝트를 진행할 수 있는 시간은 3주였고 데이터, 모델, 서빙에 각각 1주일을 투자했고, 마지막 1주 동안에는 데모에서 발생한 에러들을 해결하고 멘토님의 피드백을 반영했다.
프로젝트 정리 링크
2. 마주한 어려움
2.1 한글 회의 데이터셋의 부재
데이터셋을 구하기 어려워 주제를 변경했기 때문에, 기존에 존재하는 데이터셋을 최대한 활용하고자 했다. 우리가 찾고자 한 것은 화자별로 발언이 분류된 일상적인 회의 대화 데이터였다.
1) 영어 데이터셋 활용
회의 종류별로 회의 내용과 요약이 담긴 QMSum 데이터셋이 존재했지만, 번역기를 사용해 한국어로 번역했을 때 조금씩 느낌이 달라서 정말 아쉽지만 영어 데이터셋은 사용할 수 없없다.
2) 직접 수집하기
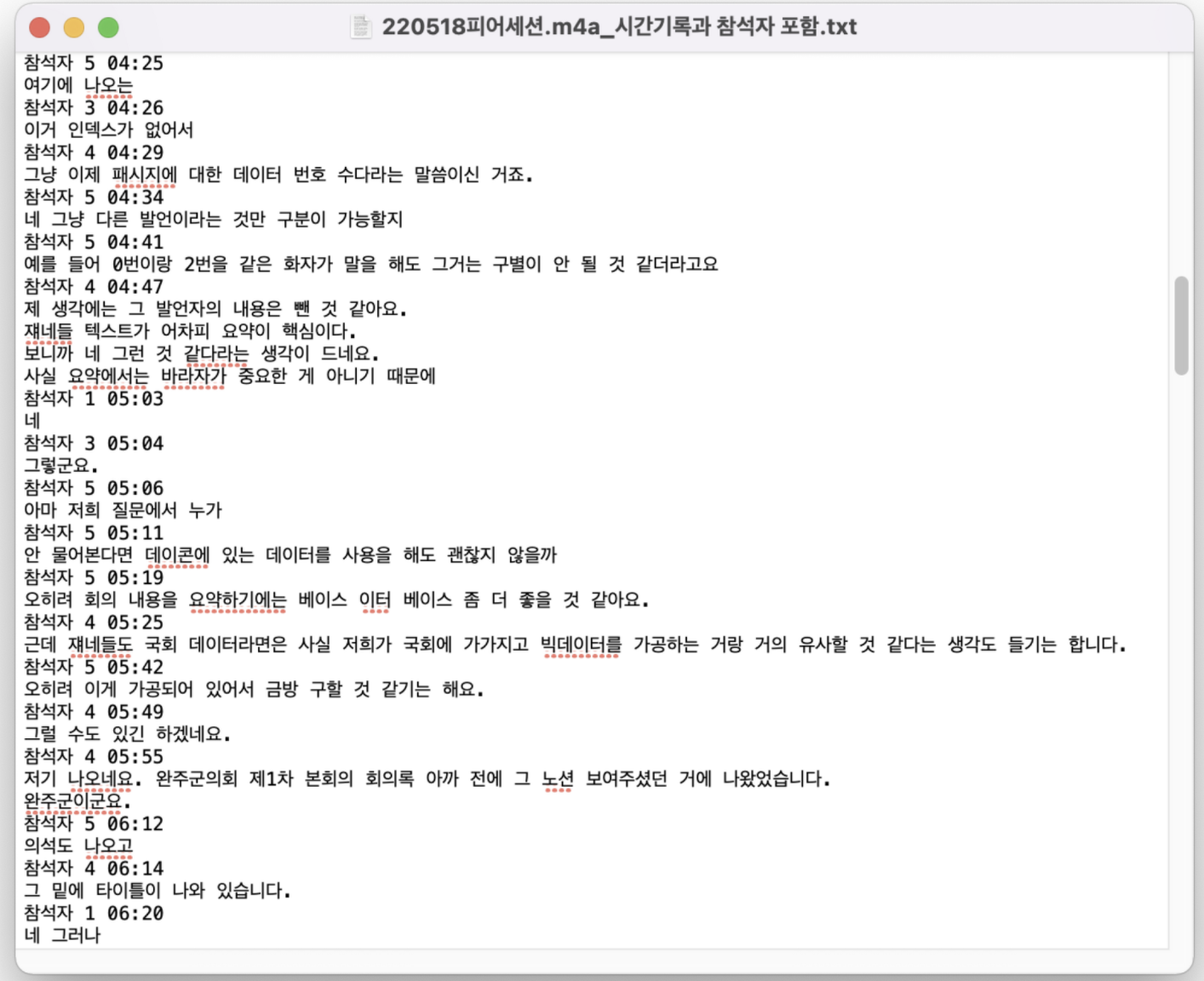
네이버 클로바노트로부터 아이디어를 얻었기 때문에, 데이터 수집에 클로바노트 활용을 시도했다. 매일 진행하는 데일리 스크럼 회의를 클로바노트로 녹음해 보았는데, 아래와 같이 각 화자별로 발언이 짧게 끊기는 모습이었다. 회의마다 각 문장의 길이가 달라지겠지만, 이렇게 짧은 문장에서는 정보를 추출하기에 어려움이 있다고 판단했다. 문장의 길이 뿐만 아니라, 클로바노트로 무료 버전 사용량 제한으로 인한 어려움도 있었다.
3) 기존 데이터셋 활용
클로바노트를 사용해본 후 데이터를 직접 수집하기에는 어려움이 있고, 시간이 오래 걸릴 것 같아 기존 데이터셋을 정제해 활용하는 방안을 모색했다. 데이콘의 AI 기반 회의 녹취록 요약 경진대회 데이터셋은 문서화된 회의 녹취록에서 핵심 내용을 생성 요약하는 AI 모델 개발을 위한 데이터셋이다. 의회 회의 내용으로 구성되어 안건별, 화자별로 발언이 나뉘어 있다.

의회 회의록이기 때문에 일반 회사의 회의에서 사용하는 어휘와 다른 문제점이 있었다. 의회 회의 데이터 중 실제 회의에 대응될 수도 있는 범용적인 질문을 유형화해 7가지 유형의 질문으로 구성된 QA 데이터셋을 제작했다.
2.2 그렇게 쓰는거 아니에요...
항상 주피터 노트북에서 모델을 학습시킨 후 성능 평가까지만 했었기 때문에 모델이 완성되면 데모도 금방 완성할 수 있다고 생각했다. 하지만 내가 예상한 순서대로 데모를 사용하지 않는 경우가 많아 내가 원하는 순서대로 사용자가 서비스를 사용하도록 유도하고 예외 처리하는데 시간을 쏟았다.
회의록 QA를 사용하기 위해서는 아래와 같은 과정이 필요하다.
1) 사용자 정보 입력
2) 회의록 업로드
3) QA 시작
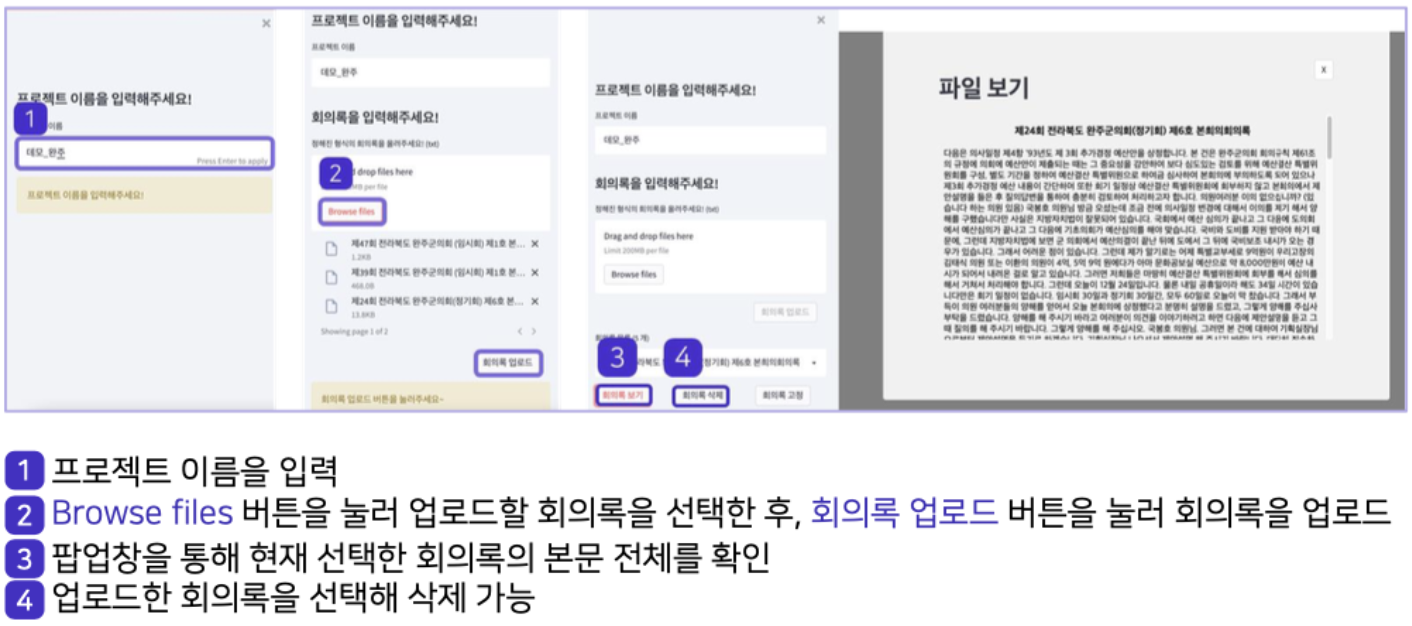
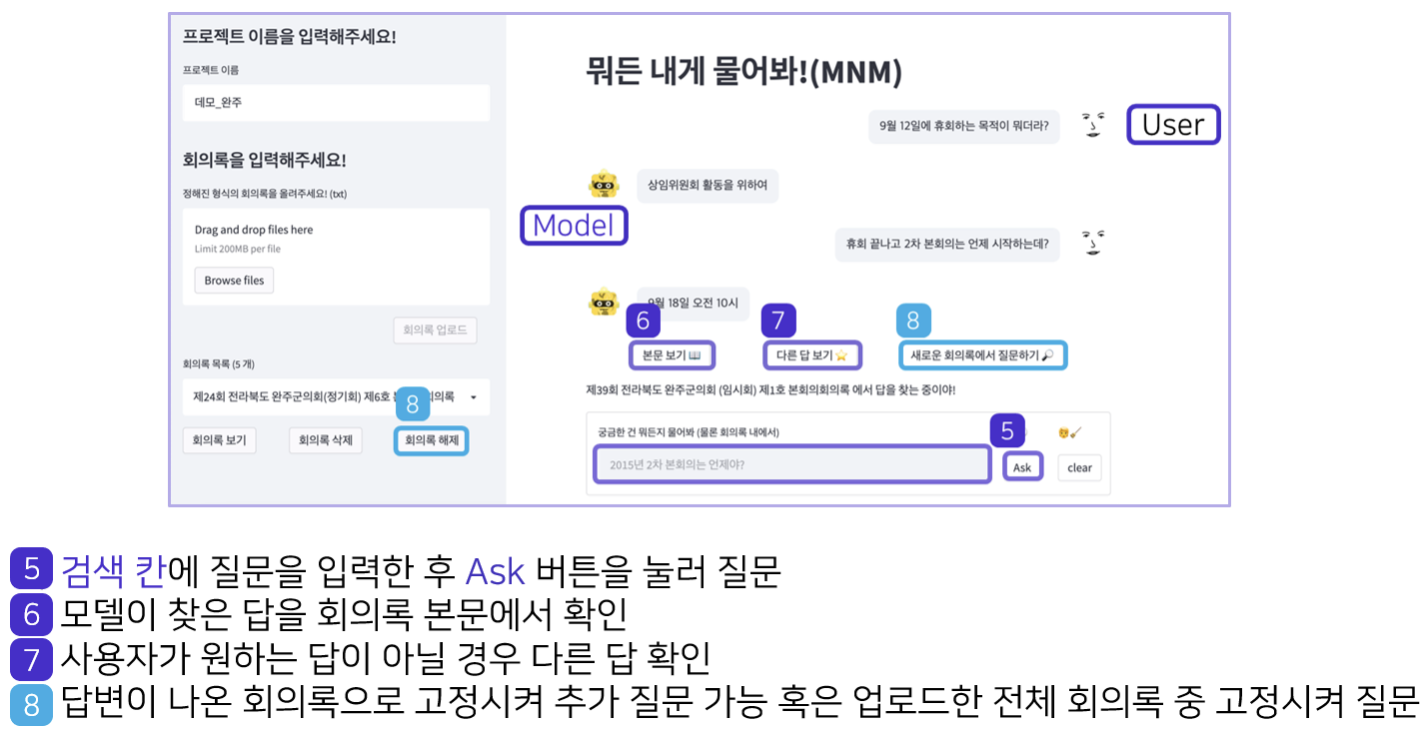
모델 개발 시에는 1, 2 단계는 완료되었다고 가정하고 3번을 바로 수행하기 때문에 데모를 만들 때 1, 2 단계를 고려해야 했다. 프로젝트의 와이어프레임은 아래 사진과 같은데 1, 2 단계를 수행하지 않고 3단계로 넘어가는 경우를 방지하고, 회의록이 변경되면 회의록 목록이 업데이트 되도록 했다.
3. 아쉬운 점
3.1 새로운 모델 시도
이전 MRC 대회와 유사한 task이기 때문에 기존에 사용하던 Reader, Retriever 모델에 큰 변화를 주지 않고 달라진 데이터셋에 대해 파라미터 튜닝만 했다.
Reader 모델에는 HuggingFace에서 제공하는 AutoModelForQuestionAnswering을 사용했다. KLUE 데이터셋으로 pre-trained된 모델을 구축한 QA 데이터셋으로 fine-tuning했다.
Retriever 모델에는 Elasticsearch 검색엔진을 사용했고, 새로운 데이터셋에 최적화된 파라미터를 찾는 실험을 진행했다. Elasticsearch는 키워드 중심으로 인덱싱해 검색을 수행하기 때문에, 키워드 검색이 아닌 케이스도 대응할 수 있도록 ColBERT와 같은 dense embedding을 시도해보고 싶다.
3.2 회의록은 QA가 아니라 요약이다
회의록 QA라는 주제로 프로젝트를 진행하면서 “회의를 요약해주는 기능도 있으면 좋겠다“ 라는 생각을 했지만, 부가 기능을 추가하기 보다는 기존에 정한 주제에 집중하고 모델의 성능을 높이고자 했다.
하지만, 회의록에서 궁금한 것들을 질문하는 QA의 목적은 결국 회의에서 어떤 내용을 주고받았는지 알기 위해서이다. 사용한 데이터셋이 회의록 요약 데이터셋인 이유를 프로젝트가 끝나고 나서야 깨달았다.
3.3 배포
streamlit을 사용해 데모를 구현하면 streamlit cloud를 사용하면 배포를 빠르게 진행할 수 있다. 마지막날 시도했지만 UI랑 Reader 부분은 성공했지만 Elasticsearch 서버를 배포하지 못해 실패했다. 이번 프로젝트는 streamlit으로 구현해서 CI/CD 부분까지 필요하지는 않았지만, 좀 더 효율적으로 모델을 배포하는 방법에 대해 공부해야겠다.
4. 느낀점
이번 프로젝트는 데이터-모델-서빙 모든 과정을 시간에 쫓기면서 진행했다는 느낌을 강하게 받았다. 시간에 쫓겨 진행하느라 모든 과정에서 조금씩 아쉬운 점이 있었지만, 선택과 집중을 통해(챙길건 챙기고, 버릴건 버려서) 기한 내에 완성할 수 있었다고 생각한다.
주제를 변경하게 되어 프로젝트를 진행할 시간이 짧았지만 탄력적으로 모든 과정을 함께 진행하고, 마지막까지 에러 수정하고, 발표 영상을 보완했던 팀원들에게 정말 감사하다.

