VLA 논문 리뷰
1. [Paper Review] RT-1: ROBOTICS TRANSFORMER FOR REAL-WORLD CONTROL AT SCALE
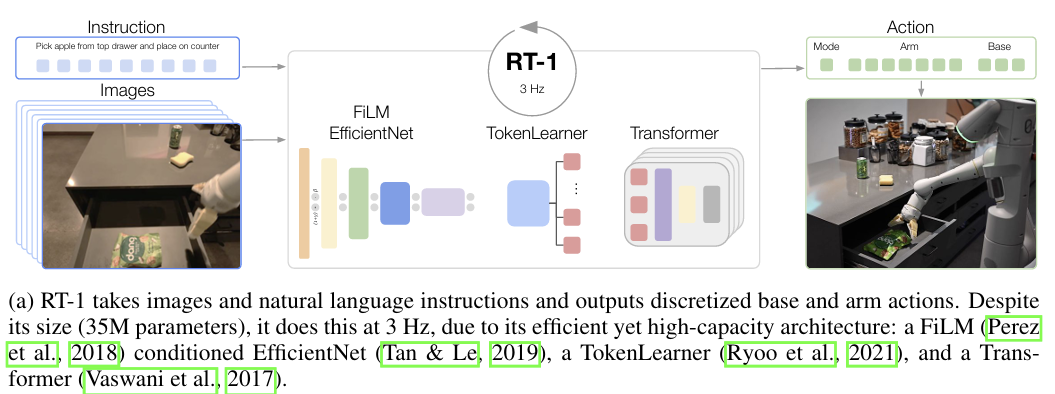
[ Abstract ] 대규모, 다양한, 특정 Task에 얽매이지 않은 데이터셋으로부터 transferring knowledge을 함으로써, 모델은 특정 Task를 추가 데이터 없이 바로 수행하거나 소량의 과제별 데이터셋만으로도 높은 성능을 발휘할 수 있다. 이러한
2.[Paper Review] RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
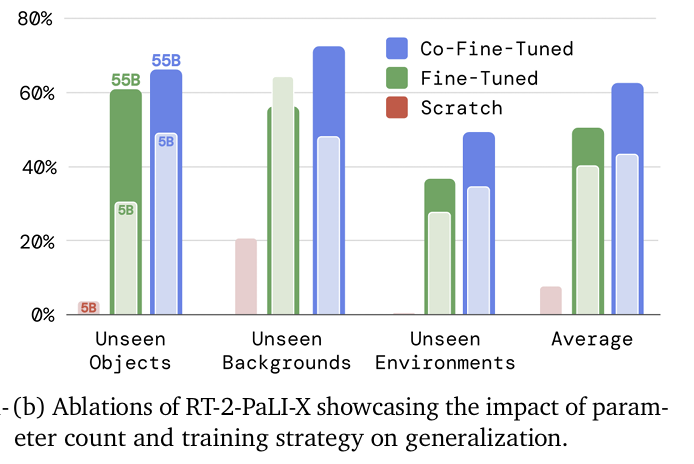
https://arxiv.org/pdf/2307.15818 [ Abstract ] 본 연구는 하나의 모델이 로봇의 관찰 데이터를 Action으로 변환하는 학습을 할 수 있을 뿐만 아니라, 인터넷 규모의 Language와 Vision-Language 데이터를 통한 사
3.[Paper Review] Open X-Embodiment: Robotic Learning Datasets and RT-X Models
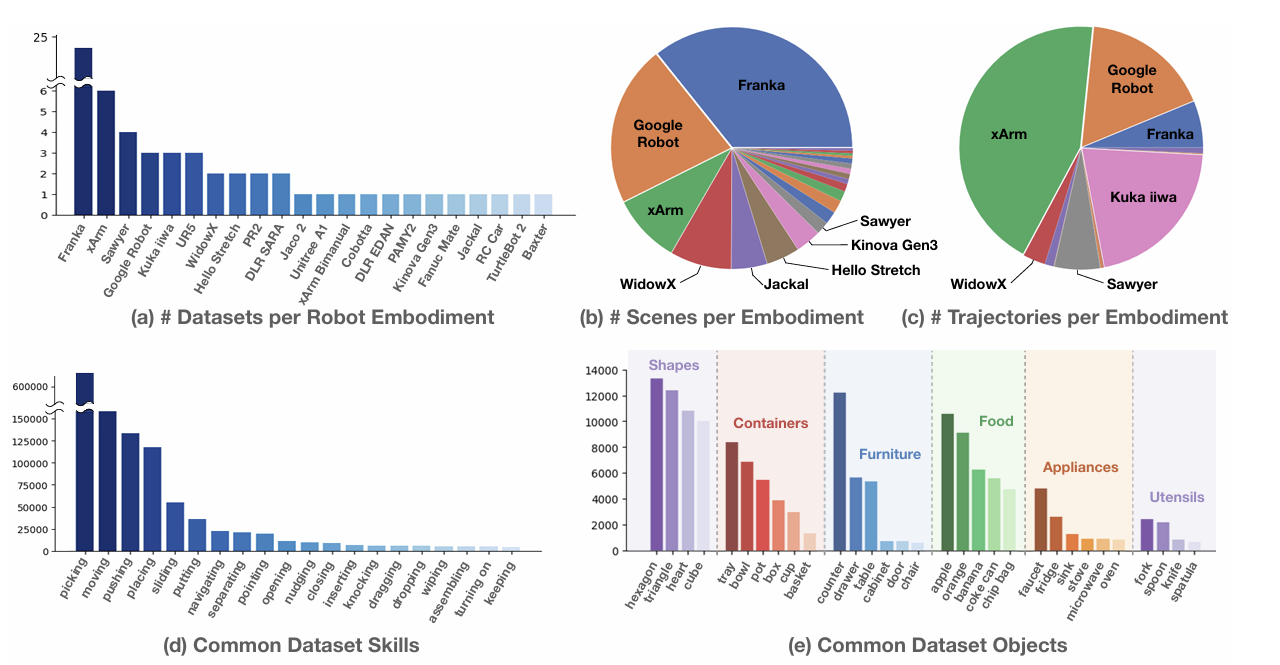
https://arxiv.org/pdf/2310.08864다양한 데이터셋으로 학습된 Large, high-capacity 모델들은 세분화된 다양한 분야의 Task를 해결하는 데 있어서 높은 성과를 보여주고 있다. 본 논문에서는 로봇 Manipulation의 맥
4.[Paper Review] OpenVLA: AnOpen-Source Vision-Language-Action Model
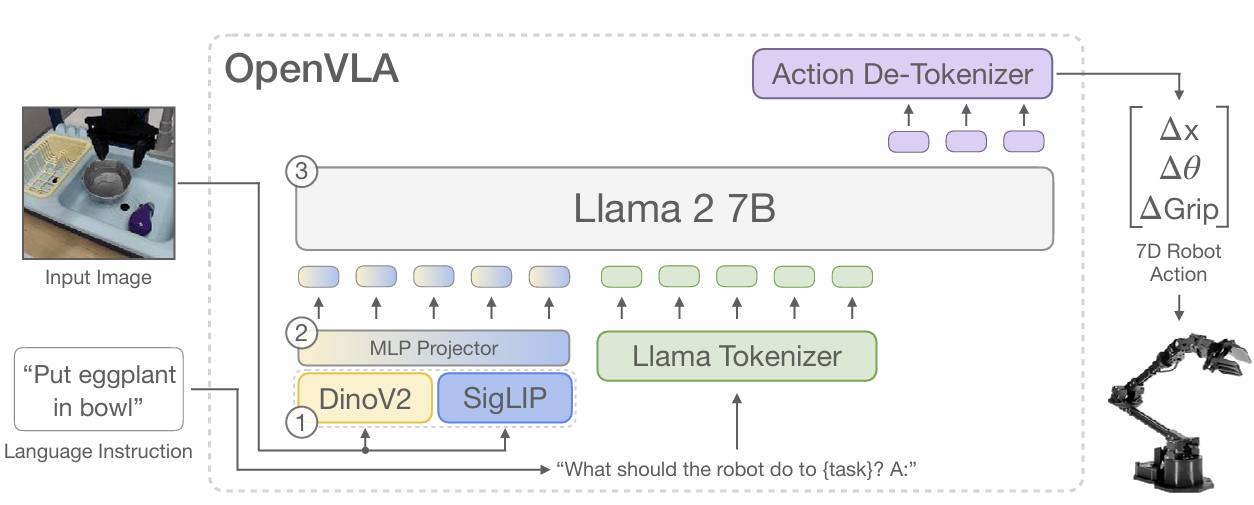
https://arxiv.org/pdf/2406.09246Internet-scale의 VLM(비전-언어) 데이터와 다양한 로봇 데이터를 결합하여 Pretrained된 대규모 Policies은 로봇에게 새로운 기술을 가르치는 방식을 변화시킬 잠재력을 가지고 있다
5.[ Paper Review ] 3D-VLA: A 3DVision-Language-Action Generative World Model

https://arxiv.org/pdf/2403.09631최근 VLA 모델은 2D 입력에 의존하며, 3D 세계(현실 세계)와의 통합이 부족하다. 또한, 이러한 모델은 지각에서 행동으로의 직접적인 매핑을 학습하여 행동을 예측하는데, 광범위한 역학 + 행동과 역학