
세션
VLM, 눈 달린 LLM을 만나보자! (김대현)
-> 세션 소개 내용 보기
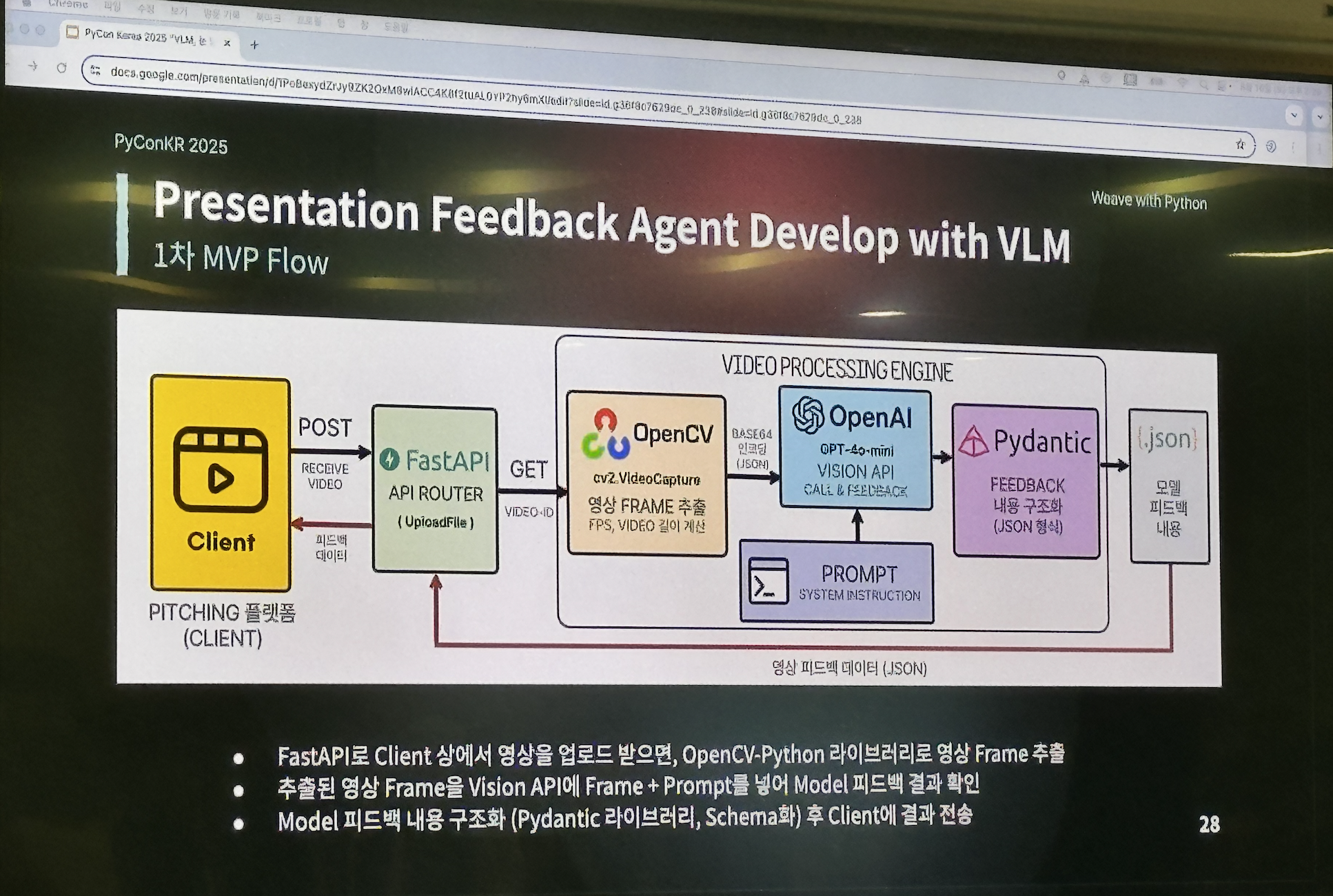
LLM과 비교하여 VLM의 작동 원리에 대한 설명과 VLM을 활용한 발표 영상 피드백 모델을 개발한 경험을 소개해주었다.
입력이 이미지이기 때문에 처음에는 CV 모델을 고려했으나, CV 모델은 판단만 하고 사용자에게는 어떤 피드백을 줘야할지 모르기 때문에 VLM을 사용했다. 행동에 대한 피드백을 사용자에게 텍스트로 제공하기 위해서이다.

VLM 모델이 이미지에서 정확한 정보를 추출하지 못하는 문제가 있어, GPU가 없어도 되는 구글의 mediapipe 라이브러리를 사용했다.
또한, 추론 시 너무 많은 프레임을 분석해 API 토큰 수가 초과하는 문제가 발생했다. 따라서 발표 영상에서 피드백을 해줄(문제가 되는) 행동들을 정의하고 임계치를 설정했다. 해당 임계값을 넘은 프레임만 문제가 있다고 판단해 LLM을 너무 자주 호출하지 않도록 했다.
LLM을 주제로 다룬 경우가 많은데 VLM을 발표 주제로 다루어주셔서 새로웠다.
파이썬과 생성형 AI를 활용한 합성 데이터 구축 파이프라인 개발 : 실무 LLMOps 가이드 (강정석, 송영숙)
-> 세션 소개 내용 보기


모델 성능을 높이기 위해 합성/증강 데이터를 만드는 방법이 흔하다. 하지만 이미지와 데이터와 비교해 자연어는 잘못하면 모델 학습이 되지 않거나 어색한 말을 생성해 합성 데이터를 만들기 쉽지 않다.
따라서 완전히 새로운 문장을 만드는 방식이 아닌 고쳐쓰기(rephrase) 방식을 사용해 합성 데이터와 데이터 파이프라인을 구축한 경험을 공유해주었다.

사내 기술 블로그 데이터를 사용해 어미에 유의하며 프롬프팅으로 증강했다.

지속적으로 고품질의 데이터를 만들기 위해 데이터 구축 뿐만 아니라 데이터 구축 파이프라인 만드는 것을 강조하셨고, 이를 위해 자사 제품인 Backend.AI 를 사용해 실험을 진행했다.


전체 파이프라인은 LLM 서빙-원본 데이터-합성 데이터 생성-합성 데이터 평가로 이루어졌다. 합성 데이터 평가 시에는 룰 기반, LLM 기반, 사람 기반 3가지 방식을 사용했다.
자연어 데이터 업계에서 유명한 송영숙님이 발표하셔서 개인적으로 기대되었던 세션이었고, 전에 직접 학습 데이터셋을 구축한 작업이 생각나 공감되는 부분이 많았다.
LLM 실험 및 평가에 자사 제품을 사용하고 실 사용자에게 피드백을 받으며 제품을 개선해나간 부분이 인상적이었다.
시간에 쫓겨 데이터를 구축하다 보면 이력 관리도 안되고, 한 번 학습에 쓰이고 버려지는 경우가 있는데 제품을 활용한 체계적인 실험이 부러웠다….
자비스, 내 서비스에 무슨 문제가 있는거야? 자연어 기반 운영 흐름과 MCP 개발기 (김민석)
-> 세션 소개 내용 보기

MCP의 개념과 대화형 서버 예제를 소개해주었다.
MCP(Model Context Protocol)는 LLM 애플리케이션과 외부 데이터 소스, 도구 간의 원활한 통합을 가능하도록 하는 프로토콜을 의미한다.
MCP는 prompts, resources, tools 3가지로 구성된다.
- Prompts: 재사용 가능하도록 구성
- Resources: context를 제공할 수 있는 외부 데이터, DB 등
- Tools: 실행 가능한 함수. 함수명, 파라미터, 입출력 타입 힌트, 주석에 따라 LLM이 툴을 선택하기 때문에 매우 중요함

MCP가 적절한 툴을 선택하는 과정은 클라이언트가 사용 가능한 툴 목록 조회 -> 의도 분석해 최적의 도구 선택 -> 선택한 도구 실행 및 결과 처리 순서로 이루어진다.
RAG 애플리케이션 개발을 위한 Chunking 최적화 (강성우)
-> 세션 소개 내용 보기
LLM의 기억 관리 책임은 모델이 아닌 인간에게 있다.
RNN이나 Mamba는 내재적 메모리 아키텍처를 통해 스스로 정보를 보존하지만, LLM은 매번 인간이 설계한 컨텍스트에 전적으로 의존한다.
LLM이 예전 대화를 기억하는 방법은 답변 추론 시 예전 대화 기록을 모두 입력으로 활용하기 때문이다. 즉, 사람이 입력한 context를 그대로 활용한다. 이 때 모델은 context length 한계가 있기 때문에 문서를 일정 길이로 잘라(chunking) 입력에 사용한다.

여러 가지 chunking 전략을 소개해주었다.
1. Recursive Chunking
- 구분자별로 우선순위가 있어 우선순위가 높은 구분자를 기준으로 분할(split)해 설정한 크기보다 작게 만드는 방식이다.
- 예를 들어 context_length=100일 때 우선순위가 가장 높은 개행 문자를 기준으로 자르고, 100을 초과한다면 다음 구분자로 나누고를 반복한다.

- Semantic Chunking
- 임베딩을 사용해 각 chunk의 이미를 추출하고, 의미 유사도가 비슷하면 다시 병합하는 방식이다.
- MoC(Mixture-of-chunks)
- LLM이 chunk를 어떻게 나누면 좋을지 결정하는 방법인데, 학술적으로 재미있지만 API 추론 비용이 많이 드는 방식이다.
청킹 시 유의해야할 점도 공유해주었다.
- 청크 크기와 검색 성능은 서로 trade-off 관계: 청크가 너무 작으면 문맥을 파악하는데 필요한 정보가 적고, 크기가 너무 크면 검색 성능이 약해진다.
- 청킹 고도화 및 최적화 기법: 현실적으로는 청킹 알고리즘을 복잡하게 가져가지 말고, 청킹한 결과를 사후 보완하자. 각 문서의 파일명과 같은 메타 데이터를 활용하거나, 각 청크가 문서에서 어떤 부분에 위치하고 무엇에 관한 설명인지를 추가해 임베딩하는 context retrieval 방법이 있다.
- 성능 평가: llm-as-judge를 사용해 답변 생성하는 LLM은 고정해두고 청킹 방법을 바꿔가며 진행했다.
부스

첫날은 오후부터 참여해서 세션 위주로 듣다 보니 부스를 많이 돌아다니지는 못했다. 그래도 도서 증정 이벤트에 당첨되어서 딱 원하던 책을 받을 수 있었다! 이제 읽기만 하면 된다 ㅎㅎ
첫 날 행사 이후에는 자원봉사자, 파준위, 연사자분들이랑 다 같이 저녁을 먹었다. 식당이 꽤 컸는데도 한 번에 다 못 들어갈 정도로 사람이 많았다. 아침부터 긴장하면서 일해서 그런지 다들 피곤해 보였지만, 하루를 무사히 마쳤다는 안도감 덕분에 분위기가 좋았다. 일 얘기 말고도 이런저런 얘기를 하면서 친해질 수 있어서 즐거웠다.
